


如何理解 Redis 是单线程的
一、在文章开头
你刚刚说redis是单线程的,那你能不能告诉我它是如何基于单个线程完成指令处理与客户端连接接?
基于这个问题,笔者会直接通过3.0.0源码分析的角度来剖析一下redis单线程的设计与实现。

二、详解redis的单线程模型
1. 单线程处理核心任务
当我们通过./redis-server启动redis时,如果我们配置了后台启动,那么shell进程线程就会调用系统函数即fork方法创建一个子进程,再通过execve方法将子进程主体替换成redis可执行文件也就是我们的redis-server,而子进程执行时会保持从父进程集成过来的标准输入和输出,最后redis就会调用main方法开始执行自己的启动逻辑了。

到这为止,我们不难看出,在启动阶段redis的启动并不是多线程的,它会根据我们的配置来决定启动逻辑,以我们上文所说的后台启动,它本质是通过父进程fork的方式完成创建与初始化的,这一点我们也可以直接从redis的main方法印证:
int main(int argc, char **argv) {
//命令参数解析与初始化
//......
//如果配置后台启动,则调用daemonize从父进程中fork出来执行
if (server.daemonize) daemonize();
//......
}我们步入daemonize方法,可以看到其内部如果子进程fork成功,后续的标准输入、输出、错误都会重定向到/dev/null,此后的各项工作也都是交由我们的redis server的主线程进行负责处理:
void daemonize(void) {
int fd;
//fork返回0说明fork成功,创建新会话,然后父进程exit(0)直接退出
if (fork() != 0) exit(0); /* parent exits */
setsid(); /* create a new session */
//将标准输入、输出、错误重定向写到/dev/null中,由此和终端分离
if ((fd = open("/dev/null", O_RDWR, 0)) != -1) {
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
if (fd > STDERR_FILENO) close(fd);
}
}此时,主线程的socket就会注册到epoll中,通过非阻塞调用epoll函数获取就绪的连接和指令完成与多个客户端的交互:
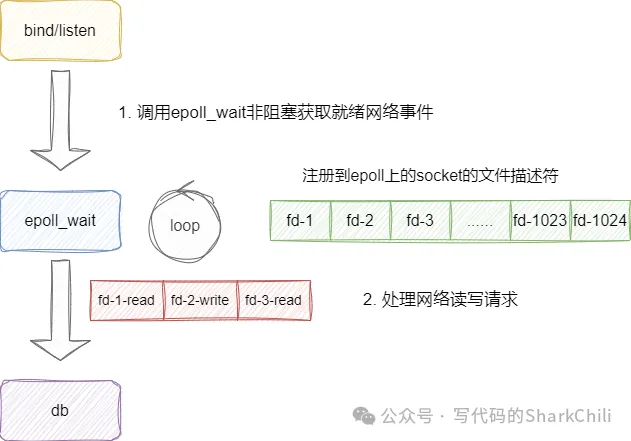
而上述所说这种工作模式,也就是我们的aeMain函数,这里笔者也给出的对应的的代码实现,如下所示,aeMain的本质逻辑就是调用无限循环,在循环中调用aeApiPoll即epoll非阻塞轮询获取就绪的事件并交给对应的读写事件处理器(rfileProc/wfileProc)进行处理:
//无限循环调用aeProcessEvents处理读写事件
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
//轮询标识没有停止则无限循环
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
//轮询并处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
//......
//通过epoll完成非阻塞调用
numevents = aeApiPoll(eventLoop, tvp);
//遍历拿到的事件将其交给读写处理器处理
for (j = 0; j < numevents; j++) {
//解析出该文件对应的类型
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
//如果事件fe是读事件则交给rfileProc
if (fe->mask & mask & AE_READABLE) {
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
//如果事件包含写标志,则交给wfileProc处理器处理
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
processed++;
}
}
//......
//返回处理事件数
return processed; /* return the number of processed file/time events */
}2. 多线程执行IO事件
截至到上述的片段,redis大体上我们可以认为是单线程执行,但是在3.0.0之后源码中,为了避免某些IO任务对主线程的执行效率的影响,redis还是创建了一些异步线程处理这些任务。
如下图所示,我们以aof为例,redis主线程会通过定时任务的方法serverCron会按照用户的配置检查当前是否需要进行aof写入,如果需要则通过bioCreateBackgroundJob提交一个任务到AOF异步刷盘的任务列表中,此时redis创建的io线程就会无限循环调用bioProcessBackgroundJobs从该列表中取出自己绑定的任务进行异步消费,通过这种简单的多线程模式,保证了耗时的IO操作不会阻塞主线程:
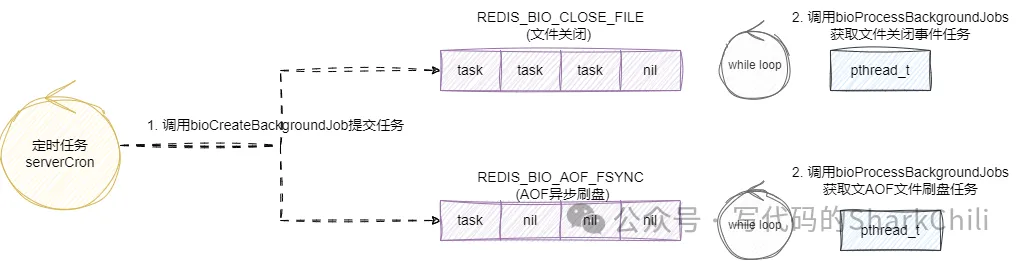
这里我们先给出对应的事件宏定义,可以看到事件总数为REDIS_BIO_NUM_OPS 即2,然后0是文件关闭事件,1的AOF异步刷盘事件,通过这样的顺序完成了事件的类型码和总量的定义:
/* Background job opcodes */
#define REDIS_BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */
#define REDIS_BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
#define REDIS_BIO_NUM_OPS 2对应的这些线程的初始化工作我们可以在main方法调用的initServer中可以看到这样一段调用,其内部的调用bioInit本质就是完成上述IO任务的线程的创建:
void initServer(void) {
int j;
//......
//创建bio任务线程
bioInit();
}bioInit它会初始化2个线程以及栈大小(最大不会超过4M),为每个线程各自分配一个队列,分配队列这一步就会按照循环遍历得到的值进行分配,遍历时用REDIS_BIO_NUM_OPS作为范围控制,遍历到0的处理文件关闭事件,1则是AOF刷盘事件。 完成事件类型队列分配之后,redis会为每个线程分配消费任务的方法指针bioProcessBackgroundJobs,后续的线程的任务消费和处理都是调用这个方法执行的:
void bioInit(void) {
pthread_attr_t attr;
pthread_t thread;
size_t stacksize;
int j;
//循环2次,刚刚好对应2个事件即0是文件关闭事件、1是aof刷盘事件
for (j = 0; j < REDIS_BIO_NUM_OPS; j++) {
//互斥数组初始化
pthread_mutex_init(&bio_mutex[j],NULL);
//条件数组初始化
pthread_cond_init(&bio_condvar[j],NULL);
//bio任务数组初始化,每个数组元素都是一个任务列表
bio_jobs[j] = listCreate();
//表示每种任务列表待处理的任务数为0
bio_pending[j] = 0;
}
//设置线程最大的栈属性大小,默认为1,若小于REDIS_THREAD_STACK_SIZE即4M则乘2
pthread_attr_init(&attr);
pthread_attr_getstacksize(&attr,&stacksize);
if (!stacksize) stacksize = 1;
while (stacksize < REDIS_THREAD_STACK_SIZE) stacksize *= 2;
pthread_attr_setstacksize(&attr, stacksize);
//创建线程并,为每一个线程分配一个任务列表
for (j = 0; j < REDIS_BIO_NUM_OPS; j++) {
//循环两次 j为0即代表文件关闭事件、1是aof刷盘事件,这个arg会作为事件类型绑定到线程pthread上
void *arg = (void*)(unsigned long) j;
//调用pthread_create完成线程属性初始化和事件类型的绑定
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
redisLog(REDIS_WARNING,"Fatal: Can't initialize Background Jobs.");
exit(1);
}
bio_threads[j] = thread;
}
}这里我们也给出bioProcessBackgroundJobs逻辑可以看到,每个线程调用该方法时,会在无限循环中根据任务的type按需消费处理:
void *bioProcessBackgroundJobs(void *arg) {
struct bio_job *job;
//每个线程都会根据自己传入的arg决定任务的type,0为文件关闭事件、1为aof刷盘事件
unsigned long type = (unsigned long) arg;
sigset_t sigset;
//......
//按照类型到bio_jobs取任务执行
while(1) {
listNode *ln;
//......
//取出自己需要处理的类型的队列任务
ln = listFirst(bio_jobs[type]);
job = ln->value;
//上互斥锁
pthread_mutex_unlock(&bio_mutex[type]);
//线程按照自己的类型进行消费
if (type == REDIS_BIO_CLOSE_FILE) {
close((long)job->arg1);
} else if (type == REDIS_BIO_AOF_FSYNC) {
aof_fsync((long)job->arg1);
} else {
redisPanic("Wrong job type in bioProcessBackgroundJobs().");
}
//完成后释放任务对象
zfree(job);
//线程解锁 任务移除
pthread_mutex_lock(&bio_mutex[type]);
//任务处理完成后的收尾工作
listDelNode(bio_jobs[type],ln);
bio_pending[type]--;
}
}了解的任务消费的源码之后,我们再来看看任务的投递的逻辑,我们以aof文件刷盘的任务为例,从定时任务函数serverCron,其内部会判断aof_child_pid的pid不为-1,若不为-1说明当前存在aof子进程,对此redis-server就会获取当前aof子进程的pid,调用backgroundRewriteDoneHandler提交一个aof重写完成的回调任务,等待aof重写完成后该任务就会被消费,从而完成aof缓冲区刷盘:
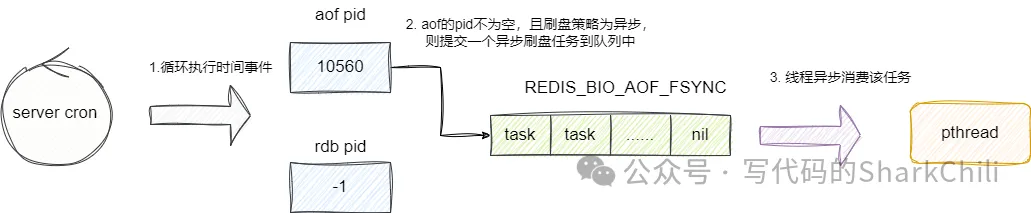
这里我们直接从serverCron为入口查看上述逻辑,可以看到其内部会查看rdb_child_pid 或者aof_child_pid 的值,这两个变量分别记录rdb或者aof异步持久化进程的id值,若达到以下两个条件则说明存在aof重写任务,需要提交一个aof重写后的刷盘任务:
- aof_child_pid 不是-1
- wait3获取到的pid也为aof重写的子进程id
符合上述条件则调用backgroundRewriteDoneHandler提交一个aof重写完成后的异步刷盘任务:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
int j;
REDIS_NOTUSED(eventLoop);
REDIS_NOTUSED(id);
REDIS_NOTUSED(clientData);
//......
//检查后台的aof重写进程是否结束,若结束的步入循环
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1) {
int statloc;
pid_t pid;
//获取当前子进程pid
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
//......
if (pid == server.rdb_child_pid) {
//......
} else if (pid == server.aof_child_pid) {//如果pid为aof的子进程值则调用backgroundRewriteDoneHandler
backgroundRewriteDoneHandler(exitcode,bysignal);
} else {
redisLog(REDIS_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
updateDictResizePolicy();
}
} else {
//......
}
//......
}步入backgroundRewriteDoneHandler可以看到,如果AOF刷盘策略是AOF_FSYNC_EVERYSEC即异步刷盘则会调用aof_background_fsync进行文件刷盘,而该方法内部的逻辑就是调用我们上文的所说的提交后台任务方法bioCreateBackgroundJob:
void backgroundRewriteDoneHandler(int exitcode, int bysignal) {
//......
if (server.aof_fd == -1) {
//......
} else {
/* AOF enabled, replace the old fd with the new one. */
oldfd = server.aof_fd;
server.aof_fd = newfd;
if (server.aof_fsync == AOF_FSYNC_ALWAYS)
aof_fsync(newfd);
else if (server.aof_fsync == AOF_FSYNC_EVERYSEC)//如果是异步刷盘则将任务提交到对应的队列中
//提交异步刷盘任务到REDIS_BIO_AOF_FSYNC队列中
aof_background_fsync(newfd);
//......
}
server.aof_lastbgrewrite_status = REDIS_OK;
//......
} else if (!bysignal && exitcode != 0) {
//......
} else {
//......
}
//......
}
//调用bioCreateBackgroundJob提交任务到AOF刷盘队列中
void aof_background_fsync(int fd) {
bioCreateBackgroundJob(REDIS_BIO_AOF_FSYNC,(void*)(long)fd,NULL,NULL);
}最终,我们就可以在bioCreateBackgroundJob看到aof异步刷盘的任务提交核心步骤:
- 获取任务参数,以我们aof异步刷盘的逻辑第一个参数就是aof子进程的文件句柄。
- 线程上锁。
- 任务入队。
- 唤醒相应线程。
- 释放互斥锁。
对应源码如下,读者可参考上述说明和注释了解逻辑:
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3) {
struct bio_job *job = zmalloc(sizeof(*job));
job->time = time(NULL);
//获取aof子进程的fd
job->arg1 = arg1;
//以本文为例都说null
job->arg2 = arg2;
job->arg3 = arg3;
//上锁
pthread_mutex_lock(&bio_mutex[type]);
//追加任务到对应job的数组中
listAddNodeTail(bio_jobs[type],job);
bio_pending[type]++;
//通知相关线程消费
pthread_cond_signal(&bio_condvar[type]);
//释放互斥锁
pthread_mutex_unlock(&bio_mutex[type]);
}三、小结
自此我们把redis中主线程和IO任务的线程都以图解和源码印证的方式分析完成了,以笔者的理解,设计者所说的redis是单线程的本质上的是强调对于核心的连接建立和指令处理是通过极致压榨单个线程高效完成,而其余的一些非核心的IO耗时逻辑还是需要多个线程进行异步处理。









