数信院生信服务器到底有多猛?
生信分析全面向 大规模、多组学、高并发 时代迈进,传统服务器已经越来越难以满足现在的数据分析需求。
科研越来越快、数据越来越大,但算力却常常跟不上。
数信院正式推出目前生信圈顶级配置:数信院 X3 服务器
-
CPU:AMD EPYC 9965
-
内存:DDR5 6400 高频内存
-
GPU:RTX 5090
-
硬盘:U.2 企业级 NVMe 固态
核心算力:AMD EPYC 9965 + DDR5 6400
AMD EPYC 9965 是 AMD 第五代 EPYC(霄龙)家族中的高端服务器处理器,基于最新 Zen 5 架构,主打超高多线程吞吐和能效优化,主要面向数据中心、云计算平台和高密度 HPC / AI 场景,是当前 x86 服务器 CPU 里的天花板级存在之一。
配合 DDR5 6400 高频大内存,在 HISAT2 比对、samtools sort、featureCounts、单细胞标准化 / PCA / 聚类等典型「内存 + I/O 双密集」任务中,可以把多线程潜力充分释放出来。
前面是 Zen 5 架构在疯狂算,后面是一整墙 DDR5 6400 在全速喂数据——这就是生信版「发动机 + 高速公路」的组合。
企业级存储:U.2 NVMe 固态
我们整机采用 U.2 接口的企业级 NVMe 固态硬盘 作为主力存储。
U.2 是面向企业级存储设计的高性能接口标准,通过 PCIe 通道支持 NVMe 协议,可以在保证低时延的同时提供极高的吞吐能力。
相较普通消费级 SSD,U.2 企业级固态具有:
-
✅ 为 服务器场景 优化,长时间高负载读写更稳定
-
✅ 顺序读写与随机 I/O 性能更强,适合 大规模 FASTQ / BAM / count 矩阵 的频繁读写
-
✅ 具备更好的耐久度与掉电保护机制,保障长时间跑 Snakemake、Nextflow 这类流程时数据不翻车
CPU 负责算,DDR5 6400 负责喂数据,U.2 企业级 NVMe 负责把所有中间文件和结果飞快地写下来。
旗舰级 5090 GPU
RTX 5090 是 NVIDIA2025年发布的旗舰级 GPU,专为高性能计算与 AI 工作负载设计。
-
架构:Blackwell (GB202),SM 数量从上一代的 128 提升到 170 个
-
CUDA 核心:21,760 个(首款突破 2 万核心的 GeForce GPU)
-
显存:32GB GDDR7,512 位位宽,带宽 1,792GB/s
-
算力:实测性能比 RTX 4090 普遍提升约 25–30%
在「算力爆炸」的时代里,CPU 负责通用计算,真正把深度学习、生信 AI、可视化推到极限的,是 GPU。
数信院 X3 标配 旗舰级 RTX 5090 GPU,为以下几类任务提供「降维打击式」体验:
-
深度学习 / 大模型微调
-
结构生物学 &大规模推理
-
单细胞 / 空转可视化与降维
-
图像 / 显微 / 组织切片 AI 分析
这是目前生信行业中极少数能同时达到「线程数顶级 + 内存带宽顶级 + GPU 算顶级」 的算力平台,堪称:
「生信界的性能天花板」,「科研算力的顶级形态」。
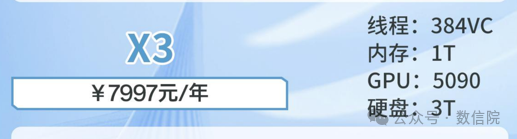
数信院 X3 服务器 · 共享版(入门即顶配)
线程:384 VC、内存:1T、GPU:5090、硬盘:3T
-
已经达到 384 线程 级别
-
1T 大内存适配 bulk / ATAC / scRNA 等绝大多数流程
-
RTX 5090 让单细胞降维、空间组学深度学习彻底「起飞」
入门即是高配,非常适合日常分析 + 高并发排队。
性能测试一
100 样本 bulk RNA-seq 流程对比(友商服务器 vs 数信院 X3 服务器)
在完全相同的流程、相同的参数、相同的输入数据下,对比两台服务器在执行 100个样本、406 个 Snakemake 任务(含 trim_fastq、hisat2 比对、samtools sort、featureCounts 汇总等全过程)时的运行效率差异。
任务级别速度分析
1)trim_fastq 阶段(fastp)
| 服务器 | trim_fastq 阶段总耗时 | 说明 |
|---|---|---|
| 友商服务器 | 20 小时 59 分 30 秒 | 100 个样本全部 fastp 质控完成 |
| 数信院 X3 服务器 | 5 小时 25 分 28 秒 | 同样 100 个样本全流程 |
数信院 X3 服务器快4倍之多
2)Hisat2 比对阶段
| 服务器 | 开始时间 | 结束时间 | 耗时 |
|---|---|---|---|
| 友商服务器 | 19:29:20 | 次日 14:59:18 | 34,198 秒 ≈ 19 小时 29 分 |
| 数信院 X3 服务器 | 13:11:01 | 18:06:59 | 17,758 秒 ≈ 4 小时 56 分 |
数信院 X3 服务器快4倍之多
3)samtools sort + index 阶段
| 服务器 | 开始时间 | 结束时间 | 耗时 |
|---|---|---|---|
| 友商服务器 | 20:27:57 | 次日 14:59:18 | 18 小时 31 分 |
| 数信院 X3 服务器 | 13:46:03 | 18:06:59 | 4 小时 21 分 |
在 I/O 与计算都很吃力的排序 + 建索引阶段,数信院 X3 服务器依旧保持约 5倍提速
I/O 吞吐和多线程调度优势非常明显。
4)featureCounts 定量阶段
| 服务器 | 开始时间 | 结束时间 | 耗时 |
|---|---|---|---|
| 友商服务器 | 20:41:32 | 次日 14:59:18 | 18 小时 17 分 |
| 数信院 X3 服务器 | 13:52:06 | 18:06:59 | 4 小时 14 分 |
定量阶段同样稳定在 约5倍速度差距,
真正做到了从头到尾都「持续快」,而不是只在某一个步骤快。
汇总所有阶段耗时
友商服务器总耗时
| 阶段 | 耗时 |
|---|---|
| trim_fastq | 20.99 小时 |
| hisat2 | 19.48 小时 |
| sort + index | 18.51 小时 |
| featureCounts | 18.29 小时 |
| 总耗时 | ≈ 60–62 小时 |
数信院 X3 服务器总耗时
| 阶段 | 耗时 |
|---|---|
| trim_fastq | 5.42 小时 |
| hisat2 | 4.93 小时 |
| sort + index | 4.35 小时 |
| featureCounts | 4.25 小时 |
| 总耗时 | ≈ 10–11 小时 |
在 100 个样本、406 个任务的 bulk RNA-seq 流程中,数信院 X3 服务器将整体时间直接缩短6倍之多。
性能测试二
单细胞 RNA-seq 全流程(Scanpy / AnnData)对比
使用同一套单细胞分析流水线(AnnData + Scanpy),在同一份大规模单细胞数据上,对比:
-
友商服务器(低负载)
-
数信院 X3 服务器
1)50% 采样单细胞测试
-
友商服务器 总耗时:582.44 分钟 ≈ 9.7 小时
-
数信院 X3 服务器 总耗时:53.12 分钟 ≈ 0.9 小时
提速约 11 倍。
其中关键步骤对比(50% 采样):
-
标准化:62.7 min → 6.16 min(约 10 倍)
-
特征选择:281.42 min → 6.16 min(约 45 倍)
-
PCA:100.88 min → 5.77 min(约 17 倍)
-
聚类:134.06 min → 33.94 min(约 4 倍)
2)100% 全量单细胞测试
-
友商服务器 总耗时:901 分钟 ≈ 15 小时
-
数信院 X3 服务器 总耗时:52.43 分钟 ≈ 0.87 小时
提速约 17 倍。
关键步骤对比(100% 采样):
-
标准化:126.57 min → 4.45 min(≈ 28 倍)
-
特征选择:440.27 min → 5.02 min(≈ 88 倍)
-
PCA:113.93 min → 11.96 min(≈ 10 倍)
-
聚类:213.46 min → 28.93 min(≈ 7 倍)
在单细胞全流程中,数信院 X3 服务器不仅把整体时间从「一整天」压缩到「一节课」, 至在核心步骤上做到 10~80 倍级别的加速,综合效率远超 5 倍。
性能测试三
重测序 WGS + SVcalling 对比
重点关注 SVcalling 阶段,因为它是整个流程里最耗时、最吃内存的一步。
1)数信院 X3:相同线程下,数据量翻倍,SVcalling 不再“翻倍变慢”
下表以 数信院 X3 服务器 为例,展示在相同线程下,随着数据量从 23G → 42.5G → 87.5G 增大时,SVcalling 的耗时变化(单位:分钟):
| 服务器 | 样本大小 | SVcalling 时间 | 每 GB 所需时间(min / GB) |
|---|---|---|---|
| X3 | 23G | 289 | ≈ 12.6 |
| X3 | 42.5G | 411 | ≈ 9.7 |
| X3 | 87.5G | 526.6 | ≈ 6.0 |
可以看到:
-
数据从 23G → 42.5G(≈1.85 倍)时,SVcalling 时间只从 289 → 411 分钟(≈1.42 倍);
-
数据从 42.5G → 87.5G(≈2.06 倍)时,时间只从 411 → 526.6 分钟(≈1.28 倍);
-
数据从 23G 提升到 87.5G,接近 4 倍放大,但 SVcalling 时间只增加了不到 1 倍。
2)友商服务器 vs 数信院 X3
按 SVcalling 阶段 & 每 GB 时间算一算
| 服务器 | 样本大小 | SVcalling 时间 | 每 GB 时间(min / GB) |
|---|---|---|---|
| 友商 | 10G | 270 | 27.0 |
| 数信院 X3 | 23G | 289 | 12.6 |
| 数信院 X3 | 87.5G | 526.6 | 6.0 |
友商服务器还在为 10G 数据的 SVcalling 挣扎数小时的时候,数信院 X3 已经在同样时间内轻松拿下 80G 以上的大数据集。
有哪些优势?
-
同样一天时间,可以多跑几倍项目、尝试更多参数组合
-
大样本队列、临床队列、多时间点实验不再被算力「劝退」
-
为未来的 多组学整合、大模型生信应用 提前铺好算力底座
❝不要再抱怨服务器跑得慢了。来试试这台数信院 X3服务器。