如何将训练好的机器学习模型嵌入到业务系统?
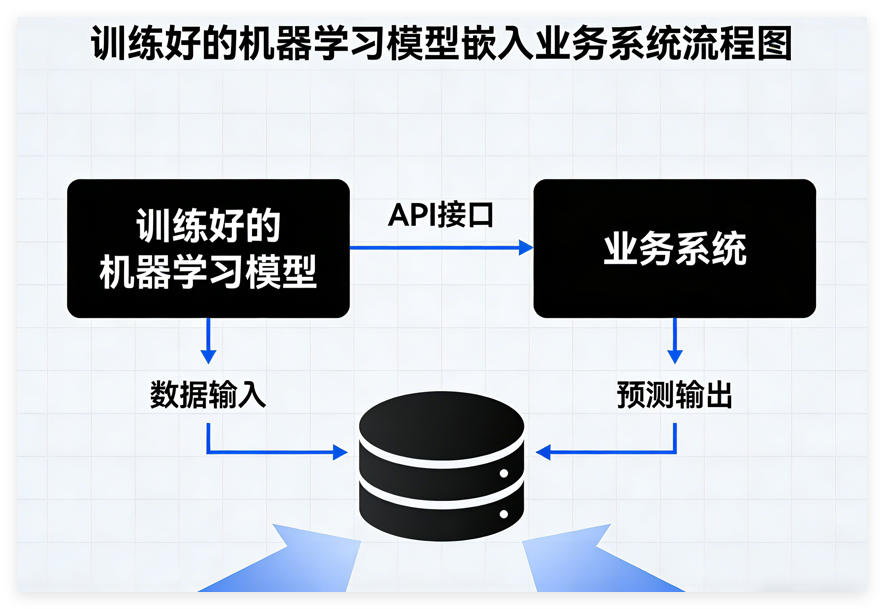
将训练好的机器学习模型嵌入到业务应用系统中,有多种方法可以实现。让我为您详细介绍几种常见的部署方式:
首先保存模型,代码如下:
import joblib
joblib.dump(model, 'pressure_ulcer_svm_model.pkl')
joblib.dump(scaler, 'pressure_ulcer_scaler.pkl')
print("
模型已保存为 'pressure_ulcer_svm_model.pkl'")
print("标准化器已保存为 'pressure_ulcer_scaler.pkl'")
1. 模型文件加载与预测API
您已经使用joblib保存了模型,可以创建一个预测服务:
import joblib
import pandas as pd
import numpy as np
class PressureUlcerPredictor:
def __init__(self, model_path='pressure_ulcer_svm_model.pkl',
scaler_path='pressure_ulcer_scaler.pkl'):
self.model = joblib.load(model_path)
self.scaler = joblib.load(scaler_path)
def predict_single(self, patient_data):
"""
预测单个患者的压疮风险
patient_data: dict, 包含患者各项生理指标
"""
# 将输入数据转换为DataFrame
df = pd.DataFrame([patient_data])
# 数据预处理(需要与训练时保持一致)
df_scaled = self.scaler.transform(df)
# 进行预测
prediction = self.model.predict(df_scaled)[0]
# 获取预测概率
probabilities = self.model.predict_proba(df_scaled)[0]
return {
'prediction': int(prediction),
'probabilities': probabilities.tolist(),
'risk_level': self._interpret_risk(prediction)
}
def _interpret_risk(self, prediction):
# 根据实际标签定义风险等级
risk_levels = {0: '低风险', 1: '中风险', 2: '高风险'}
return risk_levels.get(prediction, '未知风险')
2. REST API服务
创建一个Web API供业务系统调用:
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
predictor = PressureUlcerPredictor()
@app.route('/predict', methods=['POST'])
def predict_pressure_ulcer():
try:
patient_data = request.json
result = predictor.predict_single(patient_data)
return jsonify(result)
except Exception as e:
return jsonify({'error': str(e)}), 400
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
3. 微服务架构集成
如果您有微服务架构,可以将模型封装为独立的微服务:
# model_service.py
import grpc
from concurrent import futures
import model_pb2
import model_pb2_grpc
class ModelService(model_pb2_grpc.ModelServiceServicer):
def Predict(self, request, context):
# 处理预测请求
patient_data = {
'性别': request.gender,
'年龄': request.age,
'白细胞': request.wbc,
# ... 其他特征
}
result = predictor.predict_single(patient_data)
return model_pb2.PredictionResponse(
risk_level=result['risk_level'],
confidence=max(result['probabilities'])
)
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
model_pb2_grpc.add_ModelServiceServicer_to_server(ModelService(), server)
server.add_insecure_port('[::]:50051')
server.start()
4. 数据库集成
可以在数据库层面集成预测功能:
-- 创建存储过程来调用模型预测
CREATE PROCEDURE PredictPressureUlcer(
@gender INT,
@age FLOAT,
@wbc FLOAT,
@result NVARCHAR(50) OUTPUT
)
AS
BEGIN
-- 调用Python脚本或外部模型服务
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
import pickle
import numpy as np
# 加载模型和预测逻辑
with open("pressure_ulcer_svm_model.pkl", "rb") as f:
model = pickle.load(f)
input_data = np.array([[gender, age, wbc]]) # 根据实际特征顺序调整
prediction = model.predict(input_data)[0]
result = str(prediction)
',
@params = N'@gender float, @age float, @wbc float, @result nvarchar(50) OUTPUT',
@gender = @gender,
@age = @age,
@wbc = @wbc,
@result = @result OUTPUT;
END
5. 实时预测集成示例
为业务系统提供实时预测接口:
# business_integration.py
import requests
import json
class BusinessIntegration:
def __init__(self, api_url='http://localhost:5000/predict'):
self.api_url = api_url
def predict_patient_risk(self, patient_info):
"""
为业务系统提供患者风险预测接口
"""
response = requests.post(
self.api_url,
json=patient_info,
headers={'Content-Type': 'application/json'}
)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"Prediction failed: {response.text}")
def batch_predict(self, patients_list):
"""
批量预测多个患者的风险
"""
results = []
for patient in patients_list:
try:
result = self.predict_patient_risk(patient)
results.append(result)
except Exception as e:
results.append({'error': str(e)})
return results
# 业务系统中使用
integration = BusinessIntegration()
# 在患者录入或更新时自动触发风险评估
def on_patient_update(patient_record):
risk_assessment = integration.predict_patient_risk({
'性别': patient_record['gender'],
'年龄': patient_record['age'],
'白细胞': patient_record['wbc'],
# ... 其他必需的特征
})
# 根据风险等级触发相应业务逻辑
if risk_assessment['risk_level'] == '高风险':
trigger_alert(patient_record['patient_id'])
schedule_frequent_monitoring(patient_record['patient_id'])
6. 监控和更新机制
为了确保模型在生产环境中持续有效:
# model_monitoring.py
import datetime
from collections import defaultdict
class ModelMonitor:
def __init__(self):
self.prediction_log = []
self.performance_metrics = defaultdict(list)
def log_prediction(self, input_data, prediction, actual_result=None):
log_entry = {
'timestamp': datetime.datetime.now(),
'input': input_data,
'prediction': prediction,
'actual': actual_result
}
self.prediction_log.append(log_entry)
def calculate_drift(self, new_data_batch):
# 检测数据漂移
pass
def trigger_retraining(self):
# 当性能下降时触发重新训练
pass
实施建议:
- API优先:建议首先创建REST API,这样业务系统可以通过HTTP请求调用模型
- 异步处理:对于批量预测,使用异步队列处理
- 缓存机制:对频繁查询的结果进行缓存
- 监控告警:建立模型性能监控和异常告警机制
- 版本管理:实现模型版本管理,支持灰度发布
这样,训练好的机器学习预测模型就可以无缝集成到业务应用系统中。