


Hydra Columnar:一个开源的PostgreSQL列式存储引擎

Hydra Columnar 是一个 PostgreSQL 列式存储插件,专为分析型(OLAP)工作负载设计,旨在提升大规模分析查询和批量更新的效率。
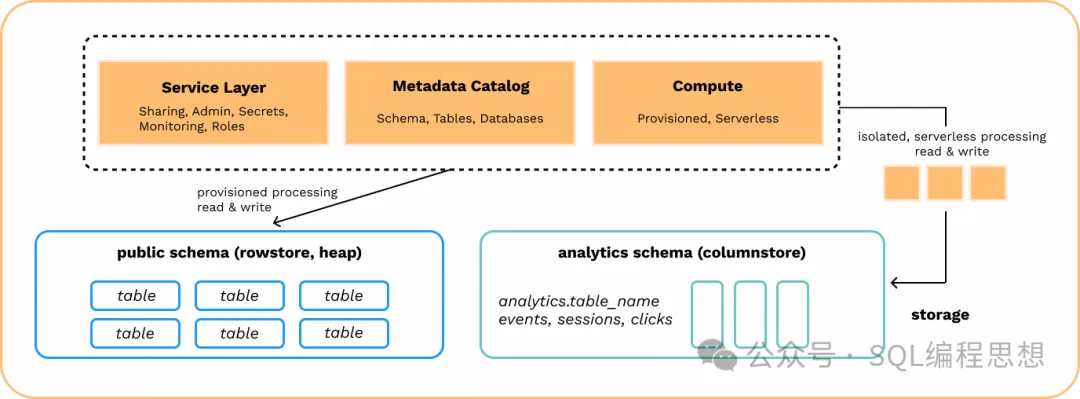
Hydra Columnar 以扩展插件的方式提供,主要特点包括:
- 采用列式存储,利用列内数据相似性,支持多种压缩算法,大幅降低存储成本。
- 并行查询优化,结合 PostgreSQL 的并行执行框架,充分利用多核资源处理复杂分析。
- 向量化执行,批量处理列数据,减少函数调用开销,提升 CPU 缓存利用率,加速查询。
- PostgreSQL 兼容性,同时支持 OLTP 以及 OLAP 负载场景。
目前,Hydra Columnar 还不支持 PostgreSQL 逻辑复制和外键,索引只支持 BTREE 或者 HASH。
以下是一个 Hydra Columnar 与 PostgreSQL、Citus 以及 TimescaleDB 使用 ClickBench 工具进行的分析性能测试比较: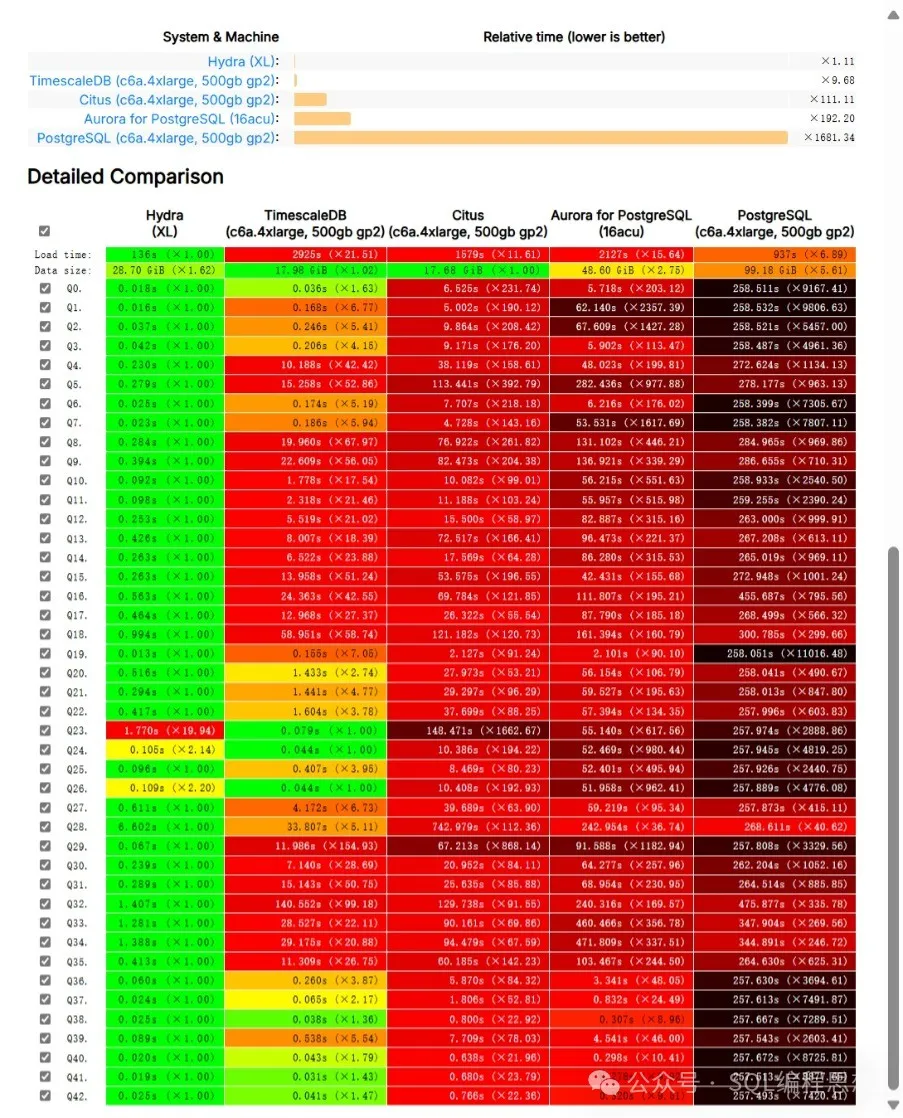
从可以看出,Hydra Columnar 在绝大多数查询中获得了极大的性能提升,具体数据可以参考下面的网站:
https://tinyurl.com/clickbench
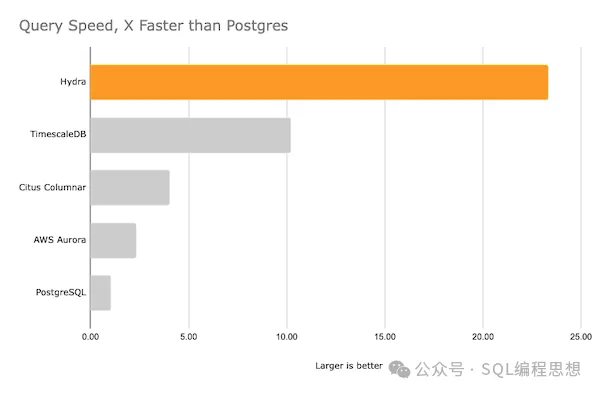
以下则是 TPC-H 数据仓库测试场景下的性能比较:
 Hydra Columnar 提供了多种安装方式,使用 Docker 安装运行的命令如下:
Hydra Columnar 提供了多种安装方式,使用 Docker 安装运行的命令如下:
git clone https://github.com/hydradatabase/hydra && cd hydra
cp .env.example .env
docker compose up
# 在另一个窗口中连接
psql postgres://postgres:hydra@127.0.0.1:5432连接数据库之后,启用插件并创建数据表:
CREATE EXTENSION IF NOT EXISTS columnar;
CREATE TABLE sensor_data (
timestamp TIMESTAMP,
device_id INT,
temperature FLOAT
);我们也可以明确指定存储引擎,默认使用 Hydra Columnar:
CREATE TABLE heap_table (...) USING heap;
CREATE TABLE columnar_table (...) USING columnar; -- 默认值然后可以正常导入数据并执行查询分析。
-- 批量插入数据(列式存储适合批量写入)
INSERT INTO sensor_data SELECT ...;
-- 分析查询(仅扫描 temperature 列)
SELECT AVG(temperature) FROM sensor_data WHERE timestamp > '2023-01-01';详细信息可以参考文档:
https://columnar.docs.hydra.so/









