vLLM-Omni CLI工具使用:从安装到高级功能的完整指南
vLLM-Omni CLI工具是一个强大的命令行界面,专门为高效的多模态模型推理而设计。作为vLLM-Omni框架的核心组件,它提供了简单直观的方式来启动和管理各种AI模型服务,包括文本生成、图像生成、图像编辑等多种功能。本指南将带你从基础安装到高级功能,全面掌握这个强大工具的使用方法。
【免费下载链接】vllm-omni A framework for efficient model inference with omni-modality models  项目地址: https://gitcode.com/GitHub_Trending/vl/vllm-omni
项目地址: https://gitcode.com/GitHub_Trending/vl/vllm-omni
🚀 快速安装步骤
要开始使用vLLM-Omni CLI工具,首先需要安装整个框架:
git clone https://gitcode.com/GitHub_Trending/vl/vllm-omni
cd vllm-omni
pip install -e .
这个安装过程会自动配置所有必要的依赖项,包括CLI工具的核心组件。
📋 基础CLI命令使用
启动多模态LLM服务
使用vllm serve命令结合--omni标志来启动多模态模型服务:
# 启动Qwen2.5-Omni模型服务
vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091
# 启动Qwen3-Omni模型服务
vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
CLI工具会自动检测模型类型并配置相应的服务端点。对于LLM模型,它会自动启用/v1/chat/completions接口,让你可以通过标准API格式进行调用。
启动扩散模型服务
对于图像生成和编辑模型,同样使用相同的命令格式:
# 启动文本到图像生成服务
vllm serve Qwen/Qwen-Image --omni --port 8091
# 启动图像编辑服务
vllm serve Qwen/Qwen-Image-Edit --omni --port 8092
⚡ 高级功能配置
性能优化参数
vLLM-Omni CLI提供了丰富的性能优化选项:
# 启用Ulysses序列并行加速
vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2
# 配置缓存后端
vllm serve Qwen/Qwen-Image --omni --port 8091 --cache-backend cache_dit
阶段配置文件支持
对于复杂的多阶段模型,可以使用阶段配置文件:
vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091 --stage-configs-path /path/to/stage_configs_file
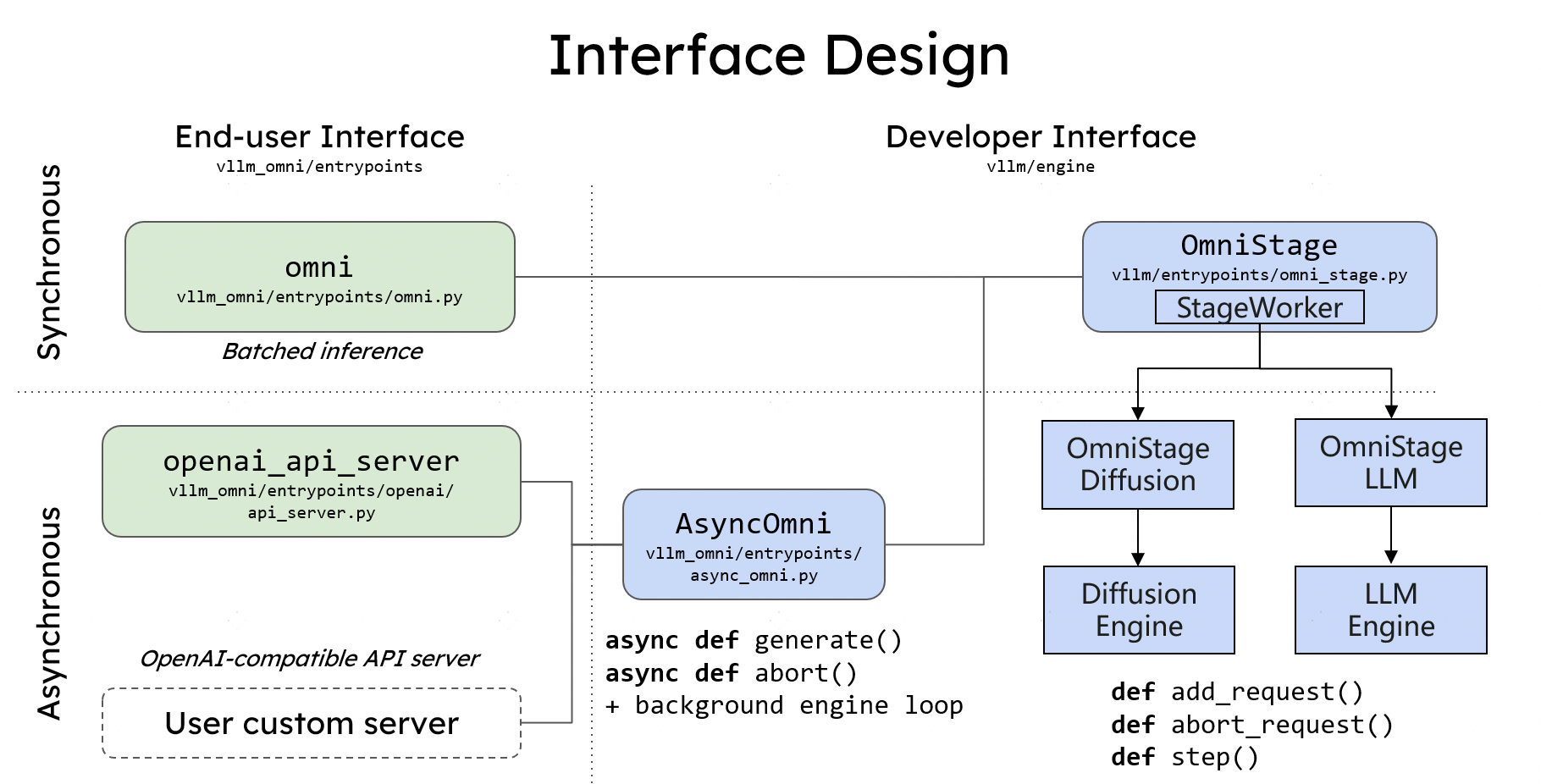
🔧 核心CLI组件解析
vLLM-Omni的CLI系统主要包含以下几个关键组件:
- 主入口模块:vllm_omni/entrypoints/cli/main.py - 负责拦截和解析vLLM命令
- 服务命令模块:vllm_omni/entrypoints/cli/serve.py - 实现
serve子命令的所有功能 - 参数解析系统 - 基于FlexibleArgumentParser的灵活参数处理
🎯 实际应用示例
在线服务部署
查看examples/online_serving目录中的完整示例:
# 从示例脚本启动服务
cd examples/online_serving/qwen3_omni
./run_server.sh
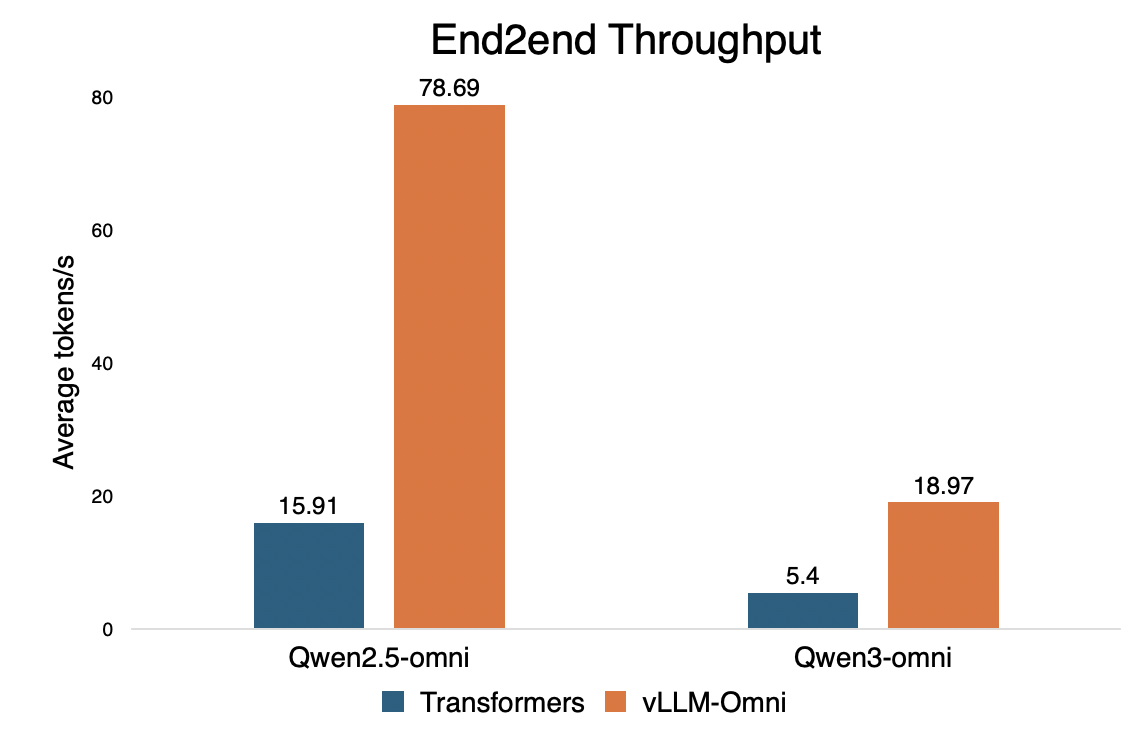
性能对比展示
💡 实用技巧和最佳实践
- 端口选择策略:建议使用8090以上的端口,避免与系统服务冲突
- 模型检测:CLI工具会自动识别模型类型,无需手动指定
- 错误处理:使用
--init-timeout参数设置合理的初始化超时时间 - 日志管理:通过
--log-file参数指定日志文件路径,便于问题排查
🔍 故障排除指南
如果遇到服务启动问题,可以尝试以下步骤:
- 检查模型路径是否正确
- 验证GPU内存是否充足
- 查看详细日志输出定位问题
🚀 下一步学习
掌握了基础CLI工具使用后,你可以进一步探索:
- 异步推理模式配置
- 分布式部署方案
- 自定义模型集成
vLLM-Omni CLI工具的强大功能为多模态AI应用提供了便捷的部署和管理方案。通过本指南的学习,相信你已经能够熟练使用这个工具来构建自己的AI服务了!
【免费下载链接】vllm-omni A framework for efficient model inference with omni-modality models 项目地址: https://gitcode.com/GitHub_Trending/vl/vllm-omni