


面试官:RocketMQ 长轮询是怎么实现的?
大家好,我是君哥。
我们知道,消息队列消费端获取消息的方式包括推模式和拉模式,RocketMQ 并没有实现推模式,RocketMQ 的推模式本质上也是拉模式。他们在实现上有下面的不同:
- 拉模式需要开发在代码里调用拉取消息的方法,拉取到消息后直接进行消息处理;
- 推模式是消费者客户端初始化时利用重平衡线程去拉取消息,拉取消息的方法会注册回调函数,拉取到消息后,由回调函数触发监听器(定义处理逻辑)进行消息处理。
RocketMQ 为了提供拉取消息的效率,采用了长轮询机制,避免消费端无效的轮询请求。当消费者发送长轮询请求后,如果 Broker 上没有新消息,则不会立刻返回,而是挂起请求,等待新消息到来或者请求超时。
今天来聊一聊 RocketMQ 的长轮询是怎么实现的。
1 长轮询
长轮询的流程如下图:
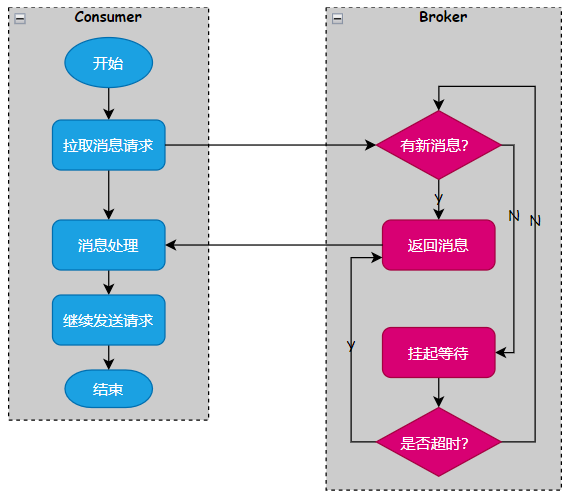 图片
图片
客户端建立连接后,发送消息拉取请求,如果服务端有新消息,则返回消息。如果服务端没有新消息,则挂起连接,等待新消息到来后给客户端返回。客户端如果连接超时,则断开连接。
2 RocketMQ 实现
2.1 消费端
RocketMQ 消费端长轮询有 2 个超时设置:
- brokerSuspendMaxTimeMillis:长轮询,Consumer 拉消息请求在 Broker 挂起超过这个时间,就会给消费端返回响应,无论有没有新消息,单位毫秒。这个参数消费端发送拉取请求时会发给 Broker,Broker 用来判断这个长连接是否超时。
- consumerTimeoutMillisWhenSuspend:消费端发送拉取请求的超时时间,这个时间要大于 brokerSuspendMaxTimeMillis,客户端初始化时会有校验。
注意,这 2 个超时时间官方都不推荐修改。
if (this.defaultLitePullConsumer.getConsumerTimeoutMillisWhenSuspend() < this.defaultLitePullConsumer.getBrokerSuspendMaxTimeMillis()) {
throw new MQClientException(
"Long polling mode, the consumer consumerTimeoutMillisWhenSuspend must greater than brokerSuspendMaxTimeMillis"
+ FAQUrl.suggestTodo(FAQUrl.CLIENT_PARAMETER_CHECK_URL),
null);
}2.2 Broker
RocketMQ 在 Broker 端通过设置 longPollingEnable 来开启长轮询,默认是开启。
Broker 长轮询挂起时间使用 suspendTimeoutMillis 来进行控制,前面提到过,这个时间由消费者发送的 brokerSuspendMaxTimeMillis 参数来赋值。
2.2.1 挂起消息
Broker 收到客户端拉取消息请求后,如果没有新消息,则将请求挂起,也就是将请求放到 pullRequestTable。
//PullMessageProcessor#processRequest
case ResponseCode.PULL_NOT_FOUND:
if (brokerAllowSuspend && hasSuspendFlag) {
//suspendTimeoutMillisLong 这个参数就是消费端发来的 consumerTimeoutMillisWhenSuspend
long pollingTimeMills = suspendTimeoutMillisLong;
if (!this.brokerController.getBrokerConfig().isLongPollingEnable()) {
pollingTimeMills = this.brokerController.getBrokerConfig().getShortPollingTimeMills();
}
String topic = requestHeader.getTopic();
long offset = requestHeader.getQueueOffset();
int queueId = requestHeader.getQueueId();
PullRequest pullRequest = new PullRequest(request, channel, pollingTimeMills,
this.brokerController.getMessageStore().now(), offset, subscriptionData, messageFilter);
//这里挂起消息
this.brokerController.getPullRequestHoldService().suspendPullRequest(topic, queueId, pullRequest);
response = null;
break;
}上面的 suspendPullRequest 调用了 PullRequestHoldService#suspendPullRequest,将请求保存在 pullRequestTable。
2.2.2 处理挂起
消息挂起后,后面怎么恢复呢?这里总需要一个线程去循环处理挂起的消息,这个处理逻辑也在 PullRequestHoldService,看下面代码:
public void run() {
log.info("{} service started", this.getServiceName());
while (!this.isStopped()) {
try {
//长轮询模式,等待 5s 后处理
if (this.brokerController.getBrokerConfig().isLongPollingEnable()) {
this.waitForRunning(5 * 1000);
} //...
//这里处理被挂起的请求
this.checkHoldRequest();
} catch (Throwable e) {
log.warn(this.getServiceName() + " service has exception. ", e);
}
}//...
}处理请求的逻辑参考下面代码:
protected void checkHoldRequest() {
for (String key : this.pullRequestTable.keySet()) {
String[] kArray = key.split(TOPIC_QUEUEID_SEPARATOR);
if (2 == kArray.length) {
String topic = kArray[0];
int queueId = Integer.parseInt(kArray[1]);
finallong offset = this.brokerController.getMessageStore().getMaxOffsetInQueue(topic, queueId);
try {
this.notifyMessageArriving(topic, queueId, offset);
} catch (Throwable e) {
log.error("check hold request failed. topic={}, queueId={}", topic, queueId, e);
}
}
}
}notifyMessageArriving 方法逻辑如下:
- 如果当前请求有新消息到来,则给消费者返回响应;
- 如果当前请求没有新消息,但是挂起请求已经超时,则给消费者返回响应;
- 否则, 继续挂起,等待 5s 后重复执行上面逻辑。
3 总结
长轮询可以降低无效的轮询请求,提升请求效率。RocketMQ 消费者长轮询支持配置,当消息量不太大,消费者没有必要频繁地请求,这时可以设置成长轮询机制。需要注意的是,消费端设置的请求超时时间必须大于 Broker 轮询时间。









