Linux 2.6 内核 O(1) 调度队列深度解析:为什么它能实现常数时间调度?

🎬 博主简介:

文章目录
- 前言:
- 一. 核心数据结构:runqueue 与 优先级组织
- 1.1 运行队列(runqueue):每个 CPU 的 “专属调度池”
- 1.2 优先级数组(prio_array):按优先级分组的进程容器
- 二. O (1) 调度的核心流程:活跃队列与过期队列的切换
- 2.1 步骤 1:进程入队 —— 按优先级插入对应链表
- 2.2 步骤 2:调度决策 —— 位图快速查找最高优先级进程
- 2.3 步骤 3:队列切换 —— 当活跃队列为空时
- 三. 优先级管理:如何保证高优先级的先执行?为什么不直接修改 PRI 值?
- 四. 本文全部知识点整体图解和部分源码(重要,仔细看)
- 结语:
前言:
在 Linux 2.6 内核之前,进程调度采用的是
O (n)算法 —— 调度器需要遍历所有就绪进程才能找到优先级最高的那个,进程数量越多,调度效率越低,严重影响多任务场景的性能。而 2.6 内核引入的O (1)调度算法,彻底解决了这一痛点,其核心就是设计了高效的调度队列结构,让调度器无论面对多少进程,都能在常数时间内找到最优进程,大幅提升了系统吞吐量。本文从调度队列的核心数据结构、工作流程、优先级管理三个维度,拆解 O (1) 调度队列的设计精髓,帮你理解 “常数时间调度” 的底层逻辑,看透 Linux 内核的高效调度秘诀。
一. 核心数据结构:runqueue 与 优先级组织
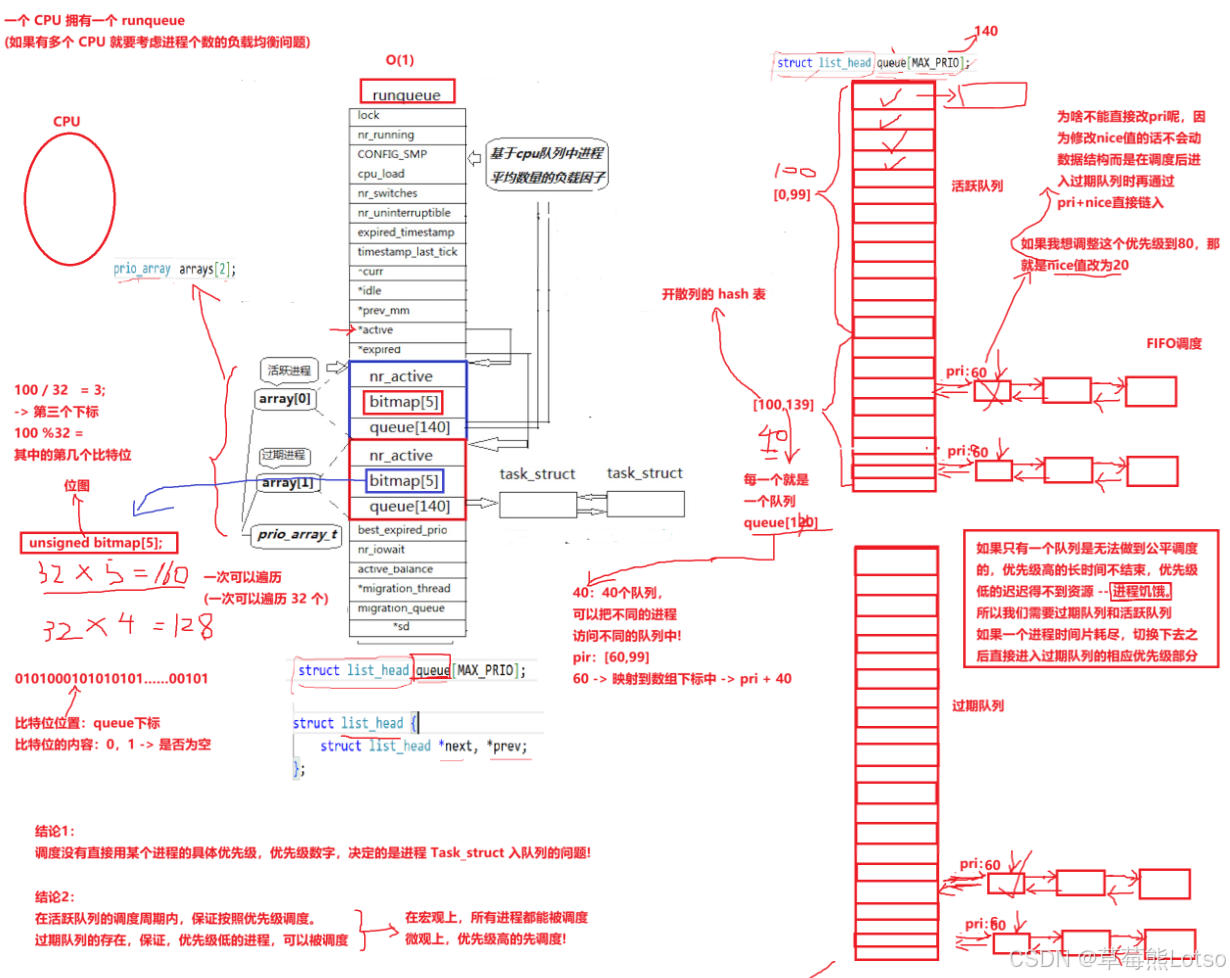
要实现 O(1) 调度,关键在于 "如何快速找到最高优先级的就绪进程"。Linux 2.6 内核通过 runqueue(运行队列)和 prio_array(优先级数组)的组合结构,完美解决了这个问题
1.1 运行队列(runqueue):每个 CPU 的 “专属调度池”
每个 CPU 核心对应一个独立的 runqueue,避免多 CPU 间的调度竞争,提升并行效率;
核心字段解析:
active:活跃队列,存储时间片未耗尽的就绪进程;expired:过期队列,存储时间片已耗尽的进程;arrays[2]:包含两个prio_array结构,分别对应active和expired队列;bitmap:优先级位图,用于快速标记非空优先级队列(核心优化点)。
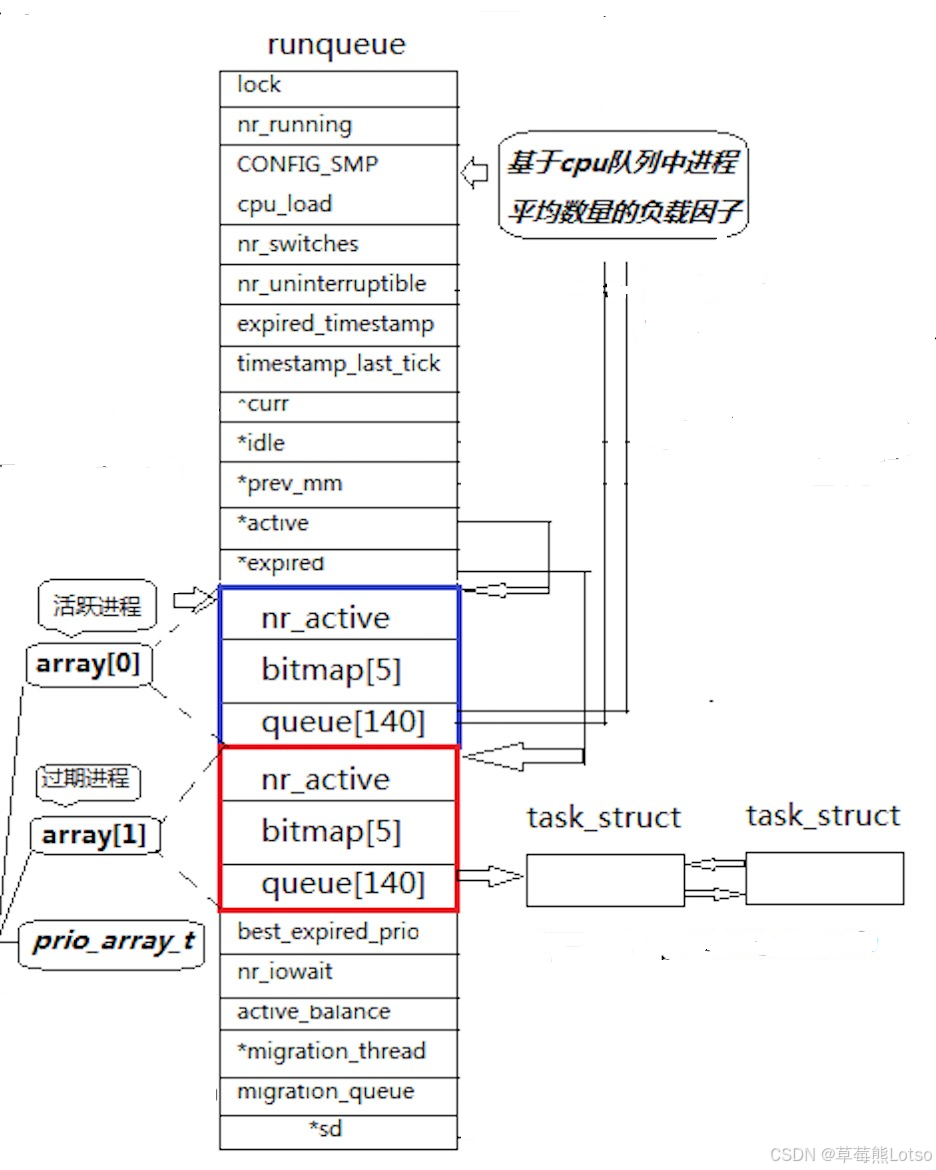
1.2 优先级数组(prio_array):按优先级分组的进程容器
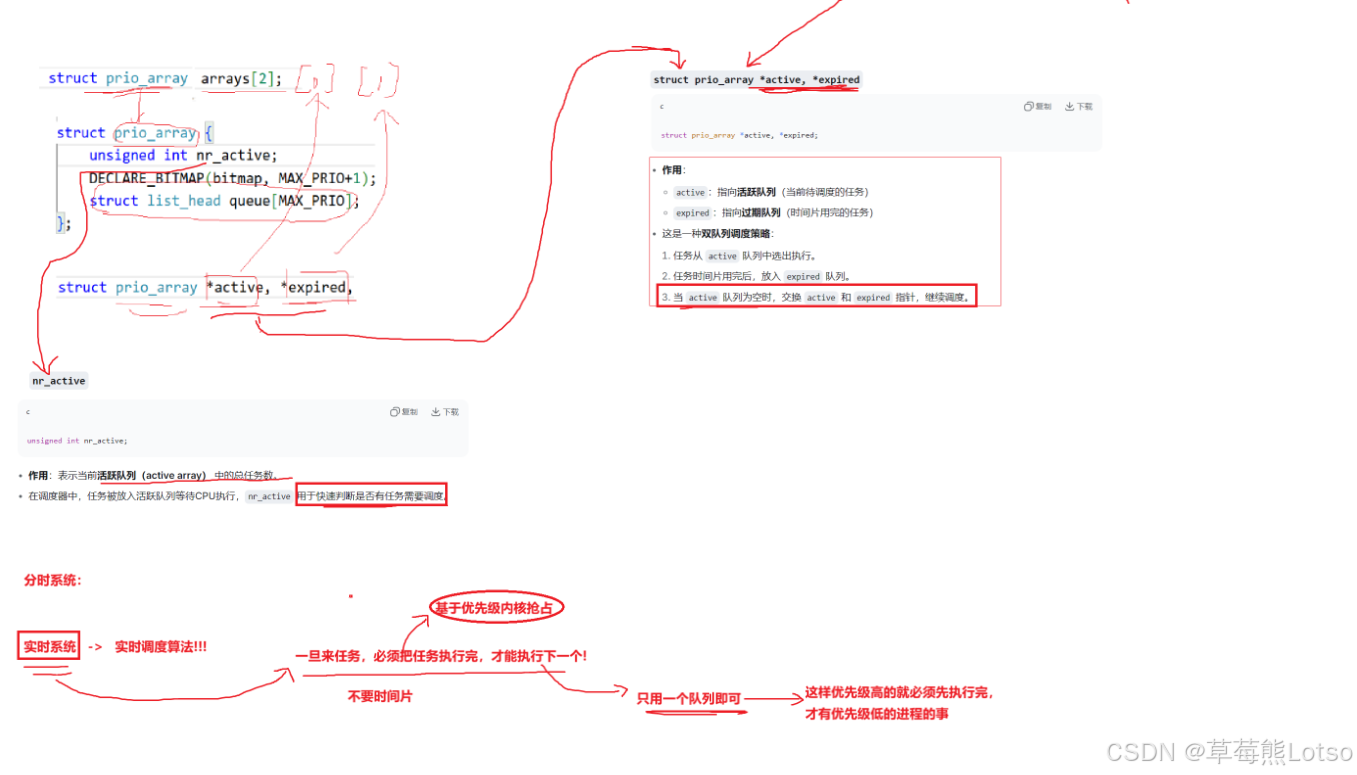
prio_array 是 O (1) 调度的核心,它将进程按优先级分组管理,结构如下:
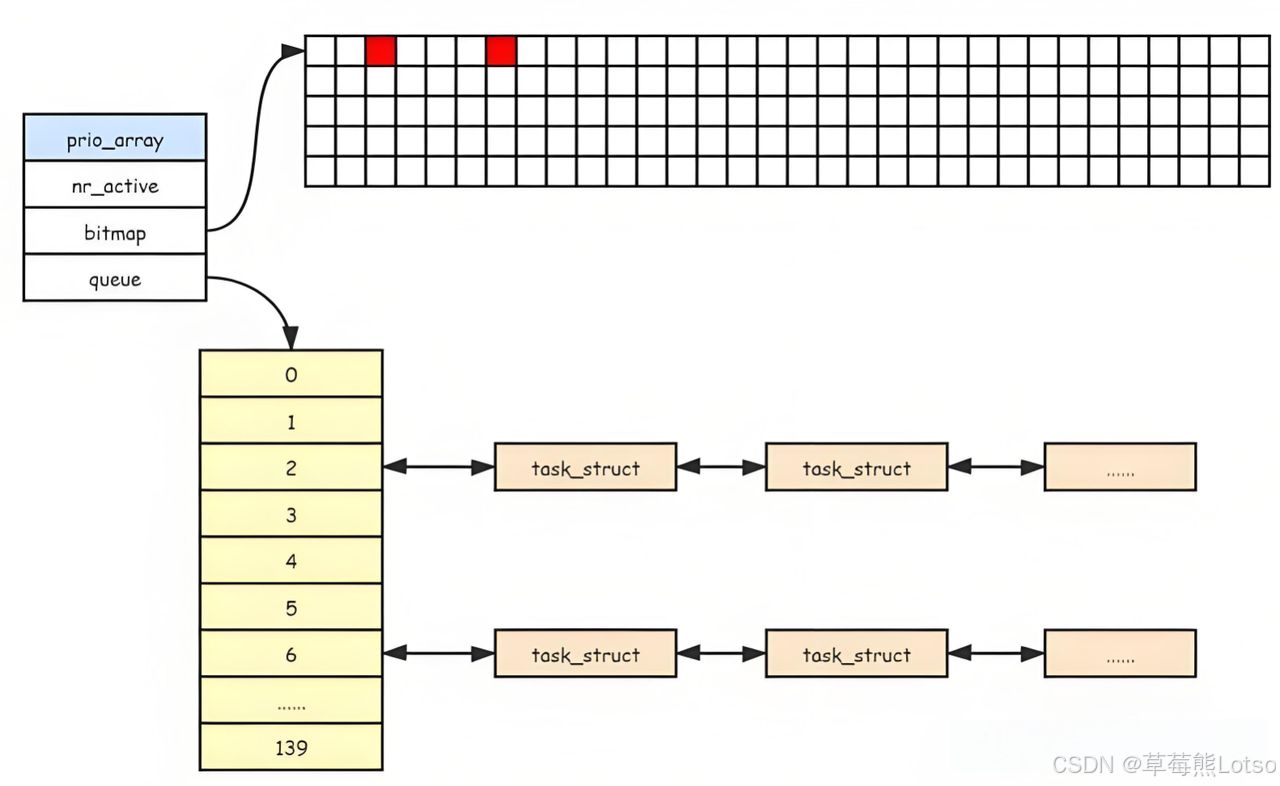
queue[140]:140 个进程链表,每个下标对应一个优先级(0~139);0~99:实时优先级(高优先级,现在先暂不关注);100~139:普通进程优先级(对应 nice 值 - 20~19,nice 值越小,优先级越高);nr_active:当前数组中总共有多少个运行状态的进程;bitmap[5]:5 个 32 位整数组成的位图(共 160 位),每一位对应一个优先级队列是否非空,这样还可以一口气检查 32 个;(例如:bitmap 的第 100 位为 1,表示优先级 100 的队列中有就绪进程)。
结构关系可视化(有些没讲到的可以先了解一下):
runqueue(每个CPU一个)
├─ lock:队列锁(保证线程安全)
├─ nr_running:就绪进程总数
├─ active:指向活跃队列的prio_array
├─ expired:指向过期队列的prio_array
└─ arrays[2]:包含两个prio_array
├─ prio_array[0](活跃队列)
│ ├─ queue[140]:140个优先级链表
│ ├─ nr_active:活跃进程数
│ └─ bitmap[5]:活跃队列优先级位图
└─ prio_array[1](过期队列)
├─ queue[140]:140个优先级链表
├─ nr_active:过期进程数
└─ bitmap[5]:过期队列优先级位图
二. O (1) 调度的核心流程:活跃队列与过期队列的切换
O (1) 调度的核心巧妙之处,在于通过 “活跃队列” 和 “过期队列” 的交替使用,实现时间片管理与优先级调度的解耦,流程分为三步:
2.1 步骤 1:进程入队 —— 按优先级插入对应链表
当进程变为就绪状态时(如从睡眠中唤醒):
- 调度器根据进程的优先级(PRI),找到对应的
queue[PRI]链表; - 将进程的
task_struct(PCB)插入该链表的尾部(FIFO 规则); - 置位
bitmap中对应优先级的比特位(标记该队列非空); - 若进程时间片未耗尽,插入
active队列;若已耗尽,插入expired队列。
2.2 步骤 2:调度决策 —— 位图快速查找最高优先级进程
调度器需要选择下一个执行进程时,核心操作仅需两步(O (1) 关键):
- 遍历
active队列的bitmap,找到第一个置位的比特位(对应最高优先级); - 从该比特位对应的
queue[PRI]链表中,取出头部进程(FIFO 规则);- - 将该进程设置为当前 CPU 的运行进程,分配 CPU 时间片。
✅️ 为什么是 O (1)?
- 位图遍历的时间不随进程数变化(最多遍历 140 位,实际通过硬件指令优化,仅需几个时钟周期),链表取头节点是 O (1) 操作,因此整体调度决策时间为常数。
2.3 步骤 3:队列切换 —— 当活跃队列为空时
当active队列中的所有进程都耗尽时间片后:
- 调度器无需重新计算所有进程的时间片,只需交换
active和expired指针; - 原
expired队列变为新的active队列,原active队列变为新的expired队列; - 调度器同时为新
expired队列中的进程重新计算时间片(这一步是后台操作,不影响调度决策时间); - 切换完成后,调度器继续从新的
active队列中选择进程,整个切换过程是 O (1)。
流程大致如下:
初始:
active → Prio_Array1(有5个任务)
expired → Prio_Array2(空)
调度过程:
任务逐个从active取出执行,时间片用完后放入expired
当 active.nr_active == 0 时:
交换指针:
temp = active
active = expired
expired = temp
结果:
active → Prio_Array2(现在有任务)
expired → Prio_Array1(现在为空,等待填充)
三. 优先级管理:如何保证高优先级的先执行?为什么不直接修改 PRI 值?
O(1) 调度队列通过 "优先级分组 + 位图标记" 的方式,完美支持优先级抢占。
- 优先级分组:高优先级的进程集中在
queue[140]的低下标位置,低优先级进程在高下标位置; - 位图快速定位:调度器始终从位图的第 0 位 开始遍历,确保最高优先级的非空队列被优先选中;
- 抢占机制:当高优先级进程被唤醒(插入
active队列)时,若当前 CPU 正在运行低优先级进程,调度器会立即触发进程切换,让高优先级进程抢占 CPU。
能不能直接修改 PRI 值?
不能直接改 pri 是因为:
任务已经在活跃队列的某个优先级链表中。直接改 pri 会导致:
- 位置错误:任务还在旧优先级的链表里,但
pri值已经变了 - 调度混乱:调度器按位图找任务时,可能找到空队列或错误任务
- 数据不一致:位图显示某优先级有任务,但链表中实际没有
正确做法:改 nice 值标记任务需要更新,等任务自然出队时(时间片用完),再按新优先级插入过期队列。这是 “延迟更新” 设计,保证数据结构一致性。
四. 本文全部知识点整体图解和部分源码(重要,仔细看)
- 下图涉及了本文中包含的大部分知识点,并补充了一点实时操作系统的理解(借用特斯拉的例子理解)

- 部分源码:
struct rq {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
unsigned long raw_weighted_load;
#ifdef CONFIG_SMP
unsigned long cpu_load[3];
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
struct task_struct *curr, *idle;
struct mm_struct* prev_mm;
struct prio_array *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain* sd;
/* For active balancing */
int active_balance;
int push_cpu;
struct task_struct* migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_local;
#endif
struct lock_class_key rq_lock_key;
};
/*
* These are the runqueue data structures:
*/
struct prio_array {
unsigned int nr_active;
DECLARE_BITMAP(bitmap, MAX_PRIO + 1); /* include 1 bit for delimiter */
struct list_head queue[MAX_PRIO];
};
结语:
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!
结语:Linux 2.6 内核的 O (1) 调度队列,是内核设计的经典案例 —— 通过巧妙的数据结构(位图 + 双队列),将复杂的调度问题转化为常数时间操作,完美解决了多进程场景的调度效率瓶颈。其核心思想 “按优先级分组 + 快速定位非空队列”,不仅适用于进程调度,还能迁移到线程池、任务调度等各类场景。理解 O (1) 调度队列的设计,能帮你更深刻地理解操作系统 “管理资源” 的核心逻辑 —— 好的设计往往不是复杂的算法,而是用最简洁的数据结构解决关键问题。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど