从零到一开发 Text-to-SQL MCP 数据查询服务器
本文详细介绍了基于FastMCP框架构建Text-to-SQL服务器的完整过程,包括环境搭建、核心模块开发和安全机制实现。通过Python和MySQL技术栈,实现了自然语言到SQL的安全转换,包含数据库连接管理、权限认证、查询安全检查等功能。该系统可降低数据分析门槛,为非技术用户提供安全的数据库查询服务,适合作为数据平台的基础组件。
引言
在数据驱动的时代,自然语言到 SQL 的转换(Text-to-SQL)技术正变得越来越重要。它允许非技术用户通过自然语言查询数据库,极大降低了数据分析的门槛。本文将详细介绍如何从零开始构建一个基于 FastMCP 框架的 Text-to-SQL 服务器,实现安全、可控的数据库查询服务。
项目概述
我们开发的 Text-to-SQL MCP 服务器是一个基于 Model Context Protocol (MCP) 的安全数据库查询服务。该服务器允许通过自然语言生成 SQL 查询,并在严格的权限控制下执行查询操作,确保数据安全的同时提供便捷的数据访问能力。
核心功能
- • 数据库连接管理:安全的 MySQL 数据库连接和查询
- • 权限认证:基于 RSA 密钥对的 Bearer Token 认证
- • 安全查询:防止 SQL 注入和危险操作的安全检查
- • 表结构查询:获取数据库表列表和表结构信息
- • SQL 执行:安全的 SQL 查询执行,支持结果限制
- • 健康检查:服务状态监控
技术栈
- • Python 3.10+:主要编程语言
- • FastMCP:MCP 服务器框架
- • MySQL:数据库系统
开发环境搭建
1. 项目初始化
首先创建项目目录结构:
mkdir text-to-sql-mcp
cd text-to-sql-mcp
2. 依赖安装
创建 requirements.txt 文件:
fastmcp==2.10.6
python-dotenv==1.1.0
mysql-connector-python==8.2.0
uvicorn==0.24.0
安装依赖:
pip install -r requirements.txt
3. 环境配置
创建 .env.example 文件:
# 数据库配置
DB_HOST=localhost
DB_PORT=3306
DB_USER=your_username
DB_PASSWORD=your_password
DB_NAME=your_database
复制并配置环境变量:
cp .env.example .env
编辑 .env 文件,填入实际的数据库连接信息。
4. 数据库初始化
创建 dataset.sql 文件,包含示例表结构和数据:
CREATE DATABASE IF NOT EXISTS your_database;
USE your_database;
CREATE TABLE `contracts` (
`id` int NOT NULL AUTO_INCREMENT,
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`contract_name` varchar(255) NOT NULL COMMENT '合同名称',
`client_name` varchar(255) NOT NULL COMMENT '客户名称',
`signing_date` varchar(10) NOT NULL COMMENT '签订日期(格式2025-01-01)',
`contract_amount` decimal(12,2) NOT NULL COMMENT '签订金额',
`status` varchar(10) DEFAULT NULL COMMENT '合同状态 executing(履行中)、completed(已完成)',
PRIMARY KEY (`id`),
KEY `idx_signing_date` (`signing_date`)
) ENGINE=InnoDB COMMENT='合同信息表';
INSERT INTO dataset.contracts
(id, created_at, updated_at, contract_name, client_name, signing_date, contract_amount, status)
VALUES(1, '2025-07-21 21:15:25', '2025-07-21 21:20:40', '2023年度IT运维服务合同', '北京智云科技有限公司', '2023-01-10', 150000.00, 'executing');
INSERT INTO dataset.contracts
(id, created_at, updated_at, contract_name, client_name, signing_date, contract_amount, status)
VALUES(2, '2025-07-21 21:15:25', '2025-07-21 21:21:09', '电商平台开发项目', '上海锐创网络有限公司', '2023-02-15', 320000.00, 'completed');
INSERT INTO dataset.contracts
(id, created_at, updated_at, contract_name, client_name, signing_date, contract_amount, status)
VALUES(3, '2025-07-21 21:15:25', '2025-07-21 21:20:40', '办公楼装修工程合同', '广州建工集团有限公司', '2023-03-22', 1850000.50, 'executing');
INSERT INTO dataset.contracts
(id, created_at, updated_at, contract_name, client_name, signing_date, contract_amount, status)
VALUES(4, '2025-07-21 21:15:25', '2025-07-21 21:20:40', '品牌全案营销服务协议', '深圳星耀传媒有限公司', '2023-04-05', 680000.00, 'executing');
INSERT INTO dataset.contracts
(id, created_at, updated_at, contract_name, client_name, signing_date, contract_amount, status)
VALUES(5, '2025-07-21 21:15:25', '2025-07-21 21:20:40', '生产设备采购合同', '成都机械制造厂', '2023-05-18', 2450000.00, 'executing');
核心模块开发
1. 认证模块 (auth_token.py)
认证是安全系统的核心,我们使用 RSA 密钥对实现 JWT Token 认证:
from fastmcp.server.auth import BearerAuthProvider
from fastmcp.server.auth.providers.bearer import RSAKeyPair
def create_auth_components():
# 生成RSA密钥对
key_pair = RSAKeyPair.generate()
# 创建访问令牌
access_token = key_pair.create_token(
subject="58bf32d9-ef25-484f-bb7d-bfc683e5b3eb",
issuer="https://fastmcp.example.com",
audience="data-analysis-mcp",
scopes=["data:read_tables", "data:read_table_data"]
)
# 模拟生成token
print(f'Authorization=Bearer {access_token}')
# 创建认证提供者
auth = BearerAuthProvider(
public_key=key_pair.public_key,
audience="data-analysis-mcp",
)
return auth
关键点:
- • 使用 RSA 非对称加密确保 Token 安全
- • 为 Token 设置特定的 audience 防止跨服务使用
- • 通过 scopes 实现细粒度权限控制
2. 数据库管理模块 (database.py)
数据库管理模块负责所有与数据库的交互:
import os
import mysql.connector
from typing import Optional, Dict, Any, List
class DatabaseManager:
def __init__(self):
self.host = os.getenv('DB_HOST', 'localhost')
self.port = int(os.getenv('DB_PORT', 3306))
self.user = os.getenv('DB_USER')
self.password = os.getenv('DB_PASSWORD')
self.database = os.getenv('DB_NAME')
self.connection = None
def connect(self) -> bool:
try:
self.connection = mysql.connector.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
database=self.database,
charset='utf8mb4'
)
print("✅ 成功连接到数据库: {}".format(self.database))
return True
except Exception as e:
print("❌ 数据库连接失败: {}".format(str(e)))
return False
def execute_query(self, query: str) -> Optional[List[Dict[str, Any]]]:
try:
if not self.connection:
print("❌ 数据库未连接")
return None
cursor = self.connection.cursor(dictionary=True)
cursor.execute(query)
results = cursor.fetchall()
cursor.close()
if results:
converted_results = [self._convert_row_types(row) for row in results]
print("✅ 查询成功,返回 {} 行数据".format(len(converted_results)))
return converted_results
return []
except Exception as e:
print("❌ 查询执行失败: {}".format(str(e)))
return None
def _convert_row_types(self, row: Dict[str, Any]) -> Dict[str, Any]:
"""转换数据类型为JSON可序列化的类型"""
converted = {}
for key, value in row.items():
if value is None:
converted[key] = None
elif isinstance(value, (int, float, str, bool)):
converted[key] = value
elif hasattr(value, 'isoformat'): # datetime objects
converted[key] = value.isoformat()
elif isinstance(value, bytes):
converted[key] = value.decode('utf-8', errors='ignore')
else:
converted[key] = str(value)
return converted
def get_table_info(self, table_name: str) -> Dict[str, Any]:
# 获取表结构
structure_query = f"DESCRIBE {table_name}"
structure_data = self.execute_query(structure_query)
# 获取表数据样本
sample_query = f"SELECT * FROM {table_name} LIMIT 5"
sample_data = self.execute_query(sample_query)
# 获取表统计信息
count_query = f"SELECT COUNT(*) as total_rows FROM {table_name}"
count_data = self.execute_query(count_query)
total_rows = count_data[0]['total_rows'] if count_data and len(count_data) > 0 else 0
return {
'structure': structure_data,
'sample_data': sample_data,
'total_rows': total_rows
}
关键点:
- • 使用连接池管理数据库连接
- • 自动处理数据类型转换,确保 JSON 序列化
- • 提供表结构、样本数据和统计信息的统一接口
3. 主服务器模块 (mcp_server.py)
主服务器模块整合所有功能,提供 MCP 接口:
from fastmcp import FastMCP, Context
from fastmcp.exceptions import ToolError
from fastmcp.server.dependencies import get_access_token, AccessToken
from dotenv import load_dotenv
from database import DatabaseManager
from auth_token import create_auth_components
load_dotenv()
db_manager = None
auth = create_auth_components()
mcp = FastMCP(name="data-analysis-mcp", auth=auth)
def initialize_services():
global db_manager
if db_manager is None:
db_manager = DatabaseManager()
if not db_manager.connect():
raise Exception("数据库连接失败")
def get_validated_access_token() -> AccessToken:
try:
access_token = get_access_token()
if access_token is None:
raise ToolError("未提供访问令牌或令牌无效")
return access_token
except Exception as e:
raise ToolError(f"权限验证失败: {str(e)}")
def check_permissions(access_token: AccessToken, required_scopes: list) -> None:
if not access_token.scopes:
raise ToolError("用户没有任何权限")
missing_scopes = [scope for scope in required_scopes if scope not in access_token.scopes]
if missing_scopes:
raise ToolError(f"权限不足:需要以下权限: {', '.join(missing_scopes)}")
@mcp.tool
async def get_database_tables(ctx: Context) -> Dict[str, Any]:
"""获取数据库中所有表的列表"""
access_token = get_validated_access_token()
check_permissions(access_token, ["data:read_tables"])
try:
initialize_services()
tables = db_manager.get_all_tables()
return {
"user_id": access_token.client_id,
"tables": tables,
"total_tables": len(tables),
"message": f"成功获取 {len(tables)} 个表"
}
except Exception as e:
raise ToolError(f"获取表列表失败: {str(e)}")
@mcp.tool
async def execute_sql_query(ctx: Context, sql_query: str, limit: int = 100) -> Dict[str, Any]:
"""执行SQL查询"""
access_token = get_validated_access_token()
check_permissions(access_token, ["data:read_table_data"])
# 安全检查:禁止危险操作
dangerous_keywords = ['drop', 'delete', 'update', 'insert', 'alter', 'create', 'truncate']
if any(keyword in sql_query.lower() for keyword in dangerous_keywords):
raise ToolError("安全限制:不允许执行修改数据的操作")
try:
initialize_services()
# 添加LIMIT限制
if 'limit' not in sql_query.lower():
sql_query = f"{sql_query.rstrip(';')} LIMIT {limit}"
result_data = db_manager.execute_query(sql_query)
if result_data is None:
raise ToolError("查询执行失败")
columns = list(result_data[0].keys()) if result_data else []
return {
"user_id": access_token.client_id,
"query": sql_query,
"row_count": len(result_data),
"columns": columns,
"data": result_data,
"message": f"查询成功,返回 {len(result_data)} 行数据"
}
except Exception as e:
raise ToolError(f"查询执行失败: {str(e)}")
@mcp.tool
async def health_check(ctx: Context) -> Dict[str, Any]:
"""健康检查"""
try:
initialize_services()
return {
"status": "healthy",
"database_connected": db_manager is not None,
"message": "服务运行正常"
}
except Exception as e:
return {
"status": "unhealthy",
"database_connected": False,
"message": f"服务异常: {str(e)}"
}
关键点:
- • 使用 FastMCP 框架快速创建 MCP 服务器
- • 集中处理权限验证逻辑
- • 为每个工具实现详细的安全检查
- • 提供统一的错误处理机制
安全机制实现
1. 权限认证系统
我们实现了基于 RSA 密钥对的 JWT Token 认证系统:
- • 密钥生成:使用 RSA 非对称加密生成密钥对
- • Token 创建:包含用户 ID、权限范围等信息
- • 权限验证:每个工具执行前验证用户权限
权限级别:
- •
data:read_tables:读取表结构权限 - •
data:read_table_data:读取表数据权限
2. 查询安全检查
为防止 SQL 注入和危险操作,我们实现了多层安全检查:
# 禁止危险操作
dangerous_keywords = ['drop', 'delete', 'update', 'insert', 'alter', 'create', 'truncate']
if any(keyword in sql_query.lower() for keyword in dangerous_keywords):
raise ToolError("安全限制:不允许执行修改数据的操作")
# 敏感数据检查
sensitive_keywords = ['password', 'secret', 'token', 'private', 'confidential']
is_sensitive = any(keyword in sql_query.lower() for keyword in sensitive_keywords)
if is_sensitive:
check_permissions(access_token, ["data:read_table_data"])
# 自动添加LIMIT限制
if 'limit' not in sql_query.lower():
sql_query = f"{sql_query.rstrip(';')} LIMIT {limit}"
3. 数据库安全最佳实践
- • 最小权限原则:数据库用户只授予必要的查询权限
- • 连接加密:生产环境使用 SSL/TLS 加密数据库连接
- • 查询限制:自动限制返回行数,防止大量数据泄露
- • 敏感数据保护:对包含敏感关键词的查询进行额外权限检查
服务启动与测试
1. 启动服务
运行主服务器文件:
python mcp_server.py
服务启动后会显示:
Authorization=Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9...
🚀 启动MCP数据查询服务器...
📍 地址: http://127.0.0.1:8000
📋 可用工具:
- health_check: 健康检查
- get_user_permissions: 获取用户权限
- get_database_tables: 获取数据库表列表
- get_table_structure: 获取表结构
- execute_sql_query: 执行SQL查询
- generate_sql_from_question: 自然语言生成SQL
- analyze_query_result: 查询结果分析
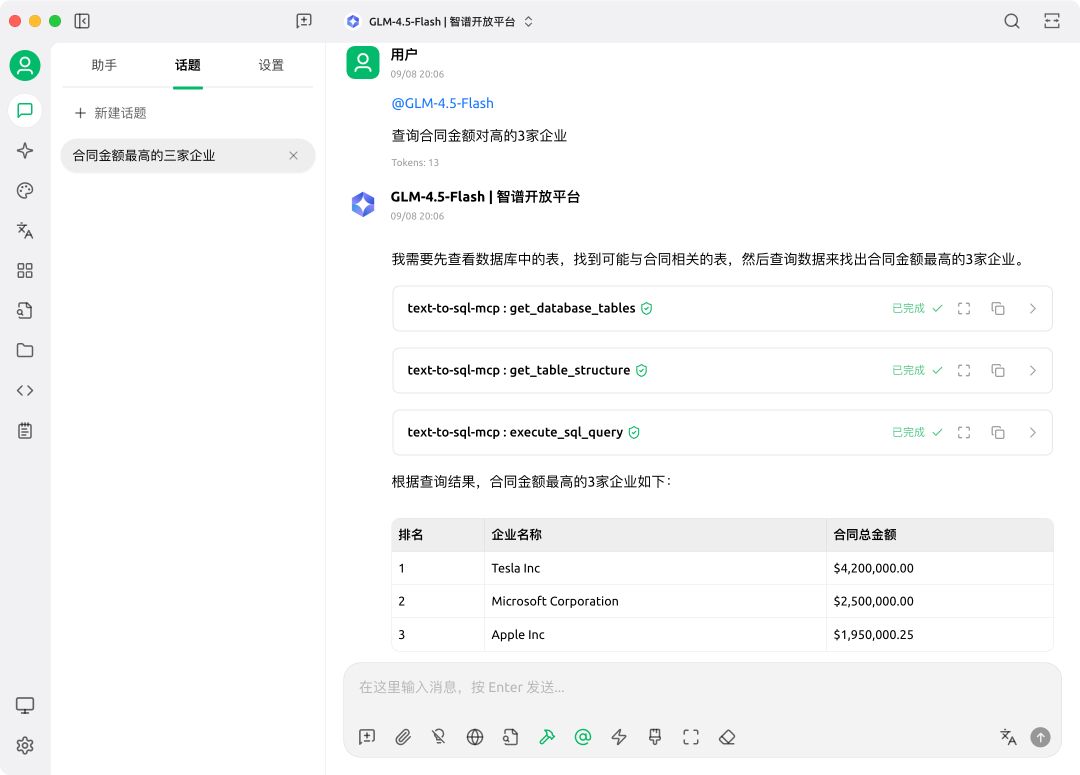
2. 测试工具功能
使用 Cherry Studio 客户端测试各个工具
MCP 服务器端配置:
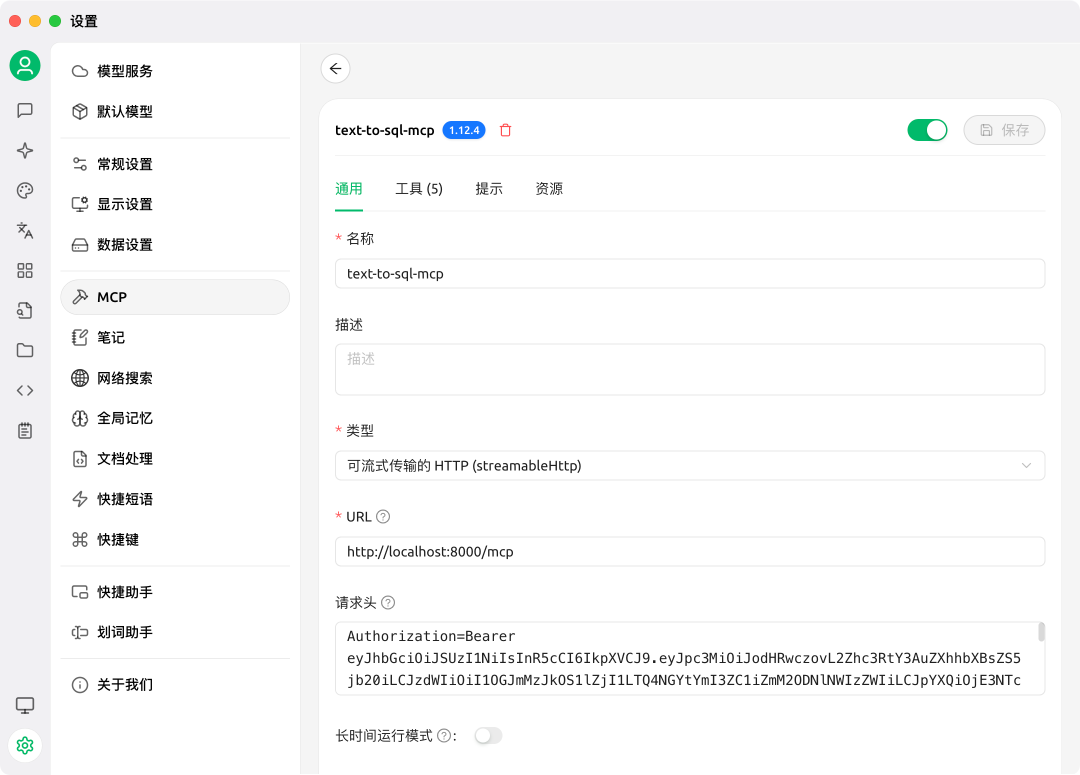
工具列表:

数据查询流程:
-
- 查询数据库有哪些表
-
- 根据表信息,判断需要从那个表中查询数据,然后调用工具获取表信息
-
- 根据表信息,拼装成SQL发送到服务器执行,得到数据结果。
-
总结
本文详细介绍了从零开始构建 Text-to-SQL MCP 服务器的完整过程,包括环境搭建、核心模块开发、安全机制实现和服务测试。通过 FastMCP 框架,我们快速构建了一个安全、可控的数据库查询服务,实现了自然语言到 SQL 的转换功能。
在实际开发过程中,我们重点关注了安全性和可控性,通过多层安全检查和细粒度权限控制,确保数据安全的同时提供便捷的数据访问能力。该服务器可以作为数据平台的基础组件,为各种应用提供安全的数据查询接口。
未来,我们可以进一步扩展该服务,支持更多数据库类型、增强自然语言理解能力、优化查询性能,并集成更多数据分析功能,打造更强大的数据服务平台。
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!
深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。
【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!
👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。
抓住机遇,开启你的AI学习之旅!