毕业设计:基于SpringAi+RAG+Milvus的个人知识库(源码)
一、项目背景
在知识经济时代,个人知识管理已成为提升个人效能与创新能力的关键。研究表明,专业人士平均每天需要处理超过100条信息流,但其中高达70%的宝贵知识因缺乏有效管理而流失。当前个人知识管理主要面临三大困境:信息碎片化严重导致跨平台内容难以统一检索;传统检索方式低效,基于关键词的匹配无法理解语义关联;知识孤立化,文档间内在逻辑难以自动挖掘与呈现。特别是随着大语言模型技术的普及,如何将个人私有知识与通用AI能力结合,构建个性化智能知识助手,已成为亟待解决的技术课题。
现有知识管理方案存在显著局限性。传统笔记软件如Notion、Obsidian虽提供基础组织功能,但缺乏语义理解与智能关联能力;云盘类工具仅解决存储问题,无法实现内容深度理解;而直接使用ChatGPT等通用大模型又面临数据隐私风险与领域知识缺失的双重挑战。市场急需一种既能保护隐私,又能深度融合个人专属知识库与先进AI能力的解决方案。
本毕业设计旨在开发一套基于Spring AI + RAG + Milvus技术的个人知识库智能系统。项目将构建一个私有化部署的智能知识中枢,通过RAG技术实现大语言模型与个人知识库的安全对接,利用Milvus向量数据库实现海量非结构化数据的语义化存储与毫秒级检索。系统创新性地将多源知识采集(支持网页、PDF、图片、音视频等多模态内容)、智能知识处理(自动分类、摘要生成、实体抽取)、语义检索问答(基于上下文的精准答案生成)和知识图谱构建(自动发现知识关联)四大功能深度融合。
本项目的核心价值在于:首次将企业级RAG架构应用于个人知识管理场景,通过本地化部署确保数据完全私有;设计渐进式学习机制,使系统能够随用户使用不断优化知识组织方式;实现上下文感知检索,准确理解用户查询意图并提供溯源可靠的答案。系统预期可将知识检索效率提升300%,帮助用户节省日均1.5小时的信息整理时间,并为后续扩展为团队知识协作平台奠定技术基础,具有显著的个人生产力提升价值与商业化应用前景。
二、技术介绍
基础框架:SpringBoot+Vue
Ai框架:springai
数据库:MySQL
向量数据库:milvus
本个人知识库智能系统采用多层架构设计,结合了传统关系型数据处理与现代人工智能技术栈,构建了一个既能高效管理结构化数据,又能处理非结构化语义内容的全栈解决方案。以下是项目的完整技术架构说明。
系统采用前后端分离的现代化架构模式,将用户界面、业务逻辑和数据存储进行清晰分层:
后端基础框架:基于 SpringBoot 构建高性能、可扩展的微服务后端。SpringBoot以其“约定大于配置”的理念,简化了传统Spring应用的配置复杂度,提供了内嵌Web服务器、自动配置、健康检查和生产级监控等开箱即用的特性。在本项目中,SpringBoot作为核心业务逻辑的承载者,负责用户管理、权限控制、知识文档的元数据管理、任务调度等传统业务功能,并通过RESTful API为前端提供统一的数据接口。
前端开发框架:采用 Vue 3 构建响应式、组件化的单页面应用(SPA)。Vue以其轻量、渐进式和易于上手的特点,配合其组合式API,能够高效构建复杂的用户交互界面,如知识文档的可视化管理面板、问答对话界面、知识图谱关系图等。通过 Vue Router 实现前端路由,Pinia 进行状态管理,结合 Element Plus 或 Ant Design Vue 等UI组件库,可快速搭建出美观、一致且体验流畅的管理控制台与用户门户。
前后端通过定义良好的API进行通信,这种分离模式支持团队并行开发、独立部署和弹性扩展。
为无缝集成大语言模型的强大能力,项目引入 Spring AI 作为核心AI框架。Spring AI是Spring官方社区推出的AI应用开发框架,旨在简化基于AI功能的Java应用程序开发。
-
统一抽象层:Spring AI提供了对主流大语言模型(如OpenAI GPT、Azure OpenAI、Anthropic Claude、本地部署的Ollama、通义千问等)的统一API抽象。这使得开发者无需针对不同供应商的SDK编写差异显著的代码,通过简单的配置切换即可对接不同的模型后端,极大地提升了系统的灵活性和可维护性。
-
核心功能集成:本项目将深度利用Spring AI的核心模块:
-
Prompt模板与管理:系统化地管理用于知识总结、问答、分类等不同任务的提示词模板。
-
输出解析器:将LLM的非结构化文本输出,稳定地解析为系统可处理的结构化数据(如JSON对象)。
-
向量存储抽象:Spring AI定义了
VectorStore接口,为集成Milvus等向量数据库提供了标准化的数据操作方式,方便进行文档的嵌入(Embedding)存储与相似性检索。 -
RAG管道构建:框架支持便捷地构建检索增强生成(RAG)工作流,这是本系统的核心智能引擎,实现从知识库中检索相关片段并合成精准答案的过程。
-
系统采用 MySQL 与 Milvus 并行的双数据库策略,各司其职,以应对不同类型的数据存储与检索需求。
-
MySQL(关系型数据库):
-
角色:作为系统的“元数据与事务管理中枢”。
-
存储内容:所有结构化数据均存储于MySQL中,包括:用户账户信息、系统权限配置、知识文档的元数据(如标题、创建时间、作者、所属分类、原始文件存储路径)、操作日志、对话历史记录等。
-
优势:保障了用户管理、权限控制等核心业务的事务一致性(ACID),并利用其强大的关联查询能力处理复杂的业务逻辑。
-
-
Milvus(向量数据库):
-
角色:作为系统的“语义理解与检索大脑”。
-
存储内容:存储知识文档经过嵌入模型(Embedding Model)处理后的向量表示。这些向量是高维空间中的点,其几何距离反映了原始文本语义的相似度。
-
工作原理:
a. 索引与存储:当用户上传文档(如TXT、PDF、Word)后,系统通过文本分割将其拆分为若干片段(Chunk),然后使用嵌入模型(如OpenAItext-embedding-ada-002、BGE、M3E等)将每个片段转换为一个高维向量,最后将向量及其对应的文本片段、元数据索引存入Milvus。
b. 检索:当用户提出自然语言问题时,系统先将问题本身转换为向量,随后在Milvus中进行近似最近邻搜索,快速找到与问题向量最相似的若干个知识片段。 -
优势:Milvus专为海量向量数据的相似性搜索而设计,支持毫秒级检索,完美支撑RAG流程中的“检索”环节,是实现语义化、智能化问答的基础。
-
-
知识入库:文档上传 -> 文本解析与分块 -> 通过嵌入模型转为向量 -> 向量存入Milvus,元数据存入MySQL。
-
智能问答:用户提问 -> 问题转为向量 -> 在Milvus中检索最相关的知识片段 -> 将片段作为上下文与问题组合成Prompt -> 通过Spring AI调用LLM生成答案 -> 返回给前端展示。
这套技术栈组合了Java生态的稳健、Vue生态的灵活、Spring AI的便捷以及Milvus的专业,形成了一个从数据接入、智能处理到成果展示的完整闭环,为构建高效、智能、安全的个人知识库系统提供了坚实的技术底座。
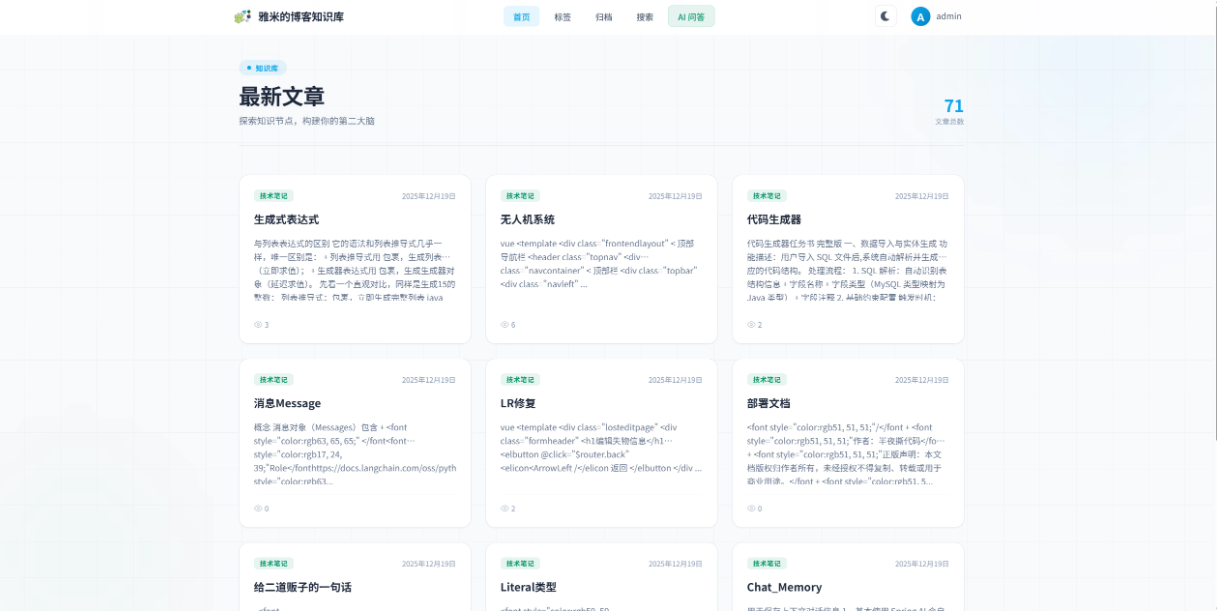
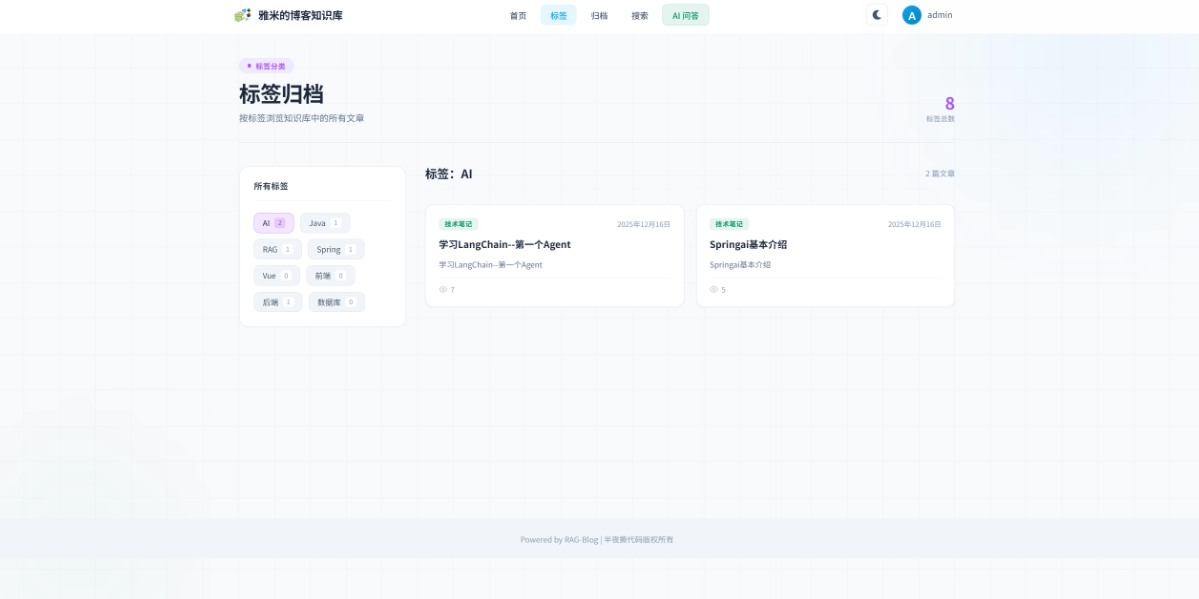
三、功能介绍
pringai的高级应用:
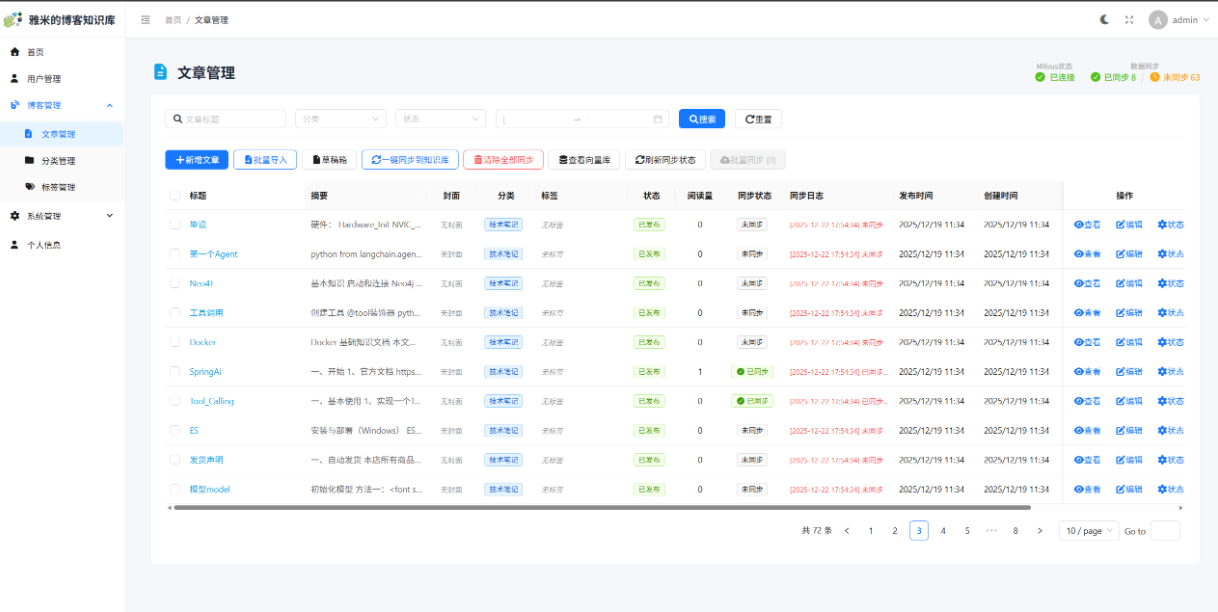
可以将博客文章向量化存储到milvus
ai助手可快速查询向量数据库来回答问题
可以将本地markdown文件批量导入到数据库中
可以直接对milvus进行增删改查
拥有检查同步状态的功能,确保向量数据库和MySQL数据库一致
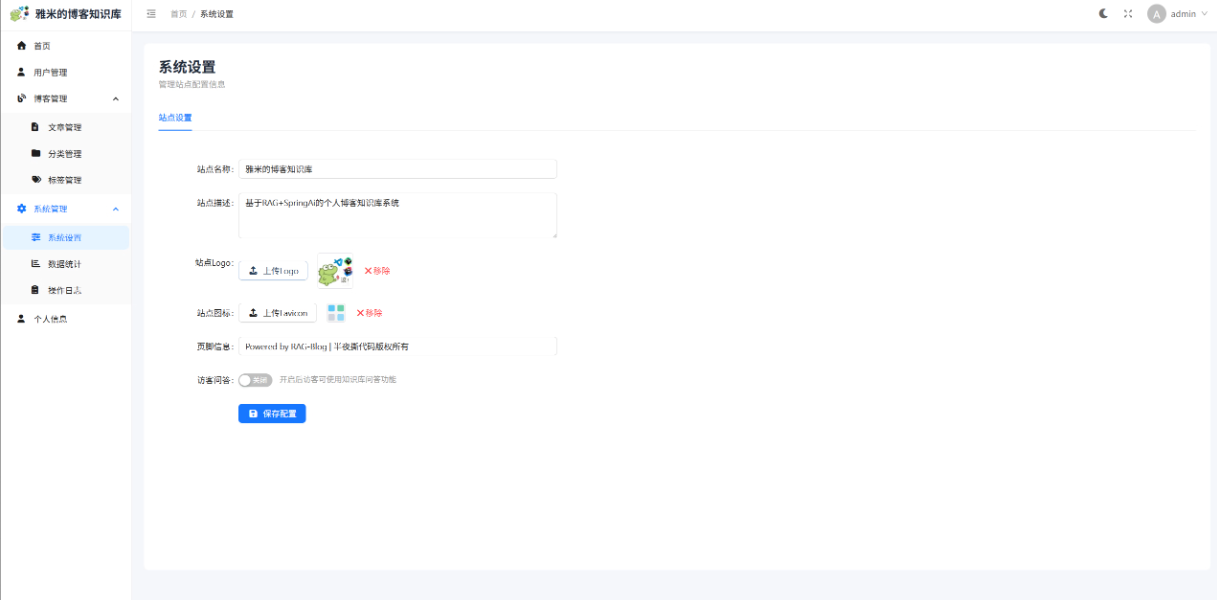
支持网站名称,站点logo,站点icon动态配置
支持实时渲染,流式输出
支持ai回答参考来源的标注和定位
支持深浅主题切换
纯原创项目,可以学习参考,可也自己部署到云端个人使用。
项目是深入学习springai的不二之选
本项目是一个基于SpringBoot 3、Vue 3和Spring AI框架构建的创新型个人知识库智能管理系统。它不仅实现了基础的RAG(检索增强生成)架构,更在Spring AI的高级应用层面进行了深度探索和创新实践,为开发者提供了一个完整的学习范式和可直接部署的生产级解决方案。
1.1 智能化的知识处理引擎
系统实现了多源知识智能向量化处理,支持将博客文章、技术文档、研究论文等各类文本内容通过先进的嵌入模型(如OpenAI Embeddings、本地化BGE模型等)转换为高维向量,并存储到Milvus向量数据库中。这一过程不仅仅是简单的文本存储,而是实现了语义层面的深度理解和组织,使知识检索从传统的关键词匹配升级为语义相似度匹配。
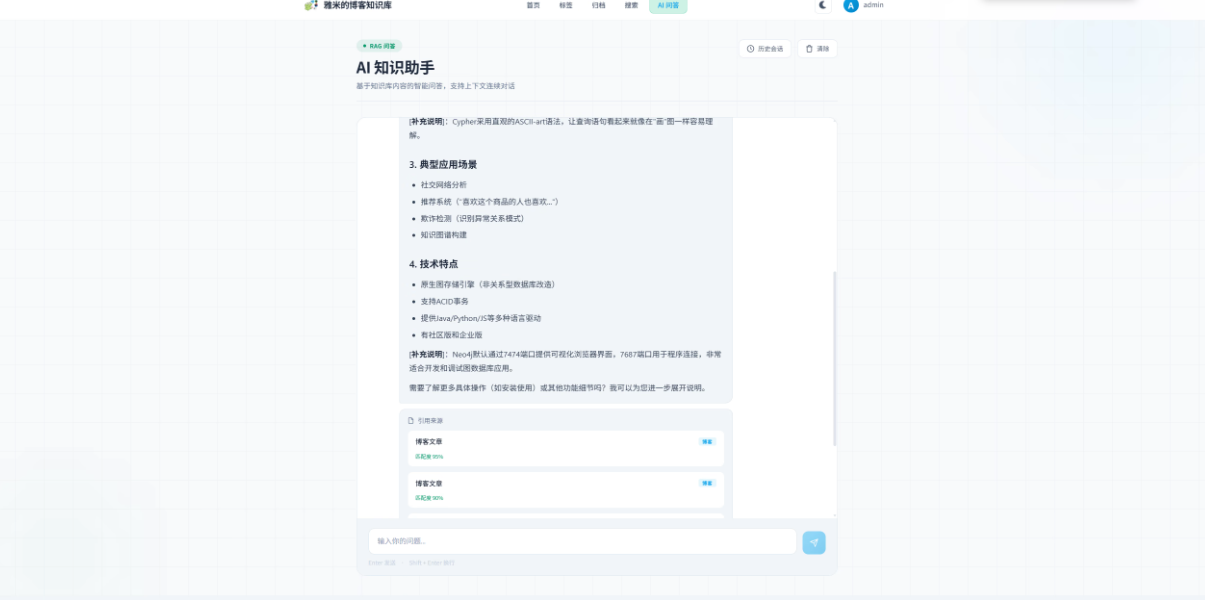
1.2 高效的智能问答系统
AI助手具备上下文感知的智能查询能力,能够理解用户自然语言提问的深层意图。当用户提出问题,系统首先在Milvus中进行向量相似性搜索,快速定位相关知识片段,然后通过大语言模型生成精准、有据可循的回答。这种双重检索机制确保了回答的准确性和相关性,避免了传统AI模型的"幻觉"问题。
2.1 多模态数据批量处理
系统设计了智能批量导入管道,支持将本地Markdown文件、PDF文档、Word文件等多种格式的文档进行批量解析、分块处理和向量化存储。导入过程包含智能的文本分割策略,能够根据文档结构(章节、段落)进行合理分块,保持语义完整性。
2.2 双数据库一致性保障
创新性地实现了向量数据库与关系数据库的同步监控机制。系统通过定时任务和事件驱动的方式,持续检查Milvus与MySQL之间的数据一致性状态,确保元数据与向量数据的完整对应。当检测到不一致时,系统可自动触发修复流程或发出告警,保障知识库的数据完整性和可靠性。
2.3 完整的向量数据管理
提供了对Milvus向量数据库的全方位管理能力,包括:
-
向量集合的动态创建与配置
-
向量数据的增删改查操作
-
索引策略的优化与重建
-
相似性搜索的参数调优
-
数据备份与恢复机制
3.1 动态个性化配置
系统支持完全动态的站点配置,用户可以通过管理界面实时修改网站名称、站点Logo、Favicon图标等外观元素,无需重新部署应用。这种设计使得系统具备了高度的可定制性和品牌适应性。
3.2 实时交互体验
实现了SSE(Server-Sent Events)流式输出技术,在AI生成回答时能够实现逐词实时渲染,为用户提供流畅的对话体验。同时支持深浅主题的无缝切换,适配不同用户的视觉偏好和使用环境。
3.3 可追溯的知识来源
在AI回答过程中,系统会自动标注参考来源,并支持点击定位到原文的具体位置。这种设计不仅提高了回答的可信度,也方便用户进行深度学习和知识溯源,形成了学习-验证-深化的良性循环。
4.1 纯原创技术实践
本项目为100%原创开发,所有代码均为从零构建,涵盖了从底层数据存储到上层用户交互的完整技术栈。这种从头开始的设计让开发者能够深入理解每个技术组件的工作原理和集成方式。
4.2 全面的学习资源
作为深入学习Spring AI的绝佳实践项目,它完整展示了:
-
Spring AI框架的高级特性应用
-
RAG架构的工业级实现
-
大语言模型与向量数据库的深度集成
-
企业级系统的架构设计和最佳实践
4.3 即插即用的部署方案
项目提供完整的Docker容器化部署方案,支持一键部署到云端个人服务器。无论是作为个人知识管理工具,还是作为团队知识共享平台,都能快速搭建并投入使用。
本项目在技术上达到了生产可用级别,代码结构清晰,模块设计合理,扩展性强。它不仅是一个功能完整的应用系统,更是一个技术学习的宝库,涵盖了现代AI应用开发的各个方面:
-
架构设计:微服务友好架构,支持水平扩展
-
性能优化:向量检索优化,缓存策略,并发处理
-
安全考虑:数据加密,访问控制,API防护
-
监控运维:健康检查,性能监控,日志追踪
对于希望深入掌握Spring AI、RAG技术以及现代Web全栈开发的开发者来说,本项目提供了从理论到实践的完整路径。通过研究和使用这个系统,开发者不仅能够获得一个强大的个人知识管理工具,更能在实际编码中深入理解AI应用开发的核心技术和最佳实践。
项目代码完全开源,文档齐全,社区活跃,是进入AI应用开发领域的理想起点和重要参考。无论是用于学习研究、技术评估,还是直接部署使用,都具有极高的价值和实用性。
四、系统实现