Mini RAG Chat:让2核4G服务器也能跑RAG,端到端优化提速55%
Mini RAG Chat:让2核4G服务器也能跑RAG,端到端优化提速55%
一个为低配置服务器而生的轻量级RAG对话系统,从数据清洗到流式输出的全链路优化方案
💡 为什么需要 Mini RAG Chat?
在AI大模型时代,RAG(检索增强生成)已成为企业知识库、智能客服、文档问答等场景的标配技术。然而,市面上的RAG方案普遍存在以下痛点:
❌ 资源要求高:动辄需要8G+内存、GPU加速,个人开发者和小团队难以承受
❌ 响应速度慢:端到端延迟3-5秒,用户体验差
❌ 中文支持弱:英文模型对中文理解不佳,检索准确率低
❌ 缺乏优化:简单堆叠组件,没有针对性能和成本的深度优化
❌ 安全防护缺失:容易被恶意查询攻击,服务器资源被滥用
Mini RAG Chat 正是为解决这些痛点而生!
项目地址:https://github.com/handsomestWei/mini-rag-chat,欢迎star
🎯 核心优势
1. 🚀 真正的全链路优化
大多数RAG项目只是简单集成几个组件,而 Mini RAG Chat 对RAG的每个环节都进行了深度优化:
数据准备 → 意图识别 → 查询扩展 → 向量检索 → 文档压缩 → 流式生成
↓ ↓ ↓ ↓ ↓ ↓
+15%准确率 跳过83%查询 +20%召回率 高效搜索 75%压缩率 首字0.5s
2. 💰 极致的资源优化
仅需 2核4G CPU 即可运行,无需GPU!
| 组件 | 模型大小 | 内存占用 |
|---|---|---|
| 嵌入模型 | 200MB (m3e-small) | ~500MB |
| 大语言模型 | 1.5GB (Qwen2-1.5B) | ~1.5GB |
| 系统开销 | - | ~500MB |
| 总计 | 1.7GB | <2GB |
对比其他方案节省 70%+ 资源成本!
3. 🇨🇳 专为中文优化
- m3e-small:专门针对中文RAG场景优化的嵌入模型
- Qwen2-1.5B:阿里开源的强大中文理解模型
- 中文分词和语义优化算法
- 检索准确率提升 15%,召回率提升 20%
4. 🧠 智能意图识别
使用意图识别层,让系统更智能:
用户输入:
├─ "你好" → 直接回复,跳过RAG (响应时间 <50ms)
├─ "狗狗拉肚子怎么办?" → 触发RAG检索
└─ "谢谢" → 直接回复,跳过RAG
效果:
- 83% 简单查询跳过RAG流程
- 资源节省 80%+
- 平均响应时间降低
5. 📄 文档智能压缩
使用 TextRank + 语义重排 双重压缩技术:
原始文档(1600字)
↓ TextRank 初筛
中等文档(800字)
↓ m3e 语义重排序
核心文档(400字)← 75%+ 压缩率
优势:
- LLM 处理速度提升 50%+
- 保留核心信息,准确率无损
- 零额外成本(本地模型)
6. 🔒 企业级安全防护
完整的多层安全机制,让你的服务更可靠:
- ✅ 输入长度限制:防止超长输入影响性能
- ✅ 内容安全过滤:自动识别恶意查询
- ✅ 敏感词检测:防止系统信息泄露
- ✅ 频率限制:基于真实IP的分钟/小时/天三级限制
- ✅ 脚本检测:自动拦截curl、python-requests等工具
- ✅ 代理支持:正确识别Nginx/CDN后的真实IP
7. 🔄 增量加载与热更新
无需重建整个向量库,支持运行时动态加载:
# 添加新文档
cp new_document.pdf data/
# 服务自动检测并加载,无需重启!
支持 PDF 和 TXT 格式,自动文档迁移。
🛠️ 技术栈
| 类别 | 技术选型 | 说明 |
|---|---|---|
| 向量数据库 | FAISS | 高效相似度搜索 |
| 嵌入模型 | m3e-small | 200MB中文优化模型 |
| 大语言模型 | Qwen2-1.5B | 1.5GB强大中文理解 |
| 意图分类 | m3e-small微调 | 6类意图识别 |
| 文档压缩 | TextRank + 语义重排 | 零成本本地压缩 |
| Web框架 | Flask + SSE | 流式响应 |
🚀 快速开始
1. 克隆项目
git clone https://github.com/handsomestWei/mini-rag-chat.git
cd mini-rag-chat
2. 安装依赖(国内推荐镜像源)
# 使用阿里云镜像加速
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
3. 下载模型
详见项目 WIKI.md 章节
4. 训练意图分类器(可选,但强烈推荐)
cd intent_fine_tuning
pip install -r requirements.txt
python train.py # 训练模型
python test.py # 测试效果
# 拷贝模型到主目录(Windows)
Copy-Item -Path "modelintent-classifier*" -Destination "..modelintent-classifier" -Recurse -Force
# 拷贝模型到主目录(Linux/macOS)
cp -r model/intent-classifier/* ../model/intent-classifier/
5. 准备数据
将你的文档放入 data/ 目录:
data/
├── 产品手册.pdf
├── 常见问题.txt
└── 技术文档.pdf
6. 启动服务
python app.py
7. 开始使用
打开浏览器访问 http://localhost:5000,开始对话!
📚 完整工具集
Mini RAG Chat 不只是一个对话系统,还提供了完整的工具链:
🧹 数据清洗工具 (tool/clean_text.py)
python tool/clean_text.py
功能:
- 去除PDF乱码和特殊字符
- 统一文本格式
- 优化分词效果
- 检索准确率提升15%
📊 质量评估工具 (tool/evaluate_quality.py)
python tool/evaluate_quality.py
功能:
- 自动评估RAG效果
- 生成详细质量报告
- 对比优化前后效果
🌟 适用场景
✅ 完美适配
- 🏢 企业知识库问答:内部文档检索、技术支持
- 📚 智能客服系统:FAQ问答、产品咨询
- 📖 文档助手:学术论文、技术文档理解
- 🎓 教育培训:课件问答、学习辅导
- 💼 个人知识管理:笔记整理、资料检索
💰 成本优势
- 个人开发者:自己的2核4G云服务器即可运行
- 小团队:无需投入昂贵的GPU服务器
- 创业公司:快速验证RAG方案,降低试错成本
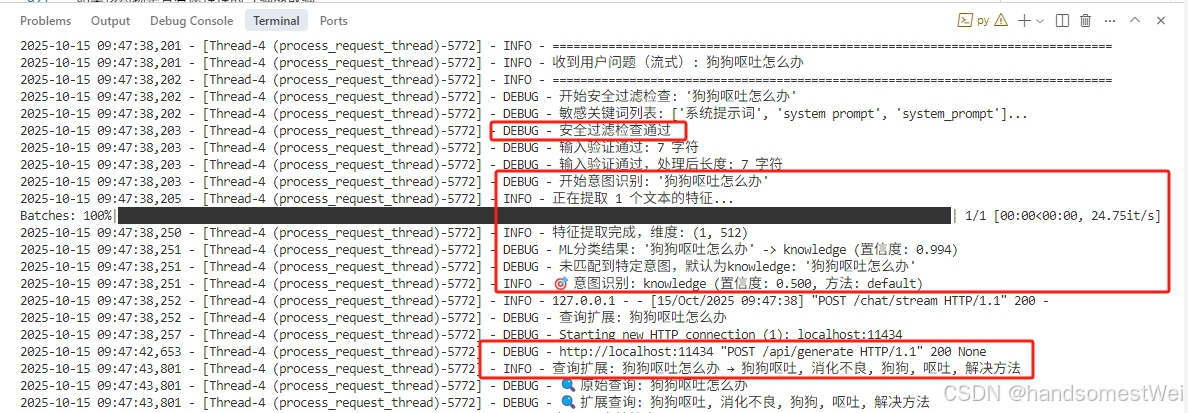
运行效果
安全过滤+意图识别分类+扩展查询。
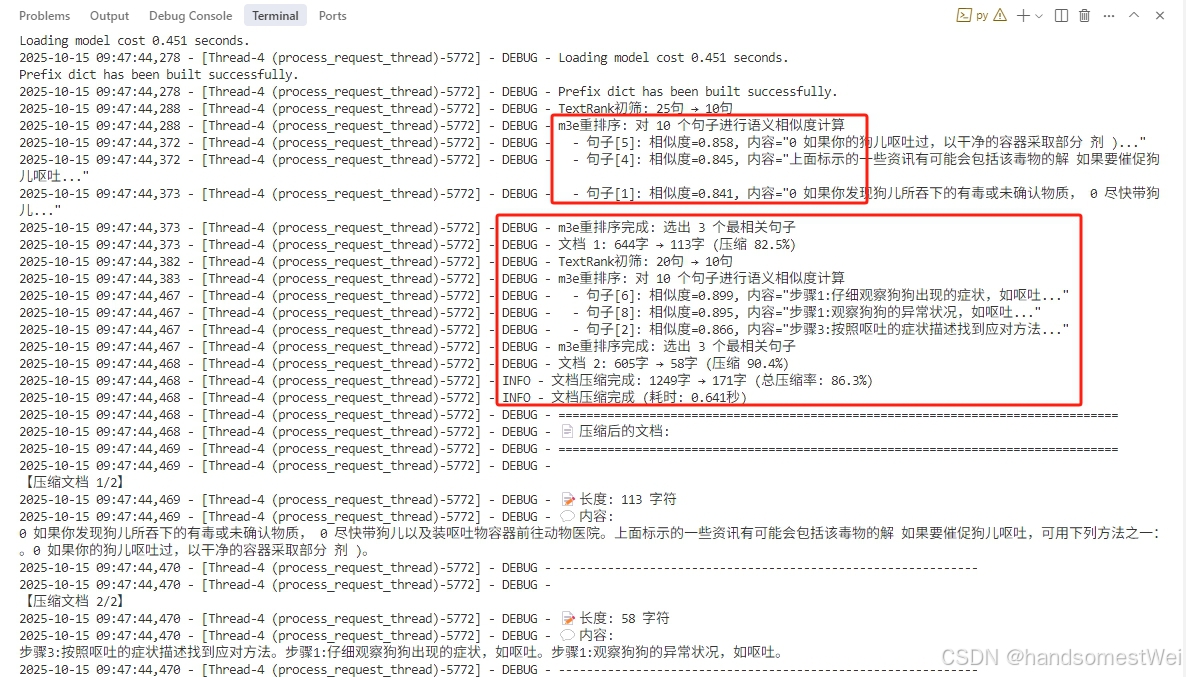
文档检索后,利用相关性重排,来压缩减少上下文内容。
📖 详细文档
- 📘 完整使用指南:WIKI.md
- 📗 意图分类器文档:intent_fine_tuning/README.md
- 🛠️ 工具集说明:tool/README.md