


招行二面:Redis 为什么要 RDB 和 AOF 两种持久化方式?直接写日志不行吗?
这篇文章,我们来分享 Redis是如何实现持久化以及Redis 为什么要采用 RDB 和 AOF两种持久化方式。

1. 什么是持久化?
持久化,Persistence,把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。这样可以保证程序在服务器宕机后,重新启动不会丢失数据。
2. 持久化方式
Redis 的持久化方式有两种:RDB 和 AOF。
(1) RDB
RDB:Redis DataBase,它是将 Redis 在内存中的数据定期或者在指定时间间隔内快照到磁盘上,生成一个RDB文件,该文件包含了Redis在某个时间点上的数据快照。当 Redis 重新启动时,可以通过加载 RDB 文件来恢复数据。
(2) AOF
AOF:Append Only File,它是将 Redis 执行的每一条写命令追加到 AOF 文件的末尾,每次 Redis 启动时重新执行 AOF 文件中的命令,从而重新构建数据集。通过这种方式,可以保证 Redis 的数据不会丢失,但是对于每一次写操作都需要进行记录,AOF文件会变得非常大。
实现原理图如下:
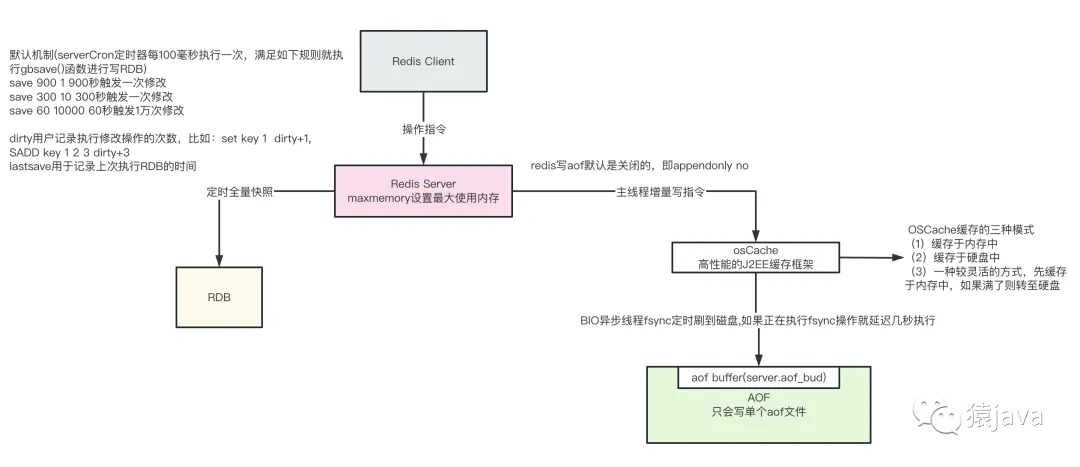
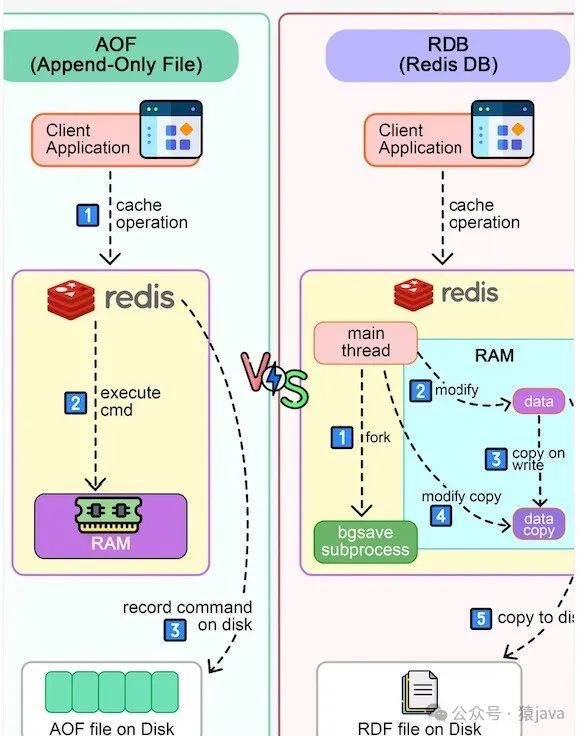
3. RDB原理
Redis DataBase(RDB)是将 Redis 在内存中的数据以二进制的形式定期或者在指定时间间隔内快照到磁盘上,生成一个 RDB 文件,该文件包含了 Redis 在某个时间点上的数据快照。当 Redis 重新启动时,可以通过加载 RDB 文件来恢复数据。其原理主要分为如下 3个核心流程:
(1) 触发持久化
Redis支持两种触发持久化的方式,一种是根据时间间隔自动触发持久化,另一种是手动执行 SAVE 或 BGSAVE 命令来触发持久化。手动执行 BGSAVE 命令可以在 Redis 持续提供服务的同时进行持久化操作,而手动执行 SAVE 命令会阻塞 Redis 的服务进程,直到持久化操作完成,所以生产换进慎用 SAVE 指令。
(2) 生成 RDB文件
当 Redis 触发持久化操作时,Redis 会 fork 出一个子进程,子进程负责生成 RDB 文件。在生成 RDB 文件的过程中,Redis 会将内存中的数据按照一定的格式写入到 RDB 文件中,包括键值对、过期时间、数据库号等信息。
(3) 完成持久化
当子进程完成 RDB 文件的生成后,Redis会将原来的RDB文件替换成新生成的RDB文件,从而完成持久化操作。在这个过程中,Redis会阻塞所有写操作,确保RDB文件的一致性。
Redis Server 自动创建 RDB 文件的默认配置在 redis.conf 里,内容如下:
save 900 1 # 服务器在900s(15分钟)之内,对数据进行了至少1次修改
save 300 10 #服务器在300s(5分钟)之内,对数据进行了至少10次修改
save 60 10000 #服务器在60s(1分钟)之内,对数据进行了至少10000次修改RDB文件格式由多个部分组成,包括:
- RDB文件头部:包含"REDIS"字样的字符串,以及版本号等信息。
- 保存键值对数据:键值对数据以"SELECTDB"命令开头,后面跟着一个4字节的整数,表示数据库编号。然后是若干个键值对数据,每个键值对包含3部分:键的长度、键的内容、值的内容。
- 保存过期时间:RDB文件还可以保存键值对的过期时间,以便在Redis重启时自动删除过期的键值对。过期时间以"EXPIRETIME_MS"命令开头,后面跟着键和过期时间等信息。
- RDB文件尾部:包含一个8字节的校验和,用于检测RDB文件是否被修改。
以下是一个简单的 RDB文件示例:
REDIS0006 // RDB文件头部
SELECTDB 0 // 选择数据库0
$3foo$3bar // 键为"foo",值为"bar"
$3abc$5hello // 键为"abc",值为"hello"
EXPIRETIME_MS $3foo$4 // 设置键"foo"的过期时间为4秒
00000000 // RDB文件尾部的校验和在读取RDB文件时,Redis会按照上述格式逐个解析RDB文件的每个部分,并将数据加载到内存中。如果Redis在重启时检测到了存在RDB文件,它将读取RDB文件,并将其中的数据加载到内存中,以便快速恢复数据。
4. AOF 原理
Append Only File(AOF),将 Redis 执行的每一条写命令追加到 AOF 文件的末尾,每次Redis启动时重新执行 AOF 文件中的命令,从而重新构建数据集。通过这种方式,可以保证 Redis 的数据不会丢失。
AOF 实现原理核心流程如下:
(1) AOF持久化策略
Redis 支持三种 AOF 持久化策略:
- always:每次执行写命令时都会将命令追加到AOF文件中。
- everysec:每秒执行一次AOF持久化操作,将一秒钟内执行的写命令追加到AOF文件中。
- no:不进行AOF持久化操作。
(2) AOF文件格式
AOF文件的格式是一系列Redis命令的序列化形式,Redis将写入AOF文件的命令转换为一系列字符串,并添加到AOF文件的末尾。这些命令包括SET、DEL、INCR等操作,但是对于读命令,如GET、HGET等操作,Redis不会将其写入AOF文件。
(3) AOF重写
AOF重写是为了解决 AOF 文件过大的问题,它会根据当前内存中的数据重建一个新的 AOF文件,并用新文件替换旧文件。在重写过程中,Redis会将一段时间内的写命令重写为一条SET命令或者DEL命令,从而减小AOF文件的大小。重写过程中,Redis会使用内存中的数据来生成新的AOF文件,并在生成过程中暂停所有写操作。
(4) 完成持久化
当Redis触发AOF持久化操作时,Redis会将内存中的写命令追加到AOF文件的末尾,然后通过fsync系统调用将写入的内容强制写入磁盘,确保数据的安全性。
AOF文件的格式非常简单,它是一个文本文件,每行都记录了一条Redis命令。每条命令都以"$"开头,表示命令长度,接着是命令的具体内容,以" "结尾。例如,以下是一条SET命令的AOF格式:
$3
SET
$5
mykey
$7
myvalue
其中,"表示命令的长度为,表示换行符,5 "表示key的长度为5,"mykey"是key的具体内容," "表示换行符,"$7 "表示value的长度为7,"myvalue"是value的具体内容," "表示换行符。
在AOF文件中,除了记录命令外,还有一些特殊的标记,如"* "表示一次多个命令的操作,"$-1 "表示空值,":0 "表示数字0等。
5. 优缺点
(1) RDB 优缺点
- 优点:对于数据的备份和恢复非常快速,因为它生成的是一个快照文件,不需要对每一条数据进行操作。
- 缺点:如果 Redis 意外宕机,可能会丢失最近一次快照时间点之后的数据。
(2) AOF 优缺点
- 优点:能够保证数据的完整性,即使 Redis 意外宕机,也可以通过 AOF 文件来恢复数据。
- 缺点:每一次写操作都需要进行记录,AOF文件会变得非常大,而且 AOF 重写操作会占用大量 CPU 和内存资源。
为了兼顾两种方式的优缺点,Redis提供了两种混合持久化方式:
- AOF重写:Redis会在后台启动一个进程,重写 AOF文件,将其中的无效命令删除,从而缩小AOF文件的大小。
- AOF 和 RDB同时开启:Redis同时使用 AOF 和 RDB 两种方式进行持久化,当Redis重启时,优先使用 AOF 文件来恢复数据,如果 AOF 文件不存在或者损坏,则使用 RDB文件来恢复数据。
6. AOF 重写机制
AOF重写机制是Redis用来解决AOF文件过大问题的一种机制。当AOF文件过大时,可以通过 AOF 重写机制来生成一个新的、紧凑的 AOF 文件,以减小 AOF 文件的大小,提高Redis的性能。
AOF重写机制的实现原理总结为下面 3步:
(1) 触发AOF重写
Redis会周期性地检查 AOF 文件的大小,如果超过了设定的阈值,就会触发 AOF 重写操作。在默认情况下,当 AOF 文件大小超过64MB时,Redis会自动触发 AOF 重写操作。如果需要修改阈值,可以通过配置文件中的"auto-aof-rewrite-percentage"和"auto-aof-rewrite-min-size"参数来修改。
(2) 执行AOF重写
AOF重写操作是在一个子进程中执行的,它会遍历内存中的数据结构,将一段时间内的写命令重写为一条SET命令或者 DEL命令,并写入新的 AOF 文件。在重写过程中,Redis会将新的AOF文件和旧的AOF文件进行比较,如果发现有相同的命令序列,就会将新的AOF文件中的命令序列替换为旧的AOF文件中的命令序列,以减小新AOF文件的大小。
(3) 完成AOF重写
AOF重写操作完成后,Redis会将新的AOF文件替换旧的AOF文件,并通过fsync系统调用将写入的内容强制写入磁盘,以确保数据的安全性。
AOF重写机制的优点是可以减小AOF文件的大小,提高Redis的性能,缺点是重写操作会占用大量CPU和内存资源,如果数据量较大,可能会导致Redis的性能下降。









