


P7领导建议:可以用UUIDv7作为数据库主键
前言
大家好,我是田螺。
我们提到分布式主键ID的时候,可能都会想到UUID,比如在设计数据库主键的时候。但是可能最终都不会考虑它。但是呢,最近领导却建议说,可以考虑它作为数据库主键了,因为UUIDv7的出现~~
1. 传统 UUID 作为主键的缺点
传统 UUID(尤其是 v4)的 完全随机性 是其作为数据库主键的“原罪”:
无序性 (最主要问题):
- 数据库索引(尤其是 B+Tree)依赖主键顺序插入新记录效率最高。
- UUID 随机生成,插入位置不确定,导致索引树频繁分裂和重组,大幅降低写入性能。
- 破坏聚簇索引(如 InnoDB)的物理存储顺序,增加磁盘 I/O。
- 范围查询和排序效率低下,性能低下。
存储空间大:
- 占用存储空间是自增整数(如 64位 BigInt)的 2倍。
- 导致索引更大,占用更多内存/磁盘,缓存效率降低,查询变慢
2. UUIDv7 的核心突破:时间有序性架构设计
UUIDv7 的革新性在于将 时间戳嵌入最高有效位(Most Significant Bits),实现了全局单调递增。其 128 位结构如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
┌─────────────────────┬─────┬─────┬─────────────────────────────┐
│ Unix毫秒时间戳 │ Ver │Var │ 随机位 │
│ (48位) │(4) │(2) │ (74位) │
└─────────────────────┴─────┴─────┴─────────────────────────────┘设计关键点解析:
- 高精度时间前缀(48位):精确到毫秒的 Unix 时间戳,确保 ID 严格按时间递增(需 NTP 时钟同步)。
- 尾部随机位(74位):保证分布式唯一性,避免 v1 的 MAC 地址泄露风险。
有序性如何解决性能问题?
- B+树索引优化
新生成的 UUIDv7 总是大于之前的值,因此被追加到索引尾部,避免中间节点分裂。
- 缓冲池友好顺序写入使新记录集中在少数数据页。当页写满时,数据库只需分配新页追加,减少旧页淘汰与磁盘I/O。
- 范围查询加速时间有序性使 WHERE id > '2025-06-01' 可转化为 时间戳范围过滤,大幅降低扫描范围
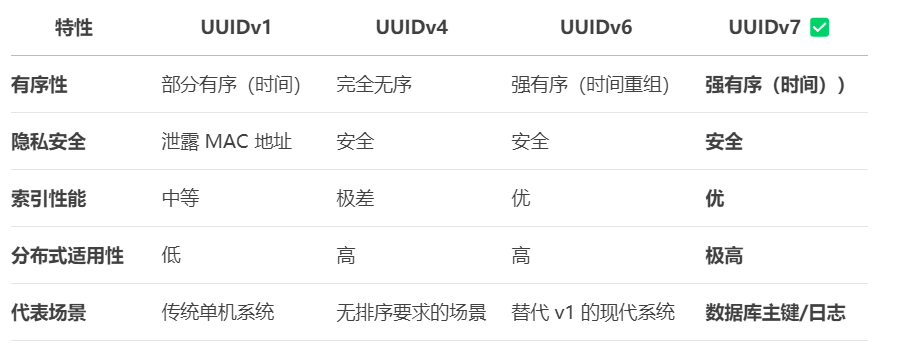
3. UUIDv7 和其他版本的横向对比
4.项目实战:如何使用 UUIDv7?
- 生成 UUIDv7
import com.github.f4b6a3.uuid.UuidCreator;
public class UuidUtils {
public static UUID generateUuidV7() {
return UuidCreator.getTimeOrdered(); // 生成 UUIDv7
}
// 转为数据库存储格式
public static byte[] toBytes(UUID uuid) {
ByteBuffer bb = ByteBuffer.wrap(new byte[16]);
bb.putLong(uuid.getMostSignificantBits());
bb.putLong(uuid.getLeastSignificantBits());
return bb.array();
}
// 从数据库读取转换
public static UUID fromBytes(byte[] bytes) {
ByteBuffer bb = ByteBuffer.wrap(bytes);
return new UUID(bb.getLong(), bb.getLong());
}
}
// 使用示例
UUID id = UuidService.generateUuidV7();- 数据库作为主键
CREATE TABLE users (
id BINARY(16) PRIMARY KEY, -- 二进制存储 UUID
name VARCHAR(50) NOT NULL,
email VARCHAR(100)
);- 插入数据库和查询
// 插入数据
UUID userId = UuidUtils.generateUuidV7();
String sql = "INSERT INTO users (id, name) VALUES (?, ?)";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setBytes(1, UuidUtils.toBytes(userId));
ps.setString(2, "John Doe");
ps.executeUpdate();
}
// 查询数据
String query = "SELECT * FROM users WHERE id = ?";
try (PreparedStatement ps = conn.prepareStatement(query)) {
ps.setBytes(1, UuidUtils.toBytes(userId));
ResultSet rs = ps.executeQuery();
while (rs.next()) {
UUID id = UuidUtils.fromBytes(rs.getBytes("id"));
String name = rs.getString("name");
}
}5. 关于UUIDv7 常见问题解答
5.1 UUIDv7到底会不会重复
极低概率,可视为唯一
UUIDv7由48位毫秒级Unix时间戳(约8.5万年后才会耗尽) + 74位随机数组成,总组合数达2^122(约5.3×10^36)。即使每秒生成10亿个UUID,重复概率也远低于10^-15,理论上可忽略。
极端场景,若系统时钟回拨且在同一毫秒内生成大量UUID(超过2^74个),可能冲突,但实际中几乎不可能发生。
5.2 什么是时钟回拨?对UUIDv7有何影响?
- 原因:服务器时间因NTP同步错误、电源波动、虚拟机宿主机调整等意外回退。
- 问题:时钟回拨后,新生成的UUIDv7时间戳可能小于前值,若回拨期间随机数碰撞则可能重复
- 如何解决呢?
(1)预防措施:
- 使用冗余时钟源:如GPS+原子钟+NTP多层级同步,减少单点故障。
- 监控时钟漂移:通过Kalman滤波等算法实时修正时间偏差。
- 避免虚拟机时钟漂移:优先部署于物理机。
(2)生成时容错:
- 时间戳延续:检测到回拨时,延续最后记录的时间戳直至超过回拨区间。
- 随机数扩容:回拨期间扩展随机数位数(如占用预留位),降低碰撞概率









