国产海光DCU服务器使用vllm部署Qwen32B模型
1 前言
首先需要确认服务器已经有DTK(DCU Toolkit),类似于 NVIDIA CUDA Toolkit 的角色,但这是适配 DCU(基于 ROCm 架构)的版本。
通过目录名查看
ls -l /opt/ | grep dtk输出示例
drwxr-xr-x 10 root root 4096 10月 22 10:15 dtk-24.04.3
lrwxrwxrwx 1 root root 12 10月 22 10:20 dtk -> /opt/dtk-24.04.3版本号是24.04.3,说明已经安装了这个版本的DTK
没有的话需要自行安装
2 环境搭建
Anaconda下载,新建虚拟环境教程很多,自行搜索,直接进入虚拟环境开始
conda activate 环境名
要在海光服务器搭建类似于NVIDIA的GPU环境,需要在光合开发者社区下载对应的pytorch等包
这里因为DTK版本是24.04.3,要下载和其对应的包,选择DAS1.3版本

1、pytorch安装
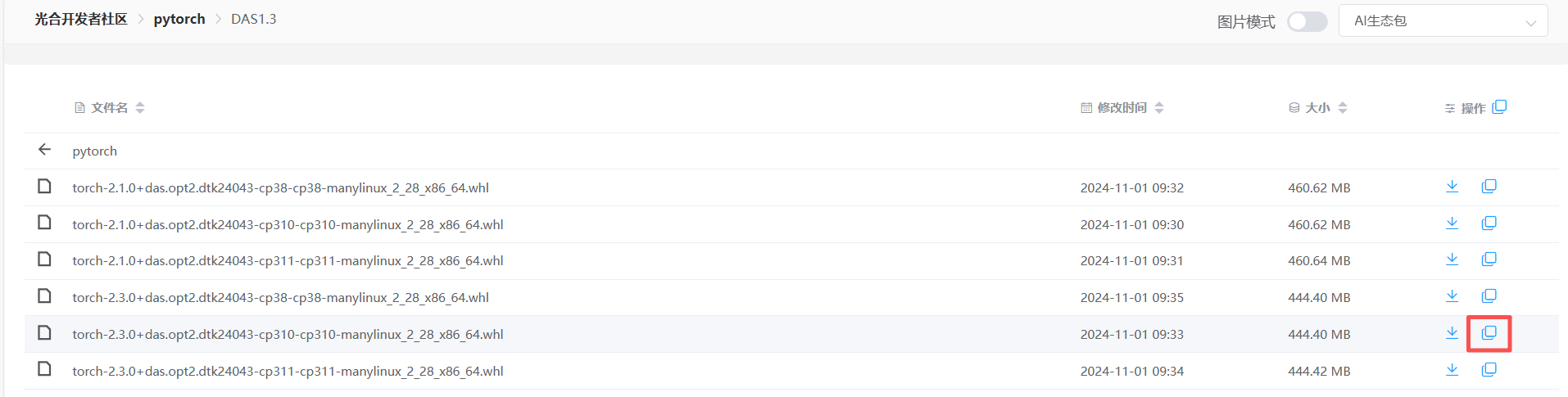
选择对应版本的pytorch包,右侧可以生成直链,然后用wget下载
wget https://download.sourcefind.cn:65024/directlink/4/pytorch/DAS1.3/torch-2.3.0+das.opt2.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl下载完成后,进入模型下载到的那个目录,用pip安装
pip torch-2.3.0+das.opt2.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl如果速度慢可以更换清华镜像源
2、其它依赖包安装
用上述同样的方法下载安装其它需要的包,包括torchvision-0.16.0+das.opt1.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl(不确定有没有用,最好装上),flash_attn-2.6.1+das.opt2.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl,lmslim-0.1.2+das.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl,vllm-0.6.2+das.opt1.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl
注意:这里flash_attn这个包有opt1和opt2两个版本,如果后续安装报关于这个包的错,可尝试重新安装另一个opt的版本。另外要确保每个包都是dtk24043版本,不然会有冲突!
3、验证
安装完torch和torchvision包后,可以用以下命令验证一下显卡可用性
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"如果能输出版本号和True,说明安装成功,可以成功调用显卡
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
2.3.0
True
3 模型下载
从魔搭社区下载需要的模型,这里以Qwen2.5-32B-Instruct模型为例,找到模型后点击下载模型,如下所示
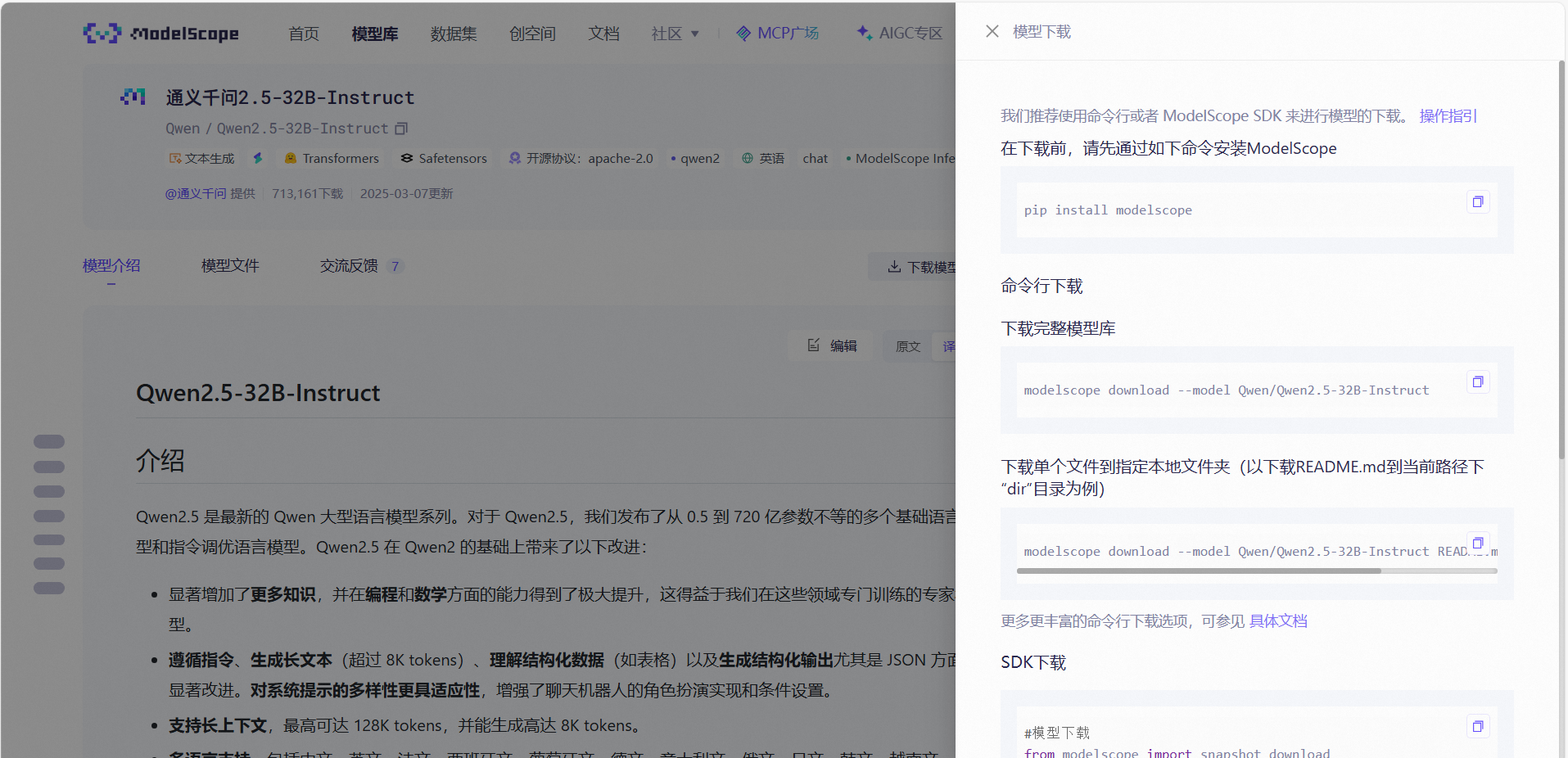
1、按照提示进行,首先安装ModelScope(在虚拟环境内)
pip install modelscope2、下载完整模型
modelscope download --model Qwen/Qwen2.5-32B-Instruct如果要指定文件夹,可以通过以下命令指定路径
modelscope download --model Qwen/Qwen2.5-32B-Instruct --local_dir 指定路径3、检查模型
切换到指定路径下,用ls命令查看文件夹内容,有以下输出表示模型下载成功
config.json model-00001-of-00017.safetensors model-00006-of-00017.safetensors model-00011-of-00017.safetensors model-00016-of-00017.safetensors tokenizer.json
configuration.json model-00002-of-00017.safetensors model-00007-of-00017.safetensors model-00012-of-00017.safetensors model-00017-of-00017.safetensors vocab.json
generation_config.json model-00003-of-00017.safetensors model-00008-of-00017.safetensors model-00013-of-00017.safetensors model.safetensors.index.json
LICENSE model-00004-of-00017.safetensors model-00009-of-00017.safetensors model-00014-of-00017.safetensors README.md
merges.txt model-00005-of-00017.safetensors model-00010-of-00017.safetensors model-00015-of-00017.safetensors tokenizer_config.json
注意:不同版本的模型需要的驱动版本也不同,例如Qwen3系列的模型就需要vllm>=0.8.5,而这个版本的vllm又需要其它配套版本的包支持(包括DTK),所以根据自己需要的模型提前找好对应的包安装。
4 加载模型
到这一步基本马上就要成功了!用以下命令启动模型
python -m vllm.entrypoints.openai.api_server
--model 模型路径
--served-model-name 模型名称
--host 0.0.0.0
--port 端口
--tensor-parallel-size 8这里tensor-parallel-size表示并行卡数,根据自己设备的卡的数量修改
经过一长串的输出后,如果能看到以下信息说明启动成功,可以进行调用了