


当我们谈部署时,我们在谈什么?

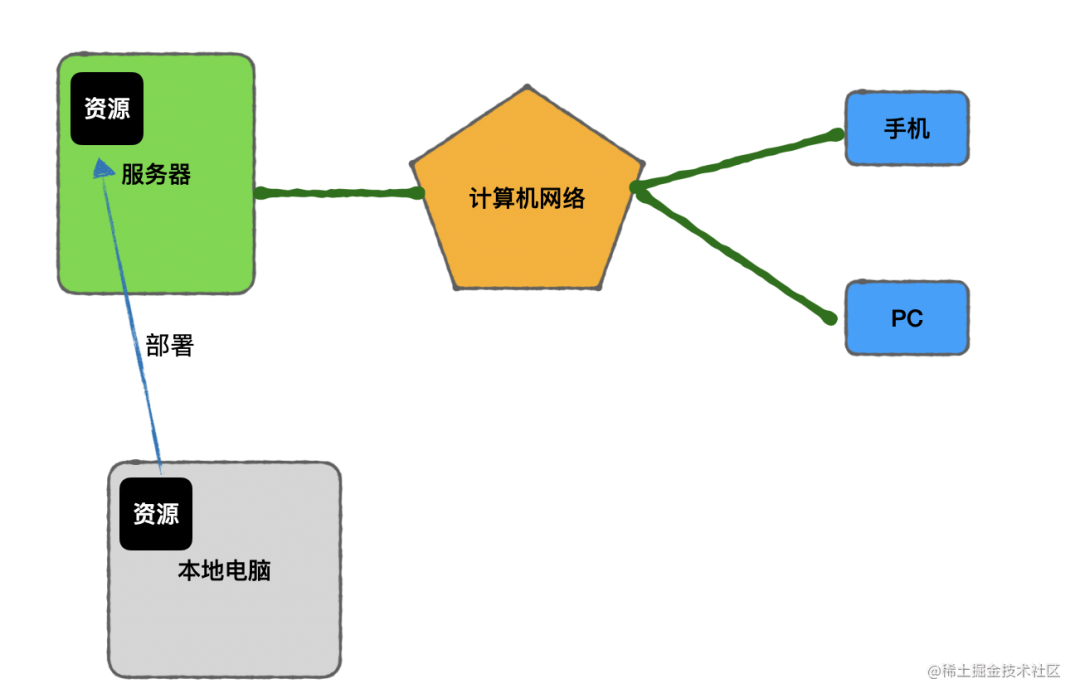
计算机网络把各地的计算机连接了起来,只要有一台可以上网的终端,比如手机、电脑,就可以访问互联网上任何一台服务器的资源(包括静态资源和动态的服务)。
作为开发者的我们,就是这些资源、服务的提供者,把资源上传到服务器,并把服务跑起来的过程就叫做部署。
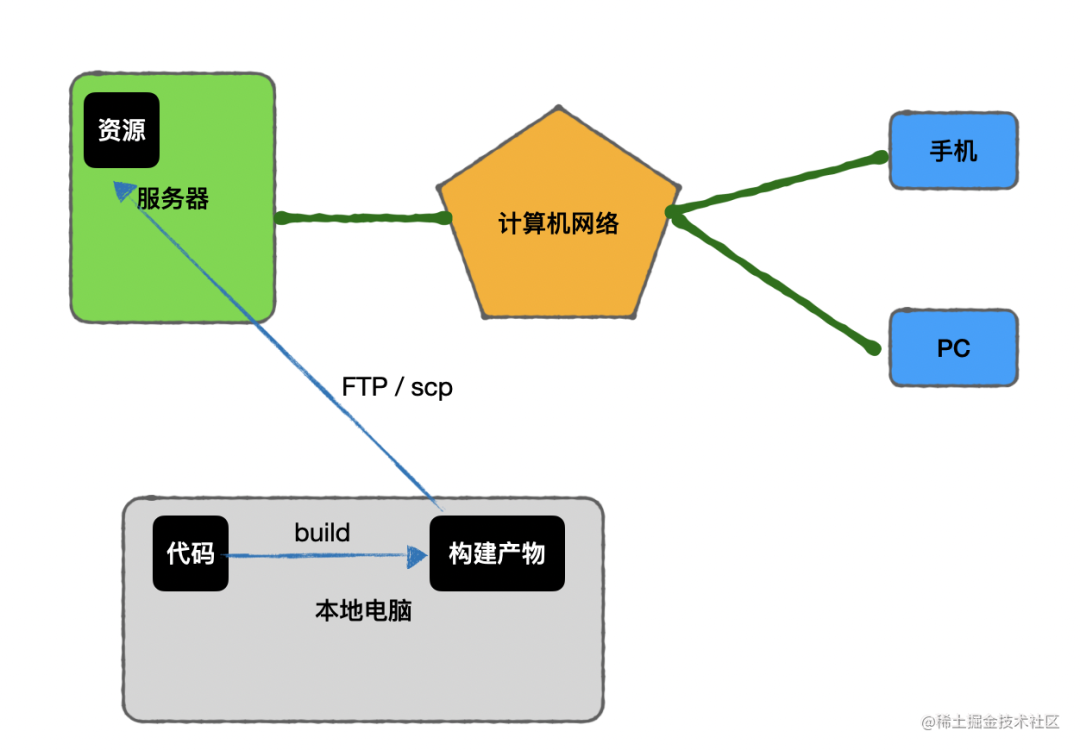
代码部分的部署,需要先经过构建,也就是编译打包的过程,把产物传到服务器。
最原始的部署方式就是在本地进行 build,然后把产物通过 FTP 或者 scp(基于 SSH 的远程拷贝文件拷贝) 传到服务器上,如果是后端代码还需要重启下服务。
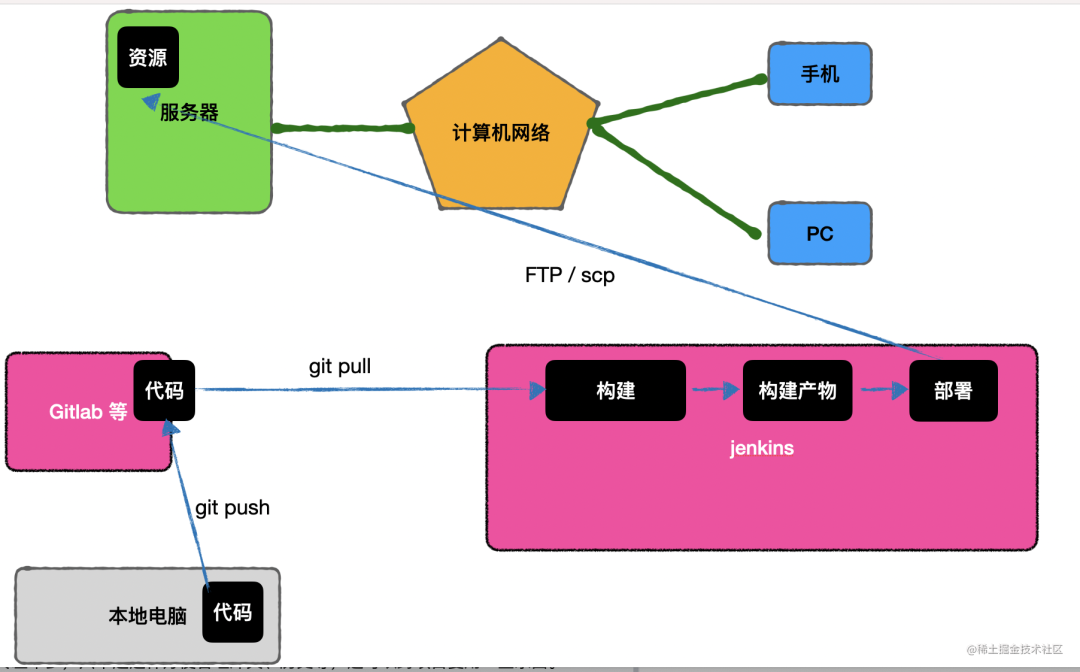
每个人单独构建上传,这样不好管理,也容易冲突,所以现在都会用专门的平台来做这件事构建和部署,比如 jenkins。
我们代码会提交到 gitlab 等代码库,然后 jenkins 从这些代码库里把代码下载下来进行 build,再把产物上传到服务器上。
流程和直接在本地构建上传差不多,只不过这样方便管理冲突、历史等,还可以跨项目复用一些东西。
构建、部署的过程最开始是通过 shell 来写,但写那个的要求还是很高的,很少人会写(我就不咋会)。后来就支持了可视化的编排,可以被编排的这个构建、部署的流程叫做流水线 pipeline。
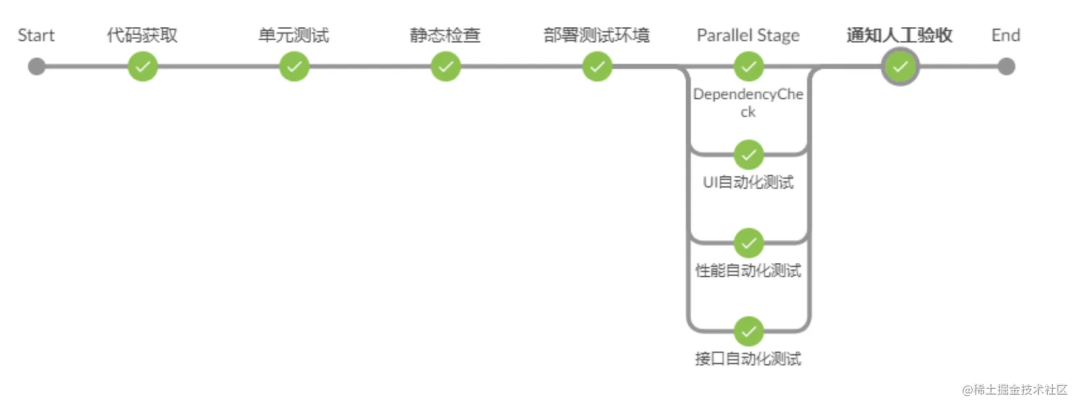
比如这是 jenkins 的 pipeline 的界面:
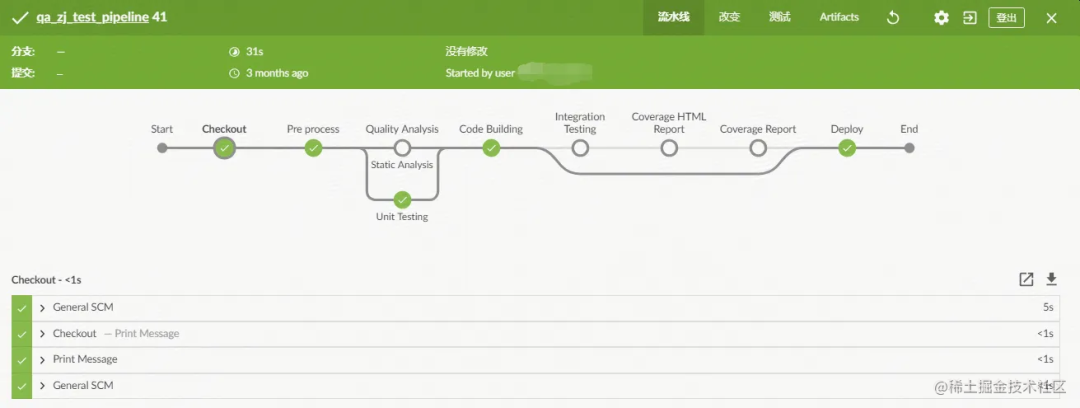
除了构建、部署外,也可以加入一些自动化测试、静态代码检查等任务。
这种自动化了的构建、部署流程就叫做 CI(持续集成)、CD(持续部署)。
我们现在还是通过 scp / FTP 来上传代码做的部署,但是不同代码的运行环境是不同的,比如 Node.js 服务需要安装 node,Java 服务需要安装 JRE 等,只把代码传上去并不一定能跑起来。
那怎么办呢?怎么保证部署的代码运行在正确的环境?
把环境也给管理起来,作为部署信息的一部分不就行了?
现在流行的容器技术就是做这个的,比如 docker,可以把环境信息和服务启动方式放到 dockerfile 里,build 产生一个镜像 image,之后直接部署这个 docker image 就行。
比如我们用 nginx 作为静态服务器的时候,dockerfile 可能是这样的:
FROM nginx:alpine
COPY /nginx/ /etc/nginx/
COPY /dist/ /usr/share/nginx/html/
EXPOSE 80
这样就把运行环境给管理了起来。
所以,现在的构建产物不再是直接上传服务器,而是生成一个 docker image,上传到 docker registry,然后把这个 docker image 部署到服务器。

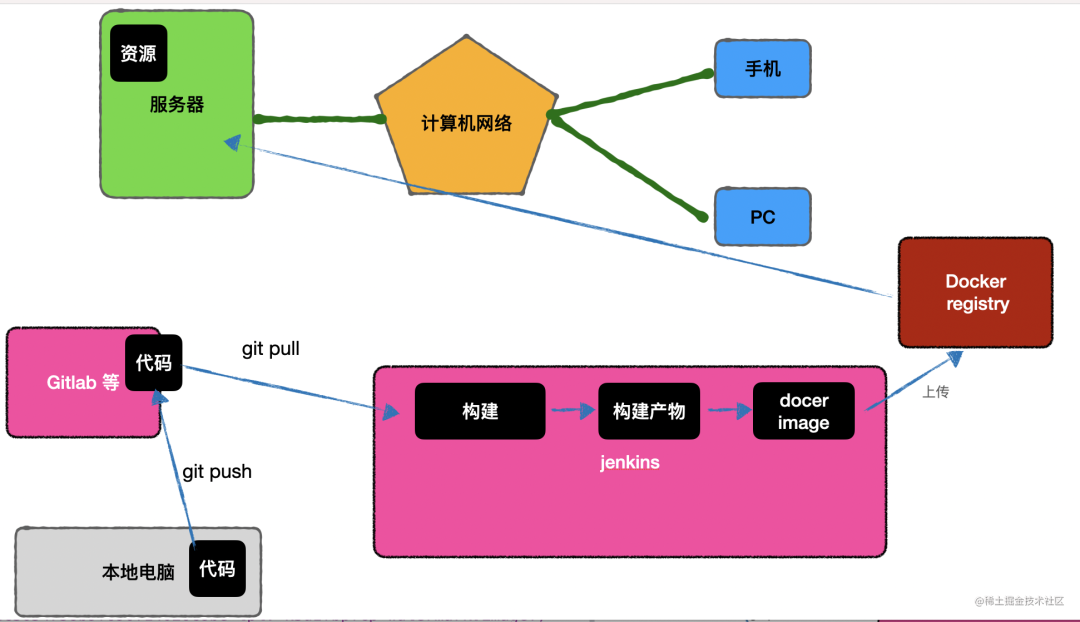
还有一个问题,现在前端代码、后端代码都部署在了我们的服务器上,共享服务器的网络带宽,其中前端代码是不会变动的、流量却很大,这样使得后端服务的可用带宽变小、支持的并发量下降。
能不能把这部分静态资源的请求分离出去呢?最好能部署到离用户近一点的服务器,这样访问更快。
确实可以,这就是 CDN 做的事情。
网上有专门的 CDN 服务提供商,它们有很多分散在各地的服务器,可以提供静态资源的托管。这些静态资源最终还是从我们的静态资源服务器来拿资源的,所以我们的静态资源服务器叫做源站。但是请求一次之后就会缓存下来,下次就不用再请求源站了,这样就减轻了我们服务器的压力,还能加速用户请求静态资源的速度。
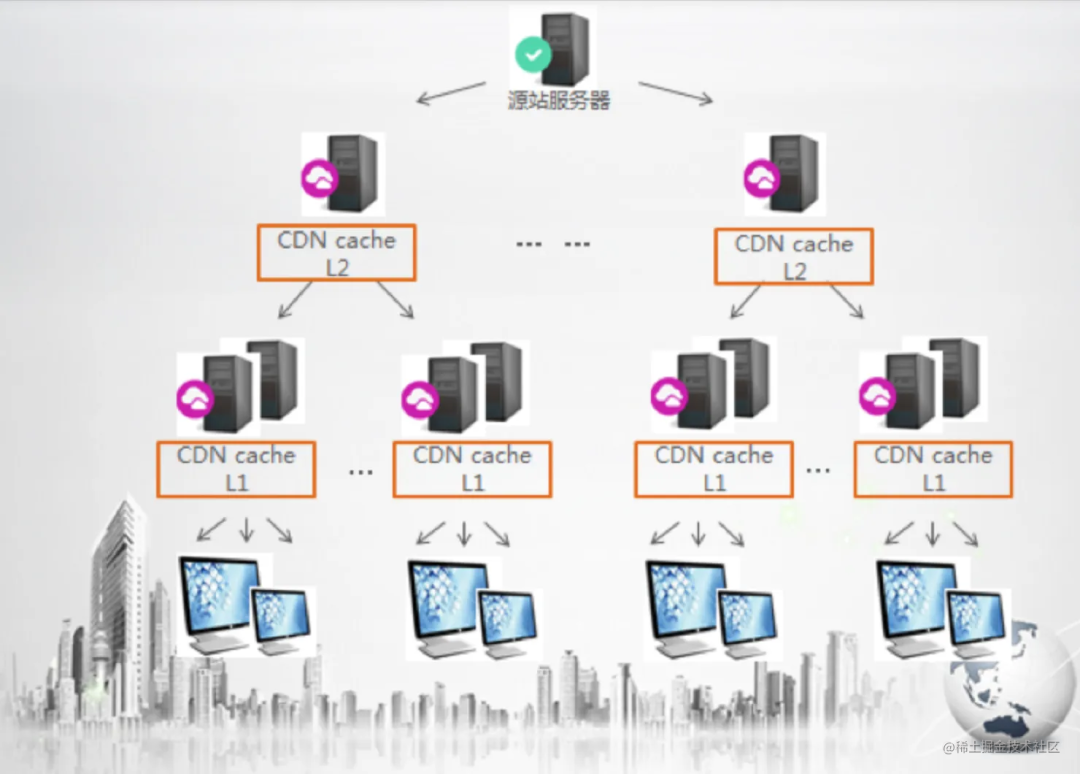
这样就解决了静态资源分去了太多网络带宽的问题,而且还加速了资源的访问速度。
此外,静态资源的部署还要考虑顺序问题,要先部署页面用到的资源,再部署页面,还有,需要在文件名加 hash 来触发缓存更新等,这些都是更细节的问题。
这里说的都是网页的部署方式,对于 APP/小程序它们是有自己的服务器和分发渠道的,我们构建完之后不是部署,而是在它们的平台提交审核,审核通过之后由它们负责部署和分发。
总结
互联网让我们能够用手机、PC 等终端访问任何一台服务器的资源、服务。而提供这些资源、服务就是我们开发者做的事情。把资源上传到服务器上,并把服务跑起来,就叫做部署。
对于代码,我们可以本地构建,然后把构建产物通过 FTP/scp 等方式上传到服务器。
但是这样的方式不好管理,所以我们会有专门的 CI/CD 平台来做这个,比如 jenkins。
jenkins 支持 pipeline 的可视化编排,比写 shell 脚本的方式易用很多,可以在构建过程中加入自动化测试、静态代码检查等步骤。
不同代码运行环境不同,为了把环境也管理起来,我们会使用容器技术,比如 docker。把环境信息写入 dockerfile,然后构建生成 docker image,上传到 registry,之后部署这个 docker image 就行。
静态资源和动态资源共享服务器的网络带宽,为了减轻服务器压力、也为了加速静态资源的访问,我们会使用 CDN 来对静态资源做加速,把我们的静态服务器作为源站。第一个静态资源的请求会请求源站并缓存下来,之后的请求就不再需要请求源站,这样就减轻了源站的压力。此外,静态资源的部署还要考虑顺序、缓存更新等问题。
对于网页来说是这样,APP/小程序等不需要我们负责部署,只要在它们的平台提交审核,然后由它们负责部署和分发。
当我们在谈部署的时候,主要就是在谈这些。









