


删除大量数据后,数据库文件为何纹丝不动?MySQL 存储机制大揭秘
一、问题背景
“删了90%数据,数据库文件为啥纹丝不动?这是MySQL的bug吗?”
上周一位读者面试被问懵了,这个问题也戳中了很多人的痛点——明明删了大把数据,硬盘空间死活不释放!
你是不是也遇到过:
- 执行DELETE后,磁盘空间未释放
- .ibd文件大小不变,运维报警频发
- 明明数据量减少,统计信息却 “岿然不动”
别慌,这真不是Bug! 而是 InnoDB 存储引擎的底层设计机制决定的。今天就来扒开 InnoDB 的底层逻辑,教你 3 招驯服 “顽固” 的数据库文件。

二、删数据≠丢空间:MySQL 的 “假删除” 套路
先看一组颠覆认知的实验:
Step 1:创建 200 万条数据的表
-- 创建测试数据库
CREATEDATABASEtest;
-- 创建测试表
CREATETABLE test_demo (
idINT PRIMARY KEY AUTO_INCREMENT,
nameVARCHAR(100),
contentTEXT,
create_time DATETIME
) ENGINE=InnoDB;插入测试数据:
-- 插入200万条测试数据
DELIMITER //
CREATEPROCEDURE insert_test_data()
BEGIN
DECLARE i INTDEFAULT1;
WHILE i <= 2000000 DO
INSERTINTO test_demo (name, content, create_time)
VALUES (
CONCAT('name_', i),
REPEAT('x', 1000), -- 每条记录约1KB
NOW()
);
SET i = i + 1;
ENDWHILE;
END //
DELIMITER ;
-- 执行存储过程
CALL insert_test_data();Step 2:查看初始文件大小(约 1GB)
-- 查看表空间文件大小
SELECT
table_name,
data_length/1024/1024 as data_size_mb,
index_length/1024/1024 as index_size_mb
FROM information_schema.tables
WHERE table_schema = 'test'
AND table_name = 'test_demo';
Step 3:删除 99% 数据(仅保留前 100 条)
-- 删除id大于100的记录
DELETE FROM test_demo WHERE id >100;Step 4:查看文件大小
- .ibd文件物理大小仍≈1GB(磁盘未释放)
- SELECT COUNT(*)返回 100 条(逻辑数据正确)

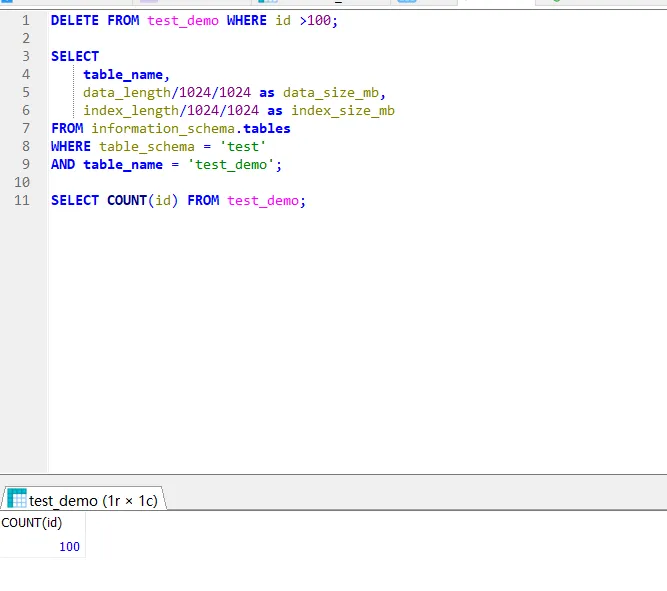
灵魂拷问:删了 190 万条数据,为啥空间没释放?
三、InnoDB 存储的 3 个 “反直觉” 设计
1. 数据页:最小存储单位的 “空间垄断”
- 每个数据页固定 16KB,相当于图书馆的书架格子
- 删除 1 条记录(可能只有 KB 级),不会释放整个数据页(16KB)
- 页内空洞累积,导致文件 “虚胖”
InnoDB 数据页的内部结构:
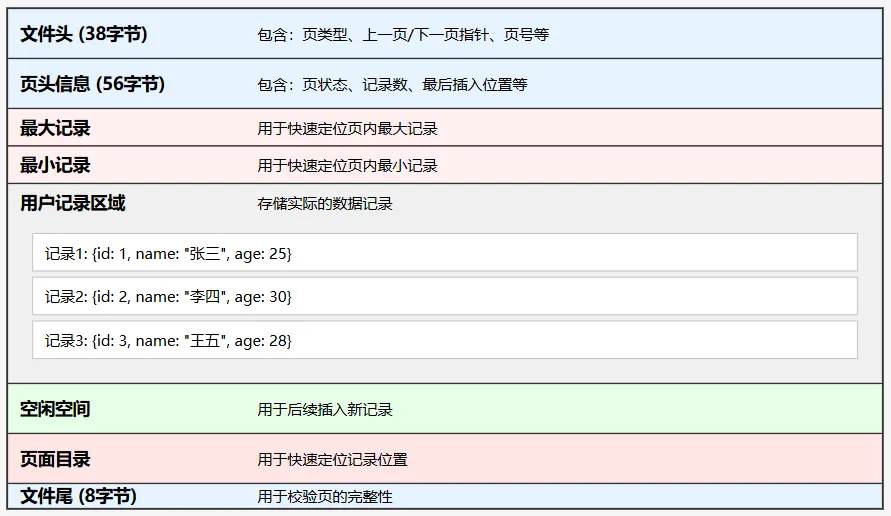
(1) 记录在页中的存储
还记得之前我们介绍的InnoDB 记录结构吗?
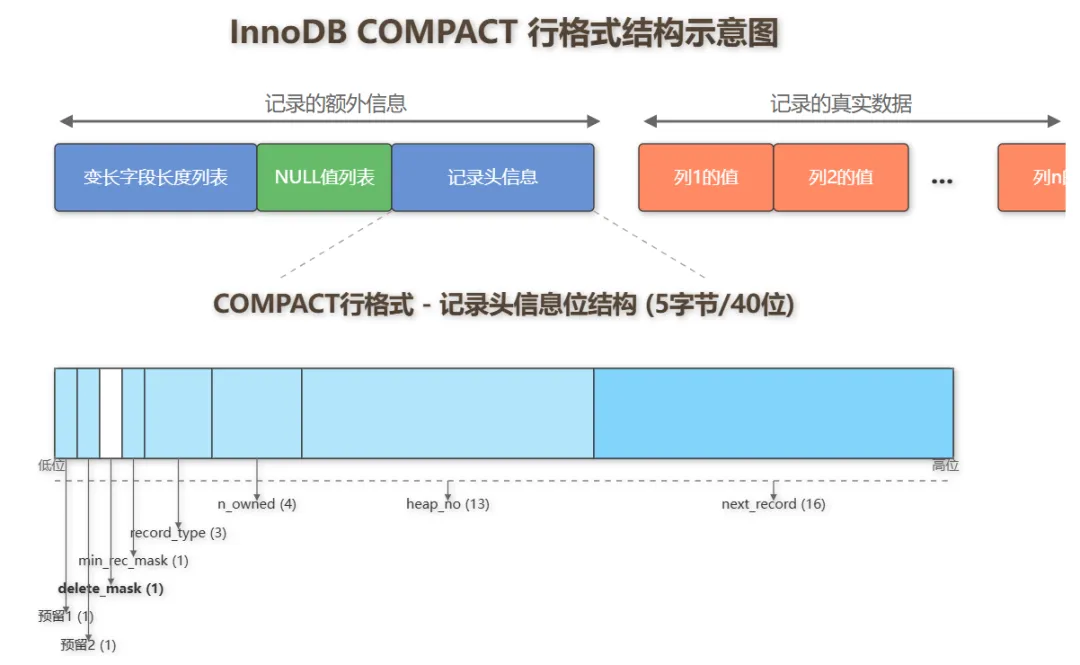
从图中我们可以看到,InnoDB 的 COMPACT 行格式确实分为两个主要部分:
- 记录的额外信息
- 记录的真实数据
关于删除的秘密其实藏在记录头信息中。
2. DELETE 的本质:标记删除而非物理删除
操作 | 本质行为 | 空间释放 |
| 将记录头信息中的 | ❌ 不释放 |
| 清空所有数据页,重建表空间 | ✅ 释放 |
为什么不直接物理删除?
事务安全优先:宁肯占空间,不能丢数据。
- 若物理删除数据,事务回滚时无法恢复(违反 ACID)
- 标记删除是 “软删除”,数据页可随时恢复(通过 undo 日志)
- 这就是为什么ROLLBACK能秒级恢复数据 —— 因为数据根本没被物理删除
空间复用 vs 碎片累积
- 标记删除的记录:数据页空间被标记为“空洞”,新数据可覆盖写入(空间复用)。
- 碎片累积:频繁增删后,数据页内空洞增多,导致.ibd文件“虚胖”(实际数据量小,但文件占用大)。
3. 预分配策略:空间只增不减的 “霸道总裁”
- InnoDB 按innodb_autoextend_increment(默认 64MB)自动扩展表空间
- 扩展后即使数据删除,空间也不会还给系统(文件系统不支持收缩)
- 就像买房时买了 120㎡,住了 50㎡后想退 70㎡—— 不可能
四、实战攻略:三招让数据库 “瘦身成功”
场景 | 方案 | 命令 | 原理 | 注意事项 |
紧急清空全表(数据可丢) |
|
| 销毁并重建表空间,释放所有空间 | 不可逆,适用于日志表等场景 |
重建表清理碎片(可停机) |
|
| 重建表空间,回收空洞和碎片 | 锁表,大表需在低峰期操作 |
分区表删除(历史数据归档) | 分区删除 |
| 删除指定分区,释放对应空间 | 需提前设计分区策略 |
我们看下执行后的效果:
ALTER TABLE test_demo ENGINE=INNODB;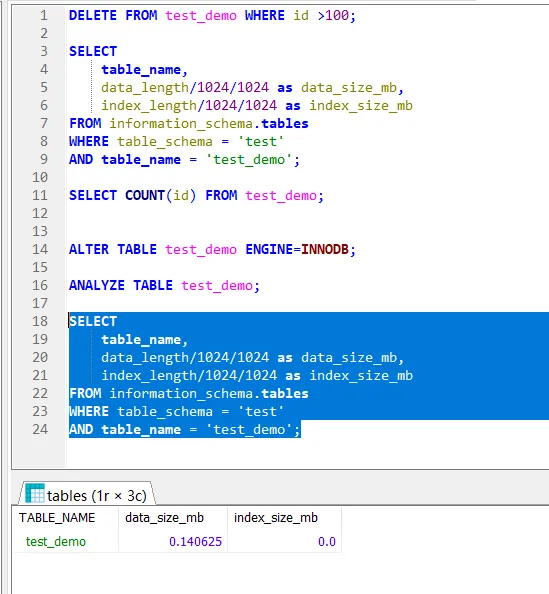
五、总结
- 本质原因:DELETE是逻辑删除,空间释放需依赖重建表或分区操作。
- 核心认知:MySQL优先保证事务安全和性能,而非实时回收空间。
- 面试要点:需清晰区分“标记删除”与“物理删除”,并能结合业务场景选择合适的空间释放方案。
通过理解InnoDB存储机制,合理运用定期监控碎片率、分区表,可有效避免删除数据后表文件“虚胖”问题,提升数据库存储效率。









