


Apache SeaTunnel:新一代开源、高性能数据集成工具

Apache SeaTunnel 是一款开源、分布式、高性能的数据集成工具,可以通过配置快速搭建数据管道,支持实时海量数据同步。
Apache SeaTunnel 专注于数据集成和数据同步,主要旨在解决数据集成领域的常见问题:
- 数据源多样性:常用数据源有数百种,版本不兼容。 随着新技术的出现,更多的数据源不断出现。用户很难找到一个能够全面、快速支持这些数据源的工具。
- 同步场景复杂:数据同步需要支持离线全量同步、离线增量同步、CDC、实时同步、全库同步等多种同步场景。
- 资源需求量高:现有的数据集成和数据同步工具往往需要大量的计算资源或 JDBC 连接资源来完成海量小表的实时同步。 这增加了企业的负担。
- 缺乏质量监控:数据集成和同步过程经常会出现数据丢失或重复的情况。 同步过程缺乏监控,无法直观了解任务过程中数据的真实情况。
- 技术栈复杂性:企业使用的技术组件不同,用户需要针对不同组件开发相应的同步程序来完成数据集成。
- 管理维护困难:受限于底层技术组件(Flink/Spark)不同,离线同步和实时同步往往需要分开开发和管理,增加了管理和维护的难度。
目前已有上百家公司和组织将 Apache SeaTunnel 用于研究、生产和商业产品。
系统架构
Apache SeaTunnel 的运行流程如下图所示。
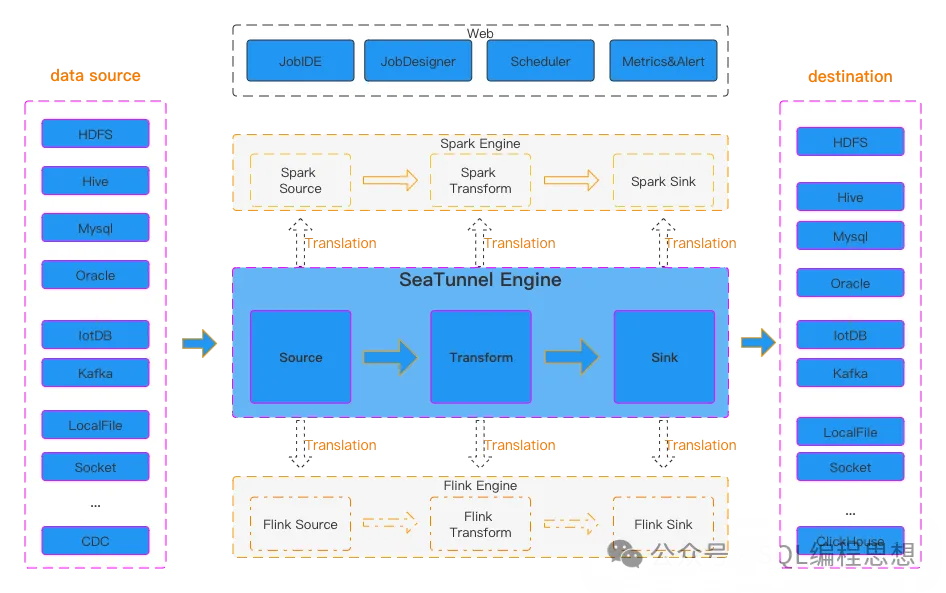
用户配置作业信息并选择提交作业的执行引擎,然后输入连接器(Source Connector)负责并行读取数据并将数据发送到下游的转换连接器(Transform)或直接发送到输出连接器(Sink),Sink 负责将数据写入目标。 三种连接器都可以支持用户自定义开发和扩展。
Apache SeaTunnel 是一个 EL(T) 数据集成平台。 因此,转换连接器只能用于对数据进行一些简单的转换,例如将一列的数据转换为大写或小写,更改列名,或者将一列拆分为多列。
Apache SeaTunnel 使用的默认引擎是 SeaTunnel Engine; 如果使用 Flink 或者 Spark 引擎,它会将连接器打包成 Flink 或者 Spark 程序并提交给相应的引擎运行。
数据源
Apache SeaTunnel 目前已经能够支持上百个数据源,包括各种关系数据库、图数据库、NoSQL、文档和内存数据库、分布式文件系统(例如 HDFS)以及各种云存储解决方案(例如 S3 以及 OSS)。同时还支持很多常见 SaaS 服务的数据读写,用户也可以开发自己的连接器。

功能特性
Apache SeaTunnel 不同于其他数据集成平台的功能特性如下:
- 多引擎支持,提供了不依赖于特定执行引擎的 Connector API,基于该 API 开发的三种连接器(Source、Transform、Sink)可以运行在不同的引擎之上,例如 SeaTunnel Engine、Flink、Spark 等。
- 插件式连接器,插件式设计让用户可以轻松开发自己的 Connector 并将其集成到 Apache SeaTunnel 项目中。目前已经支持超过 100 个连接器,并且数量正在激增。
- 批流一体,完美兼容离线同步、实时同步、全量同步、增量同步等场景,大大降低了管理数据集成任务的难度。
- 支持分布式快照算法,保证数据一致性。
- 支持多表或全库同步,解决了过度 JDBC 连接的问题;支持多表或全库日志读取解析,解决了CDC多表同步场景下需要处理日志重复读取解析的问题。
- 高吞吐量、低延迟,持并行读写,提供稳定可靠、高吞吐量、低延迟的数据同步能力。
- 完善的实时监控,支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS 等信息。
- 支持两种作业开发方法:可视化开发以及代码开发。
- SeaTunnel Web 项目提供作业、调度、运行和监控功能的可视化管理。
安装体验
Apache SeaTunnel 支持本地安装、Docker 以及 K8S 部署方式,使用非常方便。例如,使用 Docker 启用本地模式的命令如下:
docker pull apache/seatunnel:目前最新的版本为 2.3.10。当下载完成后,可以使用如下命令来提交任务:
# 运行作业,从虚拟数据源到Console输出
docker run --rm -it apache/seatunnel: ./bin/seatunnel.sh -m local -c config/v2.batch.config.template
# 使用配置文件运行作业,/tmp/job/fake_to_console.conf
docker run --rm -it -v /tmp/job/:/config apache/seatunnel: ./bin/seatunnel.sh -m local -c /config/fake_to_console.conf
# 运行时设置JVM参数
docker run --rm -it -v /tmp/job/:/config apache/seatunnel: ./bin/seatunnel.sh -DJvmOption="-Xms4G -Xmx4G" -m local -c /config/fake_to_console.conf Apache SeaTunnel 官方网站提供了中文文档,建议直接阅读。
https://seatunnel.apache.org/zh-CN/docs/2.3.10/about/









