


2025 TDBC 大会归来...
近日,参加了由信通院举办的 2025 TDBC 大会,作为年度数据库行业重要会议之一,个人也全程参与了此次大会。会上除了发布数据库产业图谱、数据库研究报告外,还吸引来自行业、产业界的很多老师做了专题分享。内容很多,本文摘取点滴,从市场、趋势、技术、实践等多角度,谈谈我的一些理解。
1. 行业趋势篇
1)市场规模增长与云端差异
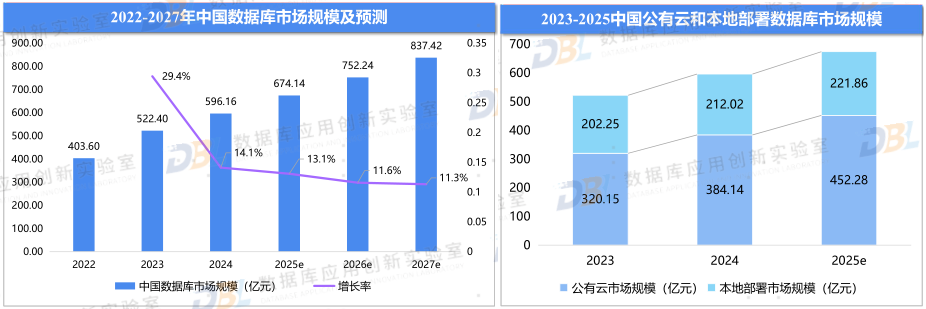
从发布的数据库行业研究报告来看,国内数据库市场仍然保持了高速发展态势,虽然增速有所减缓。其实从全球来看,中国的数据库市场还远远与其地位不符,相信未来会有更大的市场空间。从环境来看,无疑云还是占据了增长的主要部分,本地部署形态增长缓慢。
 图片
图片
2)企业洗牌,行业加速收敛
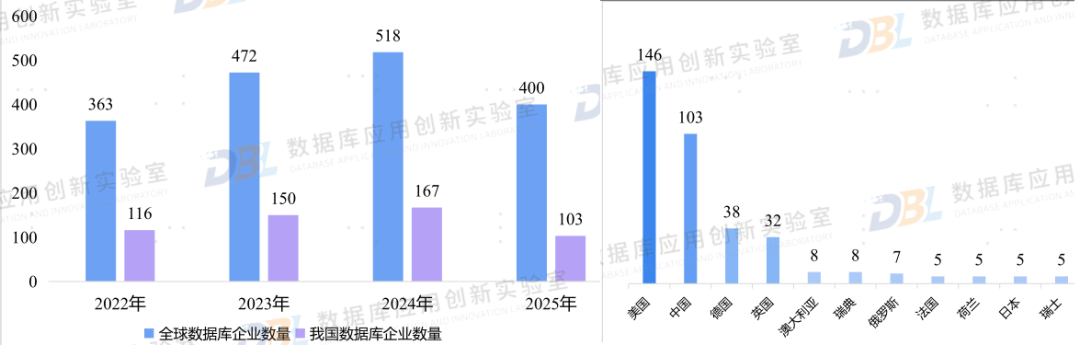
从数据库企业数量来看,正在经历快速收敛的态势。其实近期从很多第三方机构也都获得了类似的信息,国内数据库企业快速减少。随着如国测名单等政策引导相继出台,市场用脚做出了自己的选择。只有那些有实力、肯投入、成规模的企业能够最终活下来。从社会资源集约化配置来看,这也是最优的一种选择。避免国内企业的低层次内圈,鼓励通过市场化手段完成产业重塑。不过对于用户来说,这也预示着一些风险。
 图片
图片
3)AI 正在塑造下一代数据库
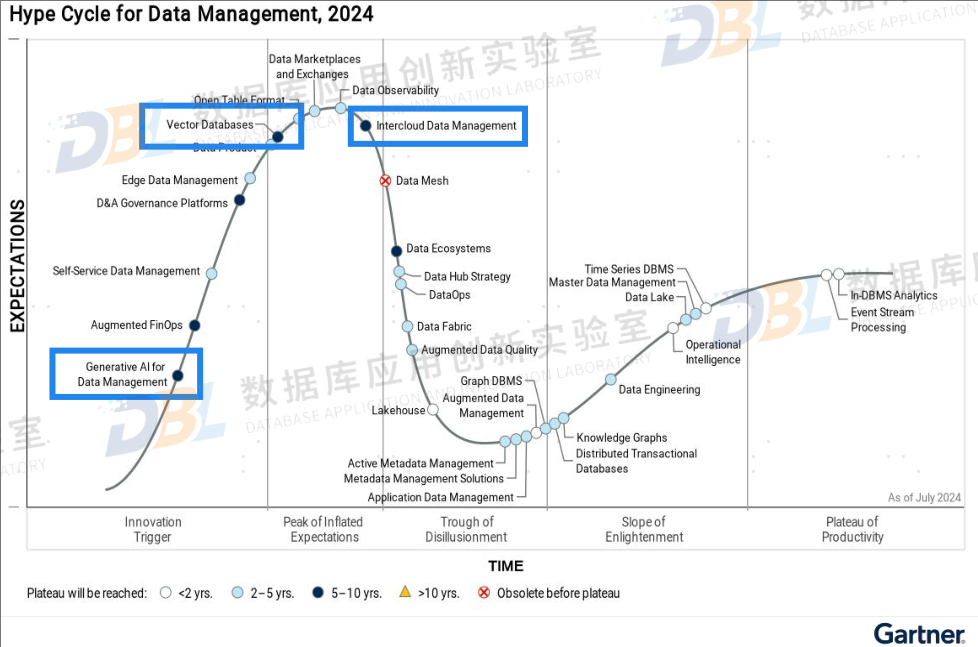
数据库行业正在AI驱动下,即将进入一个新的阶段。从下图最新的Gartner分析报告来看,与AI+Data相关技术正处于快速上升阶段。AI的到来对数据库提出了更多的需求,包括向量多模、智能自治、数据治理等。数据库正在经历一场变革...
 图片
图片
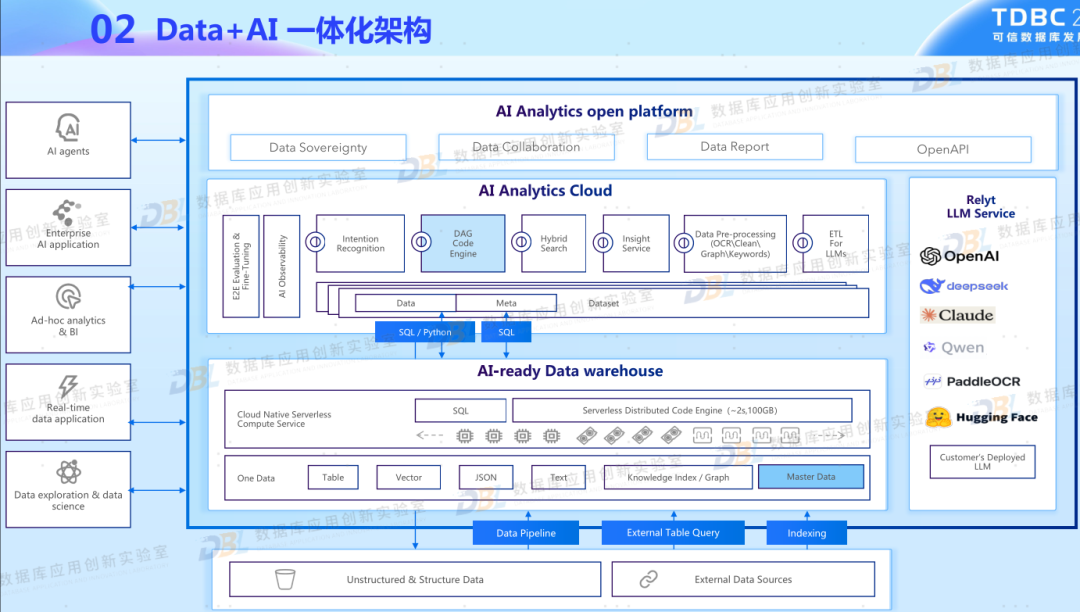
Data 与 AI在未来将更加深入的融合,作为数据的载体,数据库也将提升到数据底座层面(现有所提的AI-Ready,正是这一能力的表现)。数据库正在快速外展它的能力,更好地适应 AI 时代对数据底座的要求。
 图片
图片
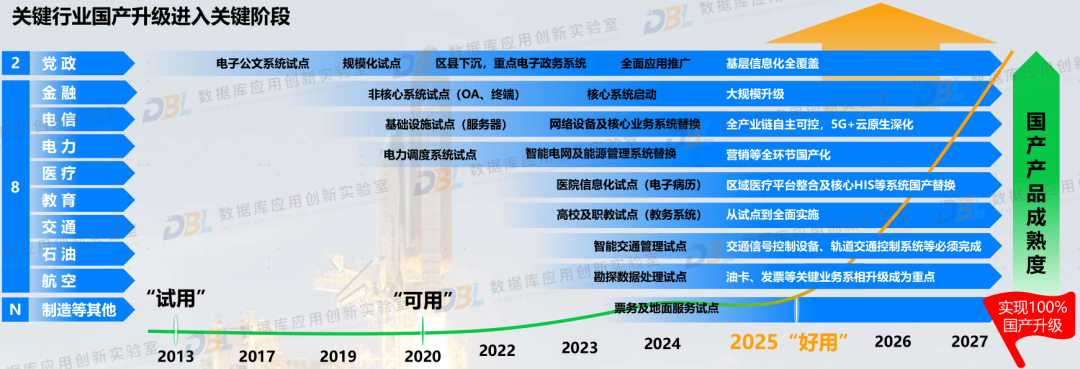
4)信创+AI,经历现在与未来
从数据库发展来看,如下图所示经历了几个阶段。目前我们正处于一个交叉的阶段,一方面以国产信创升级为代表,这几年开始步入关键期(如下下图),国产数据库很多也都吃到了红利;另一方面是AI技术的发展与应用,近一两年开始进入活跃期,正开始影响了数据库行业的整体发展。如果说前者代表着现在,那么后者就预示了未来。国产数据库正以信创为起点,打下基础,为后续AI时代真正带来做好准备。
 图片
图片
 图片
图片
2. 产品技术篇
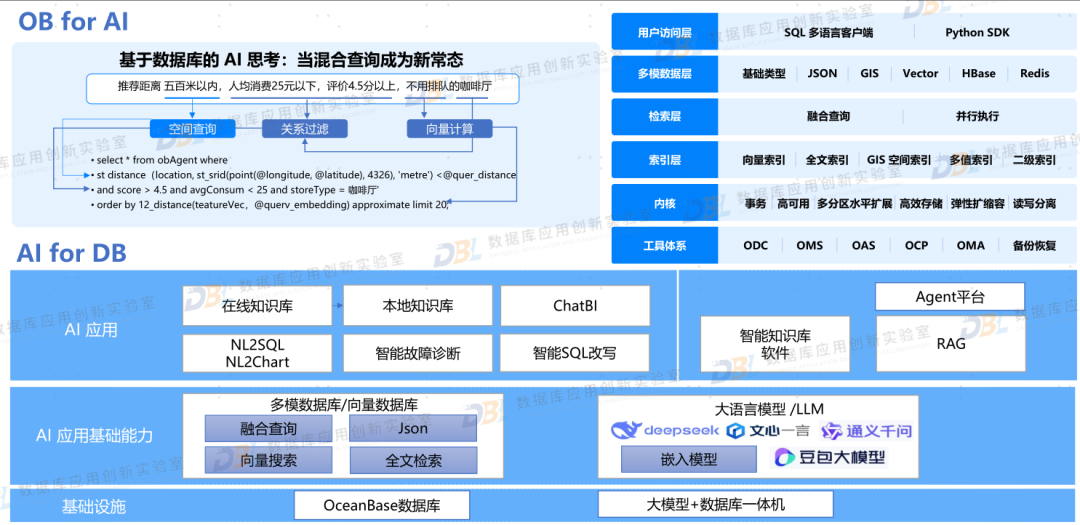
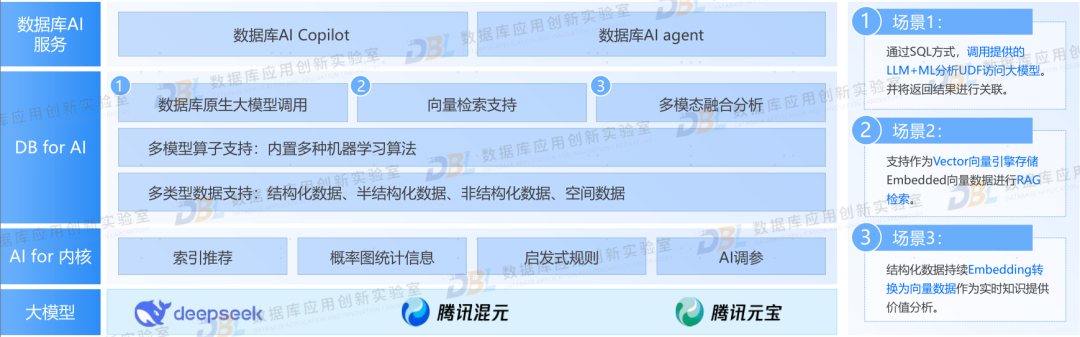
1).AI 重塑数据库企业产品
从数据库企业来说,规划产品的AI能力成为必然,但是各家的投入程度不同。下面几张图是几家数据库企业的AI产品能力。有些仅从AI for DB层面,从外围工具入手尝试使用;有些则从内核入手,快速植入了AI能力,甚至在上层开始支持AI应用。后者已经不能理解是简单的数据库了,可以说是数据智能平台。目前这一领域还是在快速发展之中,各家企业也都在尝试多种可能,有点类似“军备竞赛”的感觉,可以很初级,但是不能没有。
 图片
图片
 图片
图片
 图片
图片
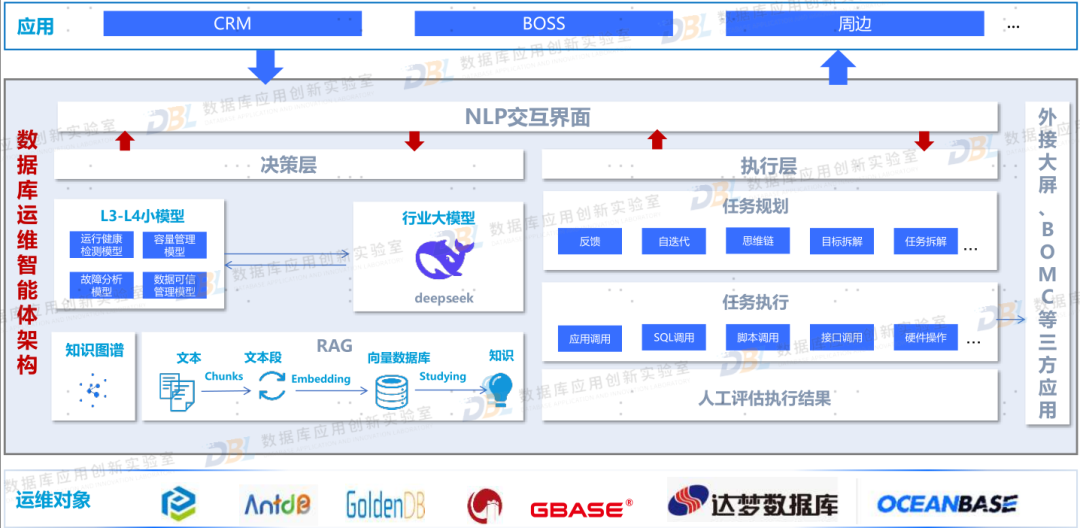
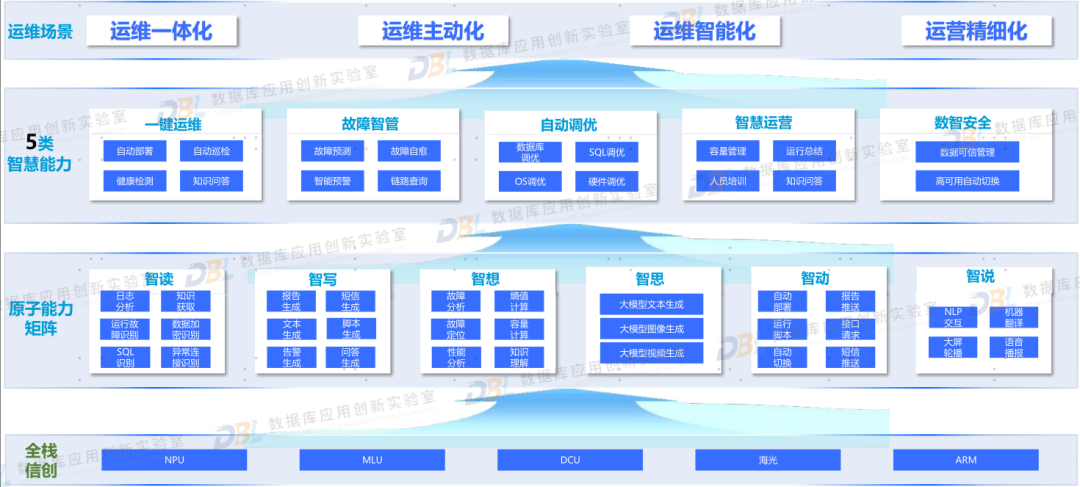
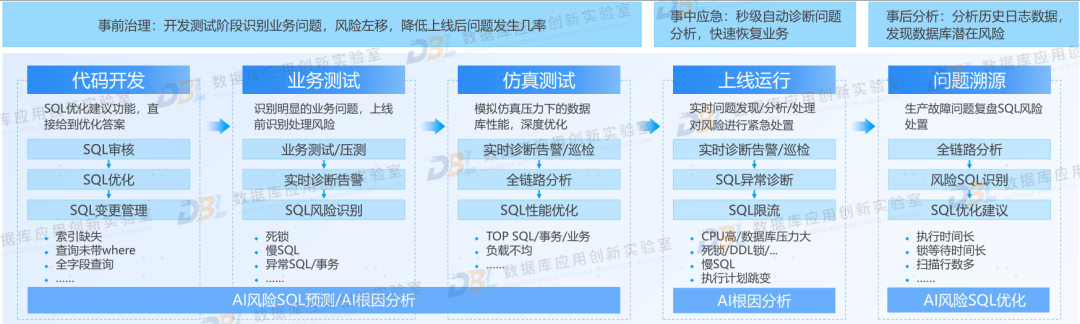
2)AI 赋能企业数据库使用
从甲方用户来讲,AI 更多是赋能数据库的使用。无论是之前的数据库使用者、开发者,都可以从AI中受益。特别是一些较大的数据库甲方,可以尝试自建数据库智能运维体、智能开发平台等。
 图片
图片
 图片
图片
 图片
图片
 图片
图片
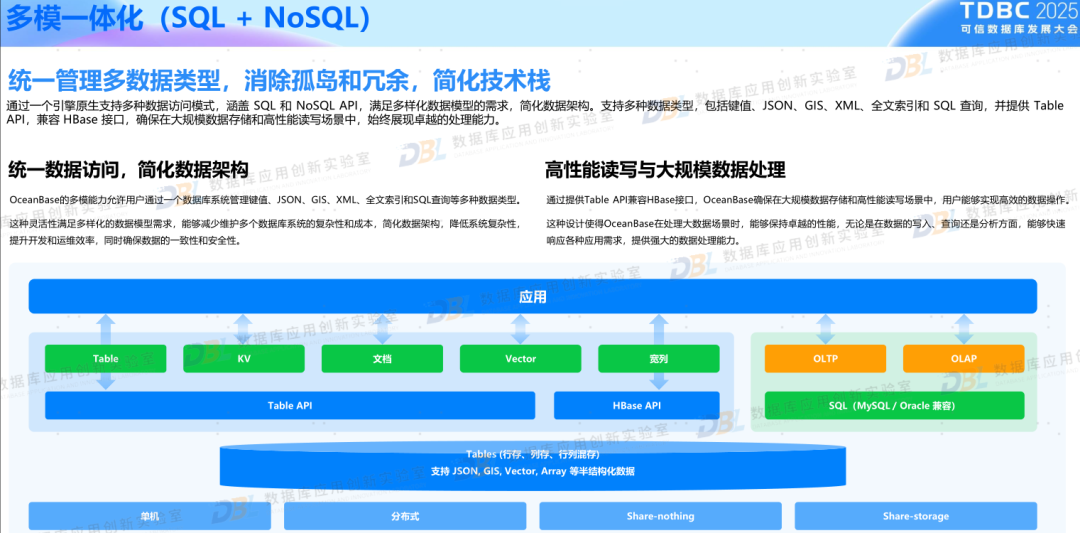
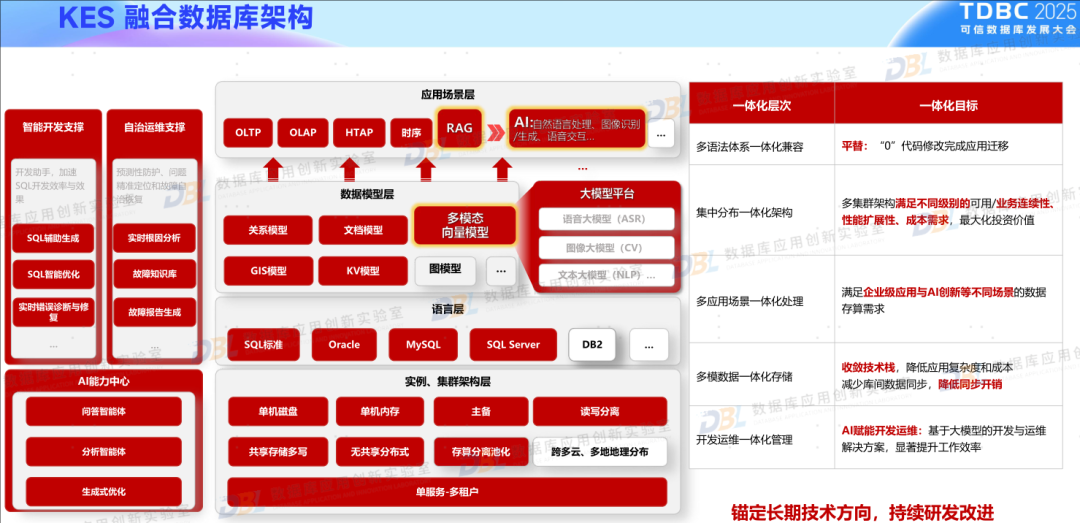
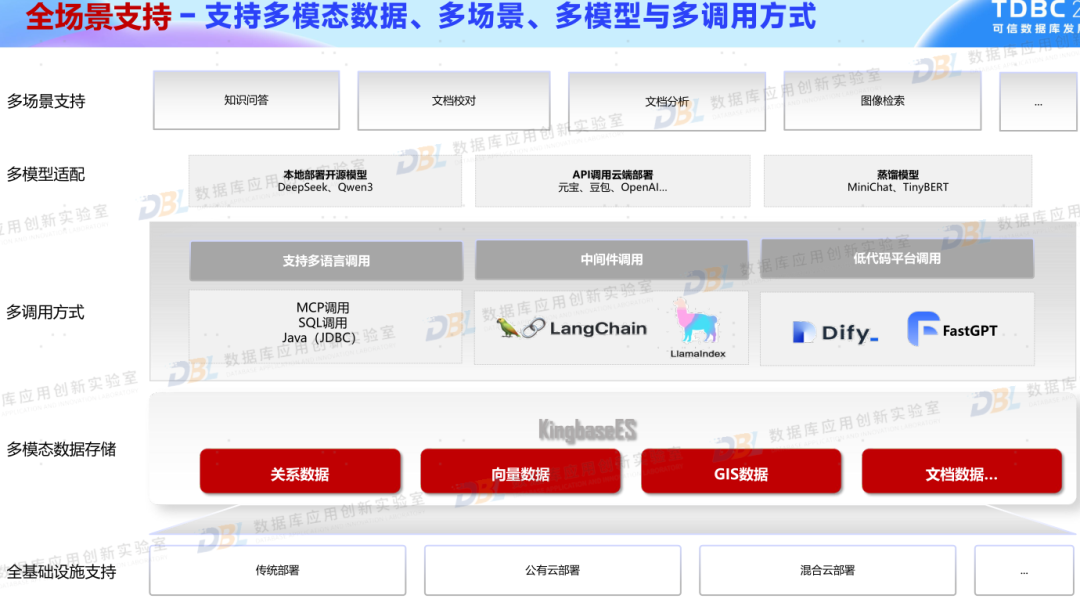
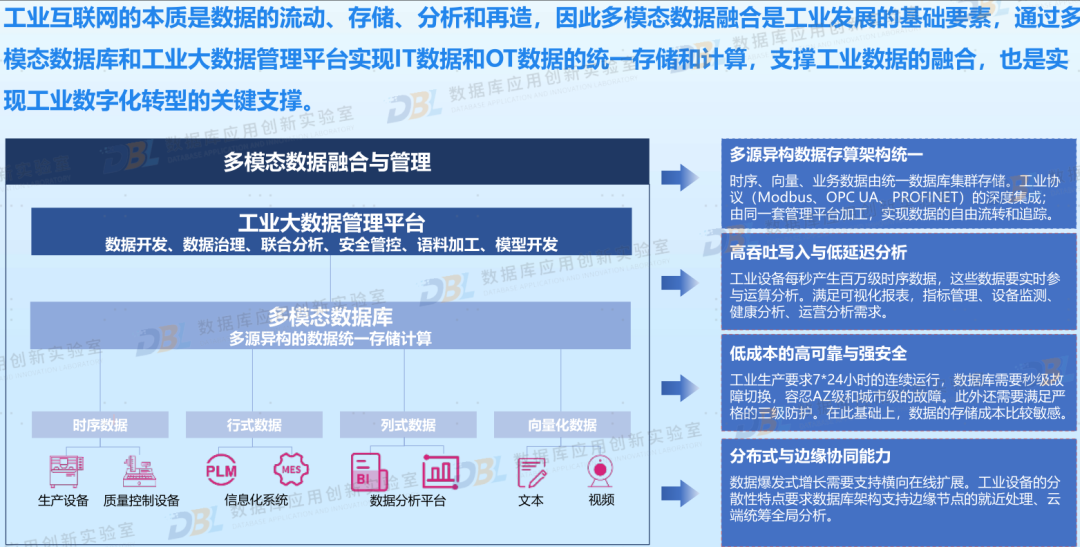
3)一体化/融合成为共识
此次大会上,很多数据库厂商都不约而同提到了融合或一体化的理念,但各家的定义有所区别。有的是架构一体化,包含从单机、主备、共享与分布式;有的是模型一体化,提供多模数据存储与统一访问;有的是计算一体化,将关系查询SQL与智能处理AI结合在一起;有的则强调是场景的一体化,通过单一产品适应不同场景。这其中背后的逻辑都是一样的,那就是尽量简化使用者的技术栈,通过一系列一体化能力,简化选型、简化使用、简化管理。
 图片
图片
 图片
图片
 图片
图片
 图片
图片
 图片
图片
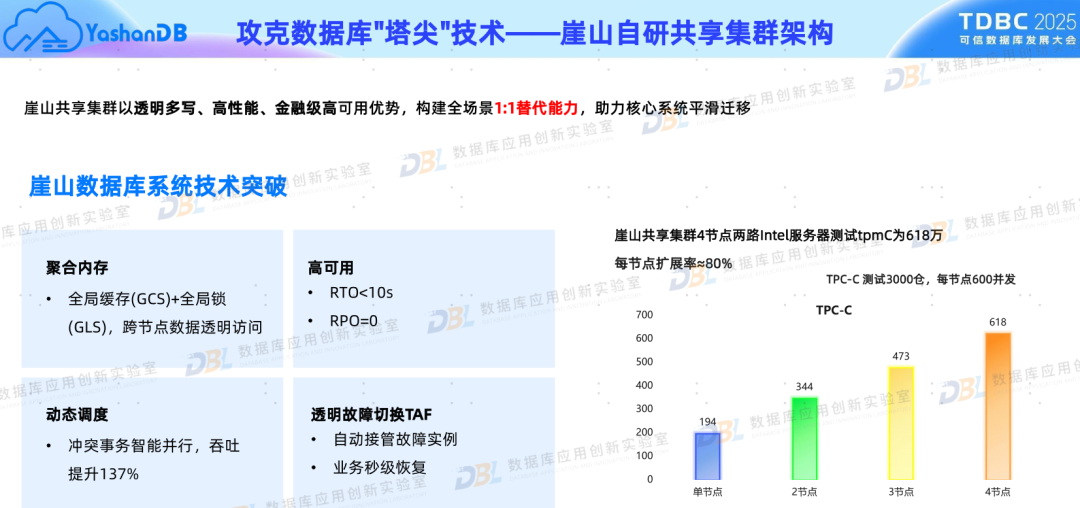
4)共享集群成为“新热点”
作为一种经典架构,相应DBA们对Oracle RAC都非常熟悉。在过去20~30年,大量企业的核心应用都构建于此,曾几何时这一架构被人们忽视了,随着而来的是对分布式架构的追捧,究其根本还是产品能力尚的不足,导致不得不通过分布式架构来解决内核能力的不足。近两年来,一批国产数据库厂商开始发力,在共享存储集群领域获得突破,后者正成为除超大规模外的更普惠、更具性价比的解决方案。
 图片
图片
 图片
图片
 图片
图片
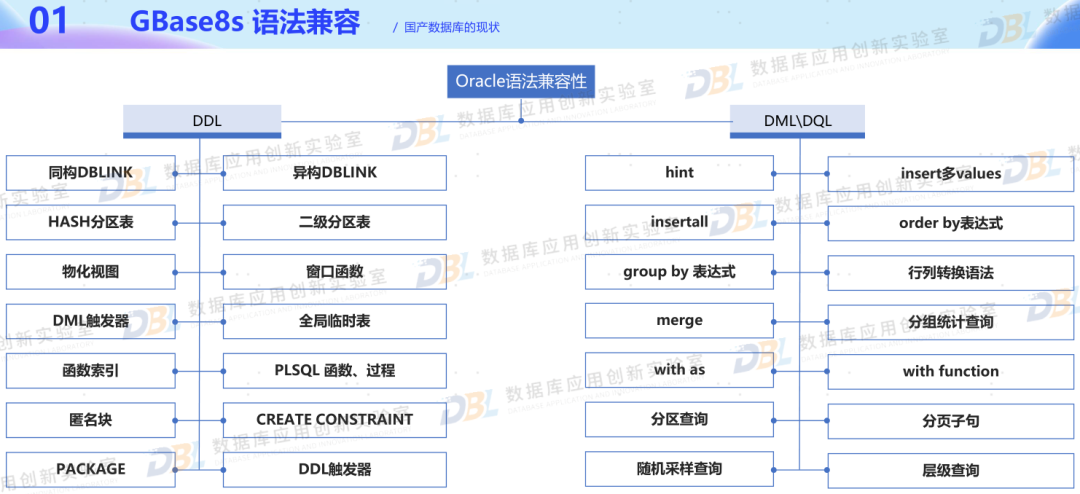
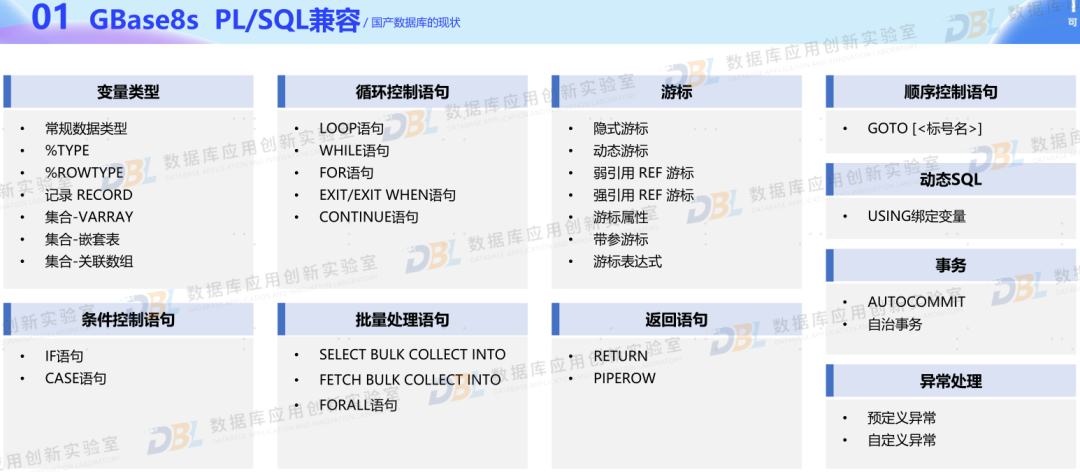
5)兼容性,形似容易神似难
几乎所有厂商都谈到了兼容性,并且都罗列出了兼容能力。这里有一个误区,就是兼容性本身就没有标准范围,大家各自谈到的兼容性外延各不同。常见的就是语法兼容性(包括类型、函数、过程等),还有则是更高层级的语义兼容、生态兼容,甚至还包括不算兼容的兼容性能力(如性能不衰退等等)。比较可喜的是,各家一方面都比较重视兼容性,一方面也都通过工具等手段将不兼容的情况提前识别出来。那么从用户角度来讲,要有一个清醒的认识,就是没有两款产品是完全兼容的,不兼容的情况是一定,要做好不兼容的各种预案,包括预留必要的资源来改造。
 图片
图片
 图片
图片
 图片
图片
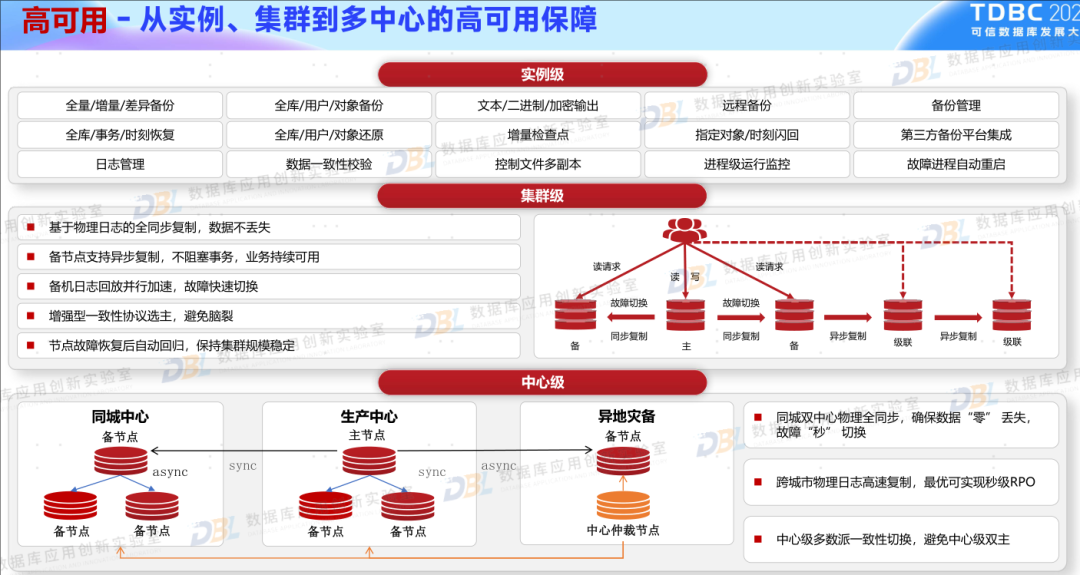
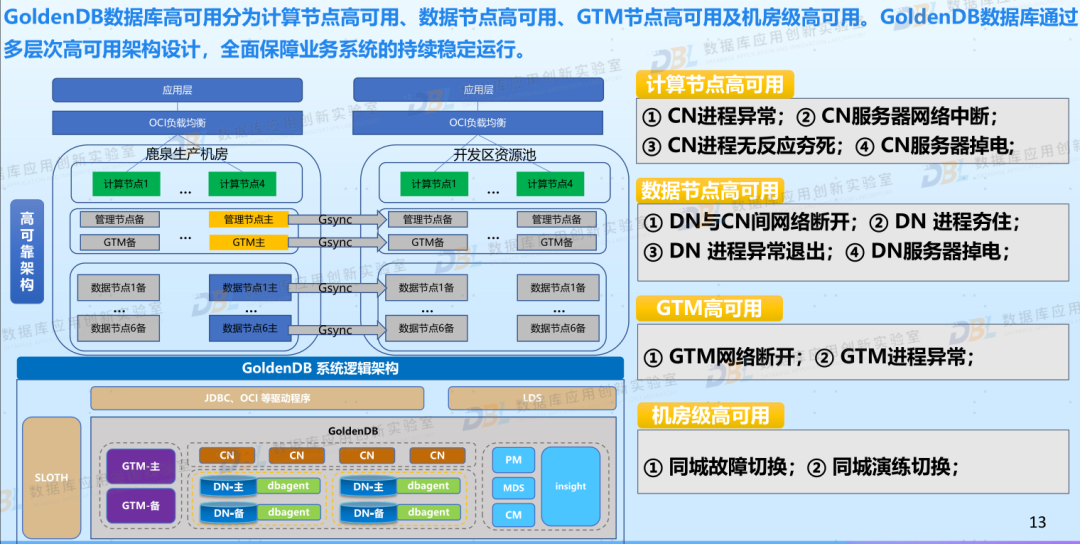
6)高可用,老生常谈的问题
高可用是数据库的基础能力之一,可以说是老生常谈,但有不能忽略。特别是在企业的核心业务替换中,高可用是最不能被忽略的评估项。下面几图就是厂商谈到的自己全方位的高可用能力。
 图片
图片
 图片
图片
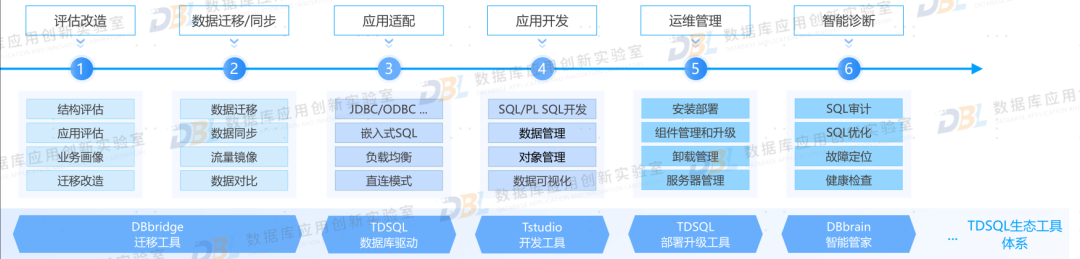
7)产品体系,从能用到好用
随着国产数据库使用不断深化,厂商已经从独立产品的构建,演变为体系化的产品布局。用户想使用好数据库,不能仅仅满足于提供一个单品,更要更为强调体系、乃至生态的作用。下图正是厂商构建的数据库全生命周期的产品家族,满足从选型评估、迁移同步、开发优化、运维管理、诊断排障等,覆盖全场景的产品系列。同时也有很多第三方的厂商也发力于此,提供满足多种数据库的此类能力。
 图片
图片
 图片
图片
3. 生产实践篇
1)产品选型,从经验到体系
随着用户对国产数据库使用深入,各家也都逐渐摸索出选型的评估方法。如果说原来更多靠案例、靠口碑,现在则开始依靠评估体系。随着厂商数量的快速收敛,未来选型方面会逐步简化,头部趋势开始明朗。后续用户会逐步根据自身情况,构建起多层次、多架构的自有技术栈选型方案。
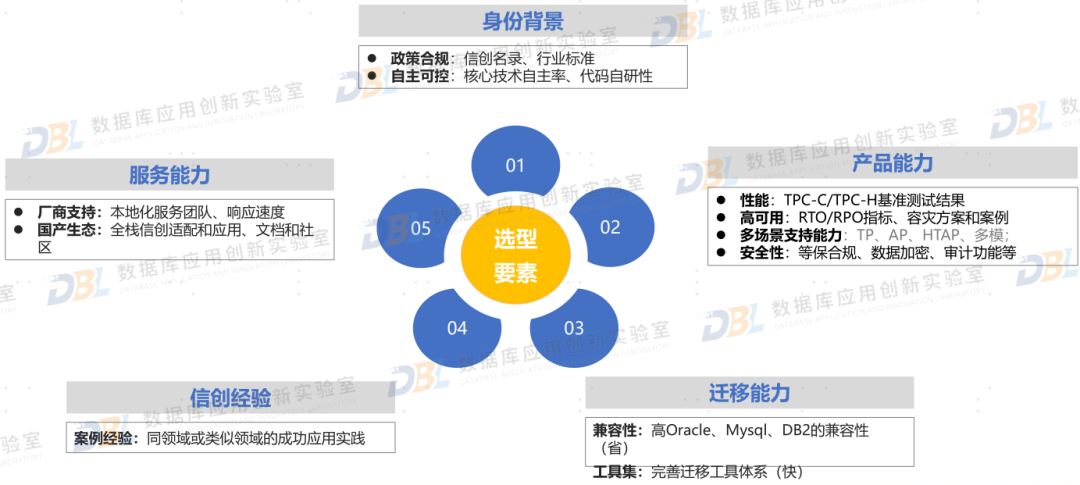 图片
图片
 图片
图片
 图片
图片
2)系统上线,走好最后一公里
原来曾写过一篇文章,谈到走好信创最后一公里的问题,其核心数据库的替换,特别是最后面临割接上线、双轨并行等问题。各家厂商都经历了大量案例实践,总结出一系列方法来帮助用户快速落地。其实从用户角度来讲,一个完善的从评估、验证、适配、改造、测试、迁移、并轨、割接的整体方案,是非常有意义的。这也是厂商从简单的产品PK,逐步过渡到方案比拼,回归到用户关注的核心问题,如何平滑顺利上线。
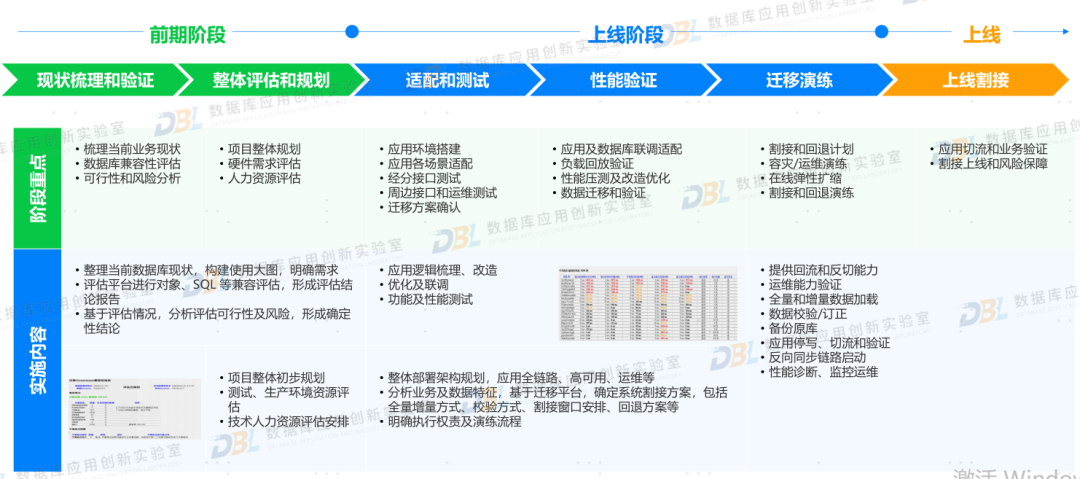 图片
图片
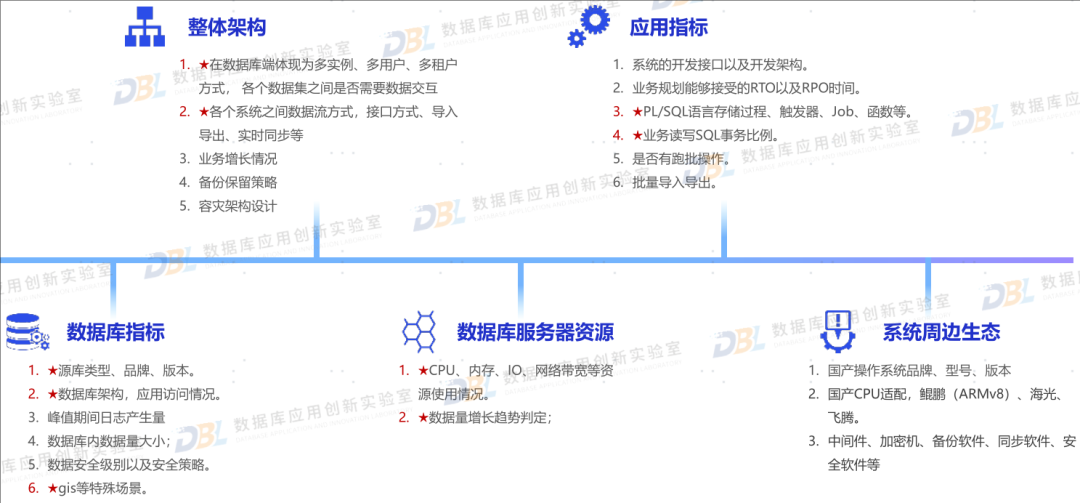 图片
图片
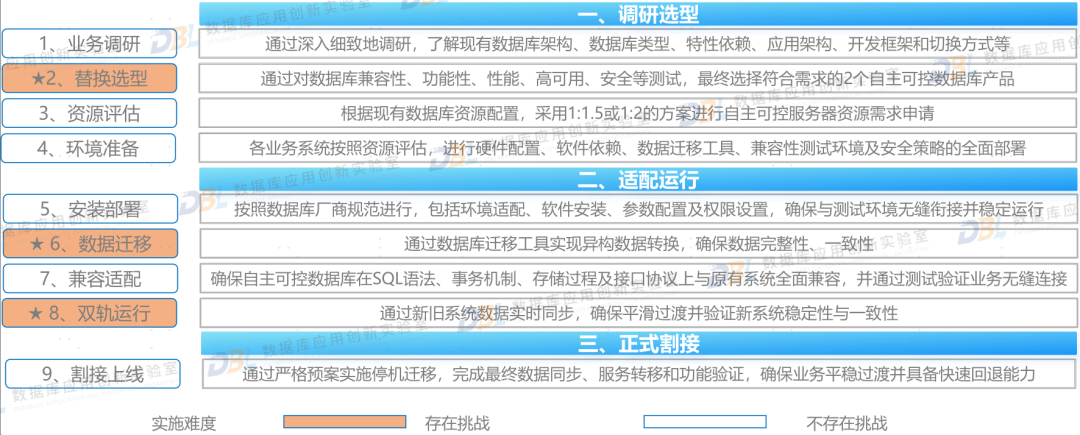 图片
图片
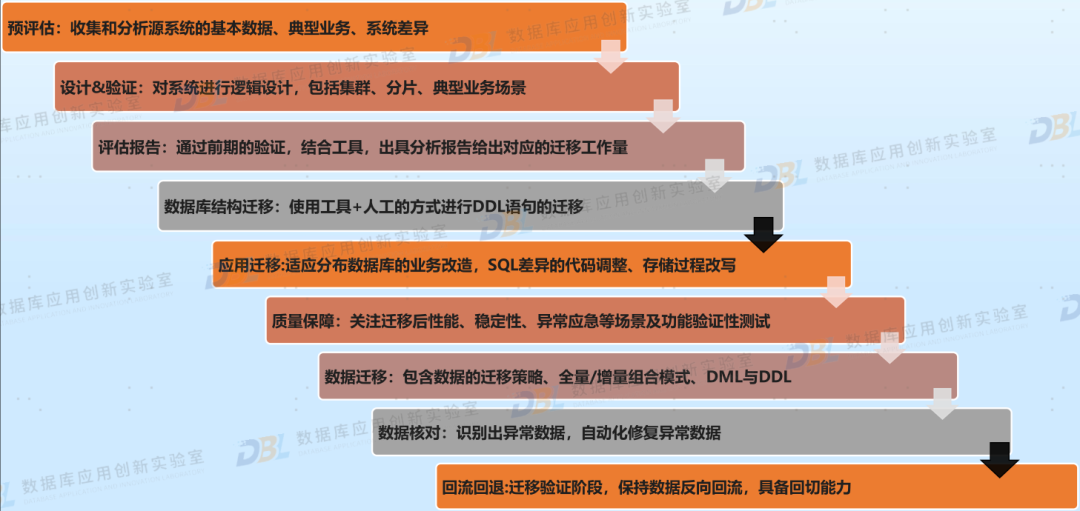 图片
图片
3)其他:分片、跑批、迁移
下面是在生产实践中一些零散的总结,包括如何做数据分片,如何提升跑批性能,如何完成迁移及回退等。这些都是在实践中的宝贵经验,也值得同业者来学习借鉴。
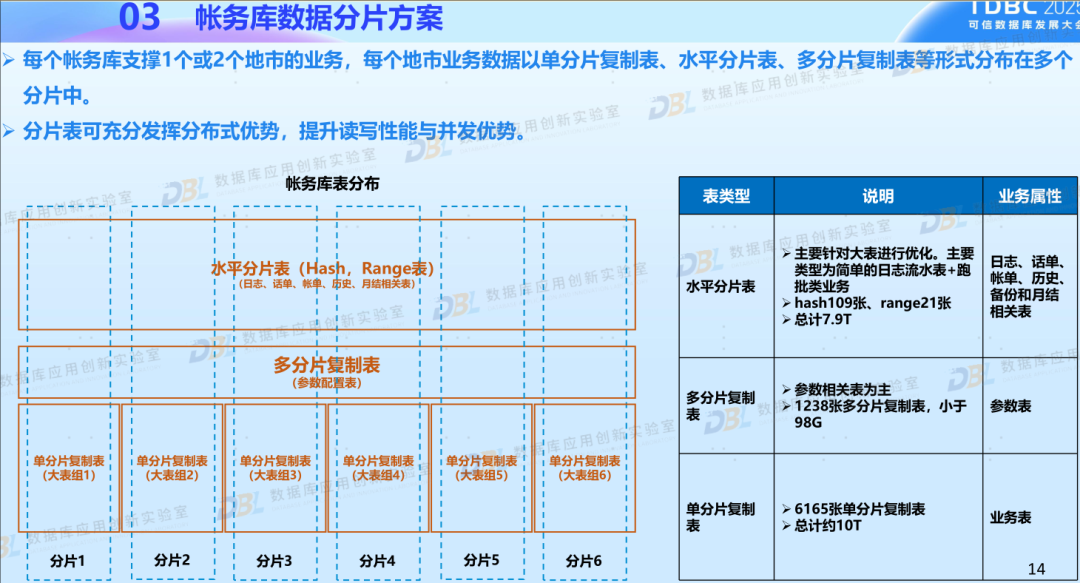 图片
图片
 图片
图片
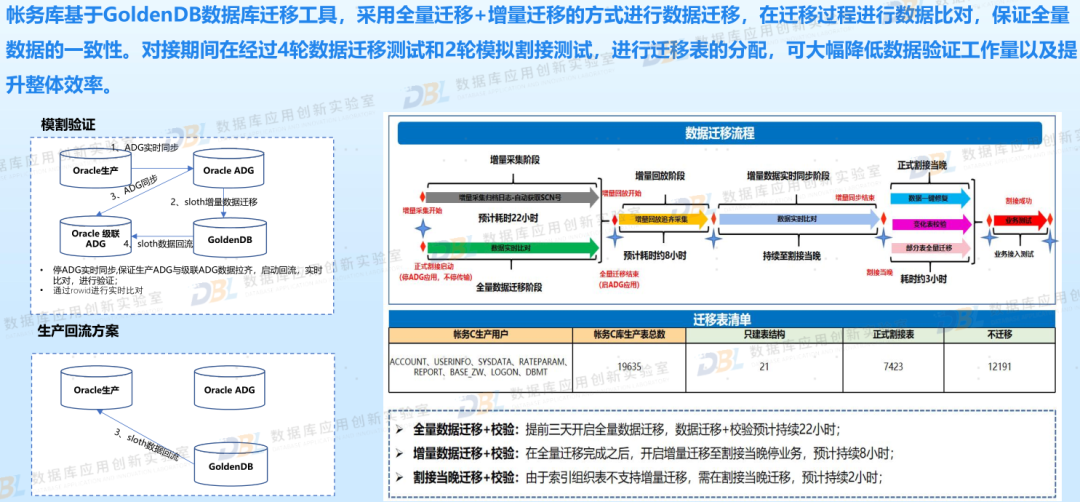 图片
图片









