


面试官灵魂拷问:MySQL 事务隔离与 MVCC,你真的懂吗?
一、你是否也有这些痛点?
面试官:小徐,你在项目里用过事务吗?
小徐:用过啊,Spring的@Transactional用得很熟。
面试官:那你能说说MySQL的事务隔离级别和MVCC吗?它们是怎么保证数据一致性的?
小徐:……(沉默)
是不是很熟悉? 你是不是也遇到过这些场景:
- 明明加了事务,数据还是被“脏读”了?
- 事务隔离级别一堆名词,读未提交、可重复读、幻读,傻傻分不清楚?
- 面试官一问MVCC,脑子里只剩下“多版本并发控制”这几个字?
别急,今天我们就用一场“灵魂拷问式”对话,把事务的隔离级别和MVCC讲明白,彻底搞懂它们的底层原理和实际应用!

二、问题1:事务是什么?
面试官:小徐,你先说说,事务是什么?
我:事务是一组操作,要么都成功,要么都失败,用来保证数据的一致性。
面试官点点头,又问:那事务的四大特性你还记得吗?
我:当然。
- 原子性(Atomicity):事务中的操作要么全部成功,要么全部失败。
- 一致性(Consistency):事务执行前后,数据都必须保持一致。
- 隔离性(Isolation):并发事务之间互不干扰。
- 持久性(Durability):事务提交后,结果永久保留。
面试官满意地点头:那我们就重点聊聊“隔离性”。你能说说MySQL支持的事务隔离级别吗?分别会出现哪些并发问题?
三、问题2:什么是事务的隔离级别?
我:隔离性听起来简单:别人操作数据库的时候我别看到就行了。
但真要实现“互不干扰”,成本非常高。所以数据库给了我们四个等级的隔离级别,让我们按需选择:
隔离级别 | 脏读 | 不可重复读 | 幻读 |
读未提交(RU) | √ | √ | √ |
读已提交(RC) | × | √ | √ |
可重复读(RR) | × | × | √ |
串行化(SERIAL) | × | × | × |
面试官:你说说,什么是脏读、不可重复读和幻读?
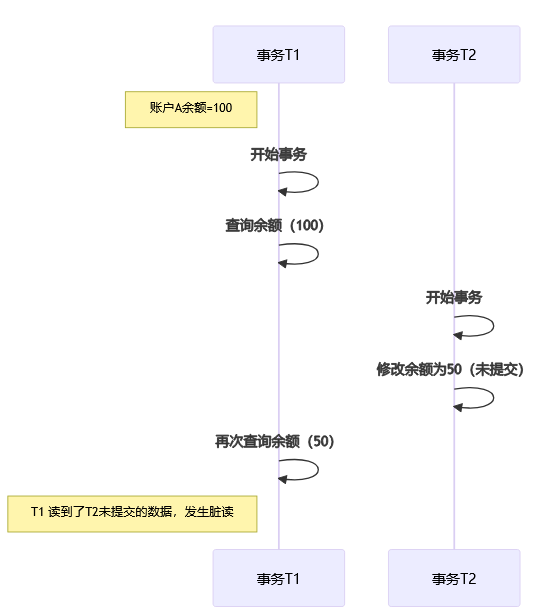
我:假设银行有个账户A,余额是100元。
脏读(Dirty Read):读到了别人还没提交的数据。
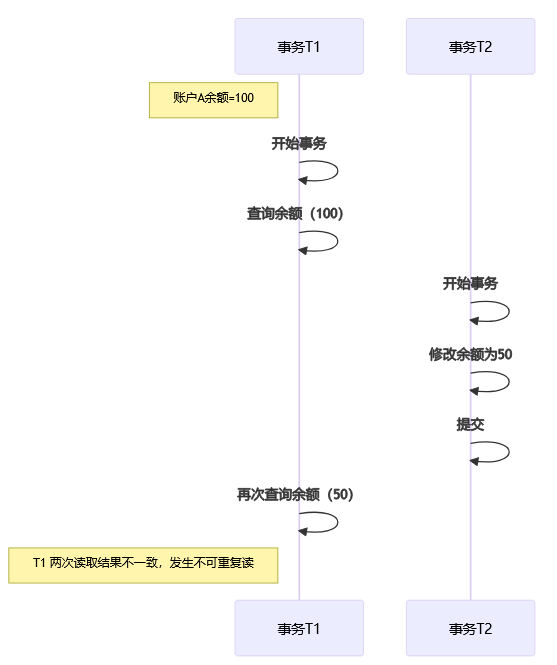
不可重复读(Non-repeatable Read):两次读取结果不一致,就是不可重复读。
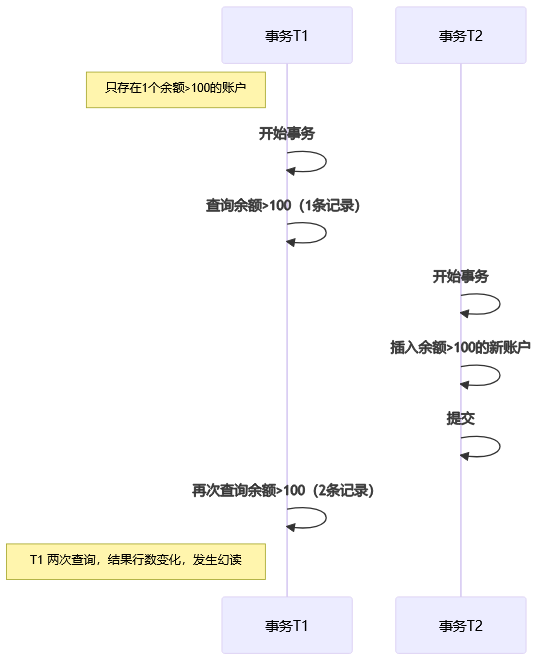
幻读(Phantom Read):T1觉得自己出现“幻觉”了,明明查过只有1条,怎么又冒出一条?这就叫幻读。
面试官:MySQL 默认是什么隔离级别?
我:MySQL 默认是 Repeatable Read(可重复读)隔离级别。
面试官:那你知道,MySQL 的隔离级别到底是通过什么实现的吗?
我:MySQL 的隔离级别,主要是通过两大机制来实现的:
- 一是锁机制
- 二是 MVCC(多版本并发控制)。
面试官:不错,能具体说说,什么是MVCC吗?
四、问题3:MVCC 到底是怎么一回事?
我:MVCC,全称 Multi-Version Concurrency Control,多版本并发控制。
通俗讲:每次读操作,都能读到一个“历史快照”,就像你拍了张数据的照片,别人改不影响你。
面试官:那MVCC的原理是什么?它是怎么做到让每个事务看到自己的快照的?
1. MVCC实现原理
我:MVCC的实现主要依赖于以下几个关键点:
(1) 隐藏字段:每一行数据在InnoDB存储引擎下,都会有两个隐藏字段:
- 创建版本号(DB_TRX_ID):记录插入或最后一次修改该行的事务ID。
- 删除版本号(DB_ROLL_PTR):记录删除该行的事务ID(如果没被删除则为NULL)。
(2) Undo Log(回滚日志)
- 当数据被修改(UPDATE/DELETE)时,InnoDB会把旧版本的数据写入Undo Log。
- 这样,其他事务如果需要读取历史版本的数据,就可以通过Undo Log“回溯”到对应的快照。
(3) Read View(可见性视图)
- 每个事务在启动时,会生成一个Read View,记录当前活跃的事务ID列表。
- 事务只能“看到”在自己启动前已经提交的数据版本。
(4) 快照读与当前读
- 快照读(Snapshot Read):普通的SELECT语句,走MVCC,不加锁。
- 当前读(Current Read):带有锁的操作(如SELECT ... FOR UPDATE、UPDATE、DELETE),需要读取最新版本并加锁。
2. MVCC的工作流程
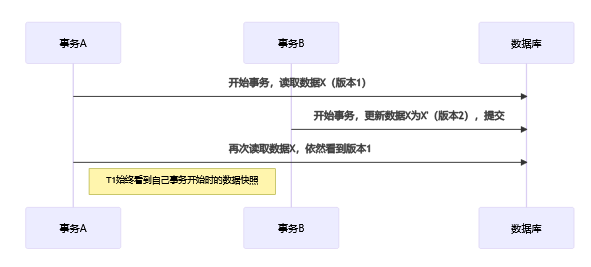
我们通过一个例子解释下:
(1) 事务A开始,生成快照
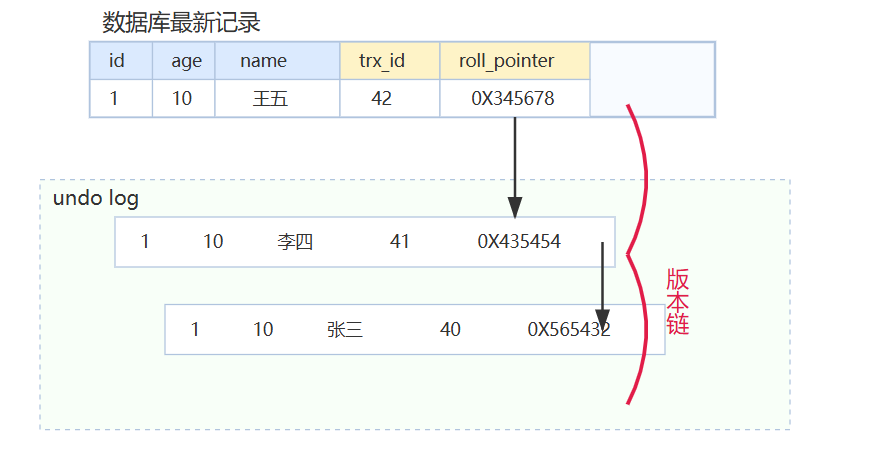
事务A启动,记录当前数据的快照(此时name=张三,age=10)。
(2) 事务B启动,把name从“张三”改为“李四”。
数据库不会直接覆盖原数据,而是把原来的数据(张三)写入undo log,生成一个新版本(李四),并更新事务ID和roll_pointer。
(3) 事务B未提交时,事务A读取数据
- 事务A此时去读这条数据,发现有新版本(李四,10),但这个版本的事务ID比A大,且还没提交。
- 根据MVCC规则,A不能看到B未提交的修改。
- 于是A会通过roll_pointer去undo log里找历史版本,找到自己快照时的数据(张三,10),返回给A。
(4) 事务B提交:事务B提交后,新的数据版本(李四)正式生效。
(5) 事务C启动时,快照中已经包含了B的提交。此时C读取数据,看到的就是最新的(李四,10)。
面试官:MVCC能解决所有并发问题吗?幻读怎么处理?
五、问题4:MVCC能解决所有并发问题吗?
我:MVCC不能解决所有并发问题。它主要解决了“脏读”、“不可重复读”等问题,让读写操作互不阻塞,提高了并发性能。但MVCC无法解决“幻读”问题。
MVCC适用的隔离级别:
- 读已提交(RC)和可重复读(RR):都用MVCC实现快照读。
- 读未提交(RU):不走MVCC,直接读最新数据。
- 串行化(SERIALIZABLE):加锁,性能最差。
面试官点头:那MySQL怎么避免幻读?
我:MVCC本身无法彻底解决幻读,因为MVCC只保证了“行级”的多版本,并不能控制“新行的出现或消失”。
在MySQL InnoDB中,解决幻读主要依赖于“间隙锁(Gap Lock)”:
- 在可重复读(REPEATABLE READ)隔离级别下,InnoDB会在范围查询时加上间隙锁,防止其他事务在查询范围内插入新行,从而避免幻读。
- 如果是读已提交(READ COMMITTED),则不会加间隙锁,幻读依然可能发生。
面试官:Perfect!看来你对MVCC了解的很深入了,下周就来公司报道吧。
六、总结
所谓的 MVCC,指的是在 READ COMMITTED 和 REPEATABLE READ 这两种隔离级别下,事务在执行普通 SELECT 操作时,通过访问记录的版本链,实现不同事务间的读-写、写-读操作可以并发进行,从而提升系统性能。
实用建议:什么时候选哪种隔离级别?
- 如果对一致性要求极高(如转账系统):用 SERIALIZABLE,但注意性能下降严重
- 一般系统默认 REPEATABLE READ 就够用了,配合MVCC性能好、隔离也够
- 如果你只想防止脏读,但可以接受不可重复读,READ COMMITTED 可以提高并发
- 可别图省事用最低的 READ UNCOMMITTED,脏读太危险,几乎没人用。









