


聚簇与非聚簇索引、回表及索引下推原理
引言
在数据库领域,聚簇索引和非聚簇索引是至关重要的概念,它们在数据组织与存储方式上截然不同,深刻影响着查询性能。
聚簇索引:数据与索引的紧密结合
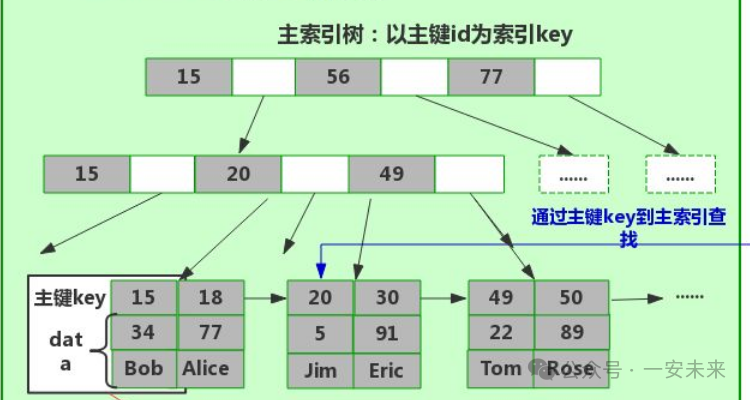
聚簇索引的核心特点是数据与索引存储在一处。其非叶子节点存放索引字段值,叶子节点则承载对应记录的整行数据。在InnoDB存储引擎里,聚簇索引依表的主键构建,表数据会依照主键顺序存储于磁盘,保证了行的物理存储顺序与主键逻辑顺序一致,这使得聚簇索引在查找时速度优势显著。
 图片
图片
例如,若有一张员工表,以员工ID为主键构建聚簇索引,那么在查询时,一旦定位到索引节点,即可直接获取该行员工的全部信息,无需额外操作。
非聚簇索引:索引与数据的分离存储
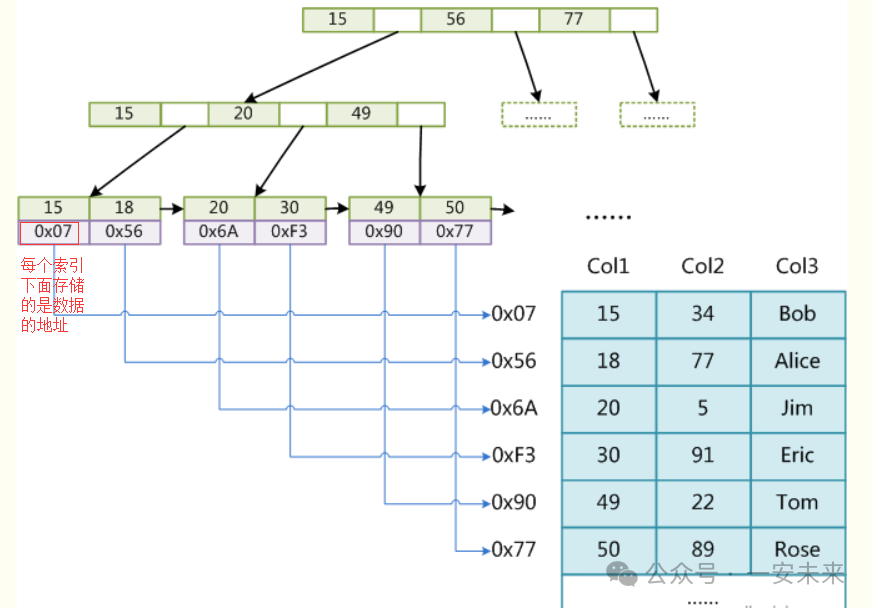
与聚簇索引相反,非聚簇索引将索引和数据分开存放。它的叶子节点包含索引字段值以及指向数据页数据行的逻辑指针。在InnoDB中,非聚簇索引通常基于非主键字段创建,也被称作二级索引。
 图片
图片
如在上述员工表中,若针对员工年龄创建非聚簇索引,其叶子节点会存储年龄值及对应的员工ID指针。这意味着通过非聚簇索引查询时,先找到索引值对应的主键ID,再凭借主键ID去查找所需数据,此过程即为回表操作。
回表操作:非聚簇索引查询的额外步骤
在InnoDB中,由于非聚簇索引叶子节点仅存储主键值,当执行查询时,如依据员工年龄查找员工其他信息,首先要通过非聚簇索引获取主键ID,接着利用该主键ID再次查询数据表以获取完整数据,这增加了查询的I/O开销。相比之下,使用聚簇索引(主键索引)查询则无需回表,效率更高。为减少回表次数,可借助覆盖索引和索引下推技术优化。
覆盖索引:减少数据读取的高效策略
覆盖索引是指查询语句所需数据能直接从索引获取,无需访问数据表。例如,表中有联合索引idx_key1_key2 (key1,key2),当执行SELECT key2 FROM covering_index_sample WHERE key1 = 'keytest';时,可直接利用索引返回结果,避免回表。
但需注意,若不符合最左前缀匹配原则,如SELECT key1 FROM covering_index_sample WHERE key2 = 'keytest';,虽看似覆盖索引,但会扫描索引树,无法有效利用索引。并且,若查询信息不在联合索引内,如SELECT key2, key3 FROM covering_index_sample WHERE key1 = 'keytest';也无法使用覆盖索引。
索引下推:优化查询性能的有力手段
索引下推是MySQL 5.6引入的默认开启优化技术(可关闭)。以people表的(zipcode,lastname,firstname)索引为例,对于查询SELECT * FROM people WHERE zipcode='123' AND lastname LIKE '%yian%' AND address LIKE '%Main Street%';,若未启用索引下推,MySQL先依zipcode='123' 从存储引擎获取数据返回服务端,再在服务端判断其他条件;启用后,会先筛选符合zipcode='123'且满足lastname LIKE '%yian%'的索引,符合条件才定位数据,有效减少回表次数。
不仅限于LIKE条件,联合索引中非前导列因类型不匹配等原因索引失效需扫表回表时,如select d from t2 where a = "ni" and b = 1; (b 字段索引失效),也可利用索引下推优化。
在执行计划中,使用索引下推时extra字段会显示"Using index condition" 。
本文地址:https://www.yitenyun.com/171.html









