


美团面试:向量库 Milvus的索引选择、优化策略?如何进行Milvus 集群部署?
常用的向量数据库
向量数据库, 是一种专门用于存储和查询向量数据的数据库。
向量数据, 也就是embedding向量。
向量数据, 典型结构是一个 一维教组 ,教组 中的元素是数值(通常是浮点数)。
这些数值, 表示对象或数据 在多维空间中的 位置、特征或属性。
向量数据库的主要功能
- 管理:向量数据库以原始数据形式处理数据,能够有效地组织和管理数据,便于AI模型应用。
- 存储:能够存储向量数据,包括各种AI模型需要使用到的高维数据。
- 检索:向量数据库特别擅长高效地检索数据,这一个特点能够确保AI模型在需要的时候快速获得所需的数据。这也是向量数据库能够在一些推荐系统或者检索系统中得到应用的重要原因。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速准确的相似性搜索和检索。
这意味着,可以使用向量数据库,根据其语义或上下文含义查找最相似或最相关的数据,而不是使用基于精确匹配或预定义标准 查询数据库 的传统方法。
向量数据库可以搜索非结构化数据,但也可以处理半结构化甚至结构化数据。例如,可以使用向量数据库执行以下操作,根据视觉内容和风格查找与给定图像相似的图像,根据主题和情感查找与给定文档相似的文档,以及根据功能和评级查找与给定产品相似的产品。
2023 向量数据排名
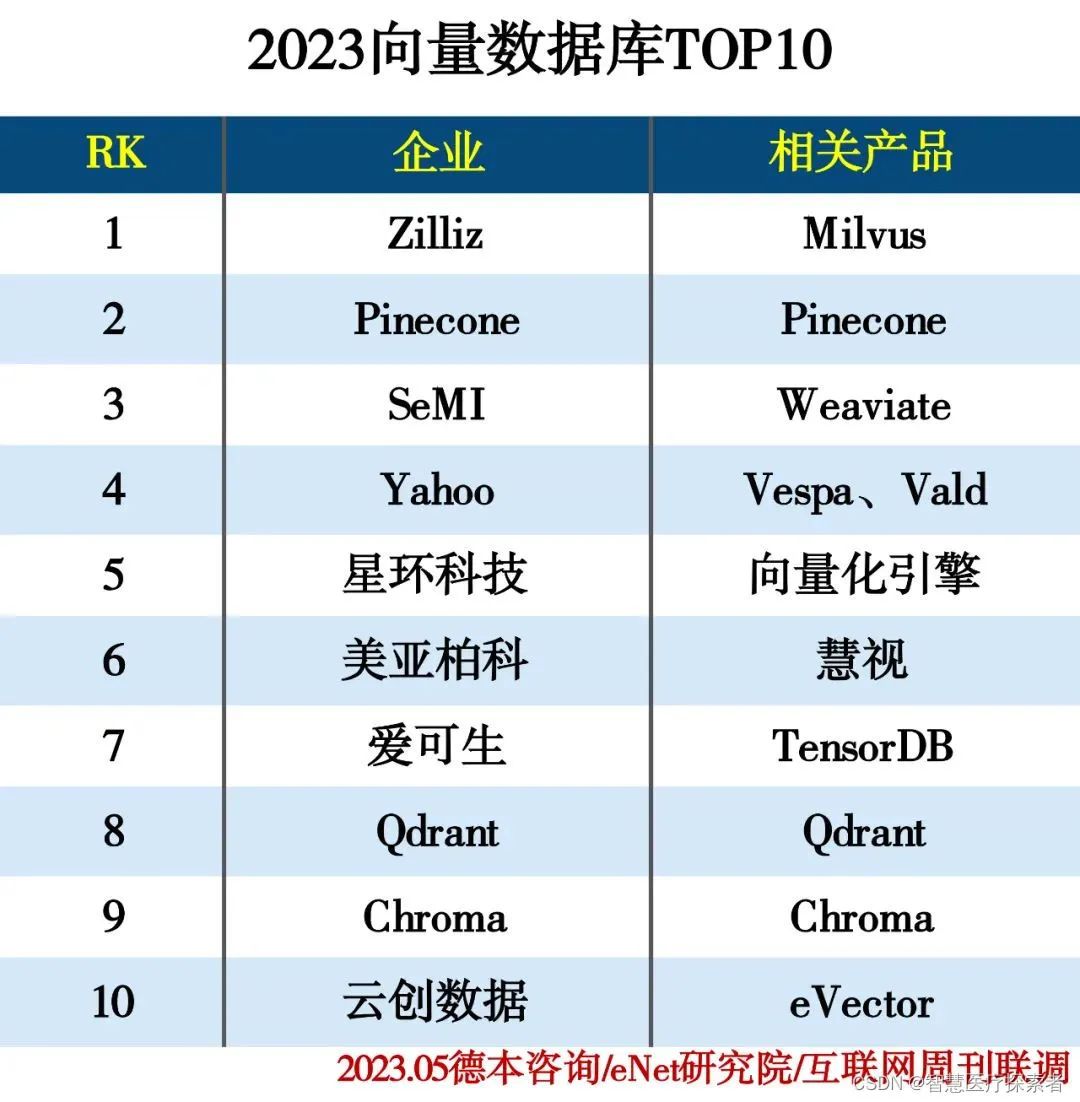 图片
图片
常用的向量数据库 对比
维度 | Elasticsearch | Milvus | Pinecone | FAISS | Chroma | PGVector | Weaviate | Qdrant |
架构 | 分布式,多节点 | 分布式,云原生 | 全托管 Serverless | 单机库 | 单机/轻量集群 | PostgreSQL 扩展 | 分布式(实验性) | 分布式,云原生 |
索引算法 | HNSW, IVF | IVF/HNSW/DiskANN | 自动优化 | IVF/PQ/HNSW | HNSW | IVFFlat, HNSW | HNSW, IVF | HNSW, DiskANN |
扩展性 | 高(分片与副本) | 极高(动态扩缩容) | 自动扩展 | 需手动分片 | 低 | 依赖 PostgreSQL | 中(分片支持) | 高(自动分片) |
部署复杂度 | 中等(需集群管理) | 高(需 K8s 运维) | 无需部署 | 低(仅库集成) | 极低 | 低(PG 扩展) | 中等(模块配置) | 中等(需 Rust 生态) |
查询性能 | 中等(百万级 ms 级) | 高(十亿级 <50ms) | 高(十亿级 <100ms) | 极高(无网络) | 低(百万级) | 中等(千万级) | 中高(多模态影响) | 极高(内存优化) |
多模态支持 | 强(文本+向量) | 中(需外部工具) | 中(稀疏+稠密向量) | 无 | 弱 | 中(SQL 扩展) | 强(内置模型) | 弱(需自定义) |
社区生态 | 极活跃(企业支持) | 活跃(开源+商业版) | 商业支持 | 活跃(Meta) | 小众(AI 社区) | PostgreSQL 生态 | 成长中(开发者驱动) | 新兴(Rust 社区) |
成本 | 中(自建集群) | 中(自建)或高(Zilliz) | 高(按需计费) | 低 | 极低 | 低(基于 PG) | 中(自建) | 低(开源) |
1 Elasticsearch
基于 Apache Lucene 的分布式搜索与分析引擎,支持 全文检索、结构化数据查询 和 实时分析。通过倒排索引、分片、副本机制实现高可用性和扩展性,广泛应用于日志分析、电商搜索、安全监控等领域。
基本功能:
- 全文检索:支持分词、模糊匹配、相关性评分(BM25)。
- 结构化查询:精确匹配、范围查询、布尔逻辑组合,基于 JSON 的复杂条件查询(如 age > 30 AND city = "Beijing")
- 聚合分析:统计、分组、嵌套聚合。
- 向量检索:通过 dense_vector 字段支持余弦/欧氏距离计算。
核心功能:
- 分布式架构:数据分片(Shard)与副本(Replica)实现水平扩展。
- 近实时搜索:数据写入后 1 秒内可检索。
- 混合查询:文本与向量联合检索(如电商商品搜索)。
技术特点:
- 底层引擎:基于 C++ 的高性能 Lucene 库,优化内存管理和查询速度。
- 倒排索引:快速定位关键词,支持动态更新,将文档内容拆分为词项(Term),反向映射到包含该词项的文档列表。
- 插件生态:支持中文 IK 分词器、英文语义分析(Word2Vec 等)、安全认证、机器学习扩展。
- RESTful API:通过 HTTP 接口与 Kibana 可视化集成。
- 跨平台支持:Docker/Kubernetes 部署,兼容 Windows/Linux/macOS。
性能分析:
- 写入吞吐:单节点 10k-50k docs/s(依赖文档大小)。
- 查询延迟:简单查询毫秒级,复杂聚合秒级。
- 向量检索:百万级向量延迟 10-50ms,性能弱于专用库。
应用场景:
- 电商搜索、日志管理(ELK 栈)、安全分析。
优缺点:
- 优点:生态完善、混合查询能力强、高可用。
- 缺点:资源消耗高、向量性能有限、运维复杂。
2 Milvus
开源分布式向量数据库,专为十亿级向量设计,高维向量相似度检索,支持多模态数据(图像、视频、文本),支持 GPU 加速,专注于适用于 AI 推荐系统、语义搜索、图像/视频检索等领域。
基本功能:
- 向量检索:支持欧氏距离、内积、余弦相似度。
- 标量过滤:结合数值/文本条件筛选结果。
核心功能:
- 多种索引:IVF_FLAT、HNSW、ANNOY、DiskANN(磁盘索引)。
- 分布式架构:支持水平扩展与动态扩缩容。
- 多模态扩展:需结合其他工具(如 Elasticsearch)实现文本检索。
技术特点:
- 计算分离:存储与计算节点分离,支持云原生部署。
- 数据版本化:支持时间旅行查询(Time Travel)。
- GPU 加速:基于 CUDA 的索引构建与查询优化。
性能分析:
- 十亿级向量:HNSW 索引下查询延迟 <50ms(SSD 环境)。
- 吞吐量:单节点支持 10k QPS(依赖索引类型)。
应用场景:
- 图像/视频检索、推荐系统、生物基因分析。
优缺点:
- 优点:高性能、扩展性强、开源社区活跃。
- 缺点:运维复杂、需额外处理元数据管理。
3 Pinecone
全托管云原生向量数据库,提供Serverless架构,支持实时向量相似性搜索和多模态数据处理,集成 OpenAI、Hugging Face 等工具链,无需管理基础设施,适合中小型企业快速部署。
基本功能:
- 向量检索:低延迟相似度搜索。
- 元数据过滤:结合键值对条件筛选结果。
核心功能:
- 自动索引优化:根据数据分布动态调整索引参数。
- Serverless 架构:按需扩展资源,无冷启动延迟。
技术特点:
- 混合向量:支持稀疏向量(如 BM25 编码)与稠密向量联合检索。
- 私有网络:数据加密与 VPC 隔离保障安全。
性能分析:
- 延迟:99% 查询 <100ms(十亿级数据)。
- 可用性:SLA 99.9%,自动容灾。
应用场景:
- 快速原型开发、中小规模推荐系统。
- 推荐系统:实时用户行为向量匹配(如短视频推荐)。
- RAG(检索增强生成):结合文档库和生成式模型提升问答质量。
- 多模态检索:图像+文本联合搜索(如电商商品图+描述)。
优缺点:
- 优点:免运维、低延迟、API 驱动。
- 缺点:闭源、成本高(0.1/GB/月+0.1/GB/月+0.01/次查询)。
4 FAISS
Facebook 开源的高效相似度搜索库,需自行处理持久化与分布式扩展。
基本功能:
- 近似最近邻搜索(ANN):支持多种距离度量(欧氏、余弦、内积)。
- 向量索引:提供倒排文件索引(IVF)、小世界网络构建多层次索引(HNSW)、LSH 等算法,适配稠密/稀疏向量。
- 聚类分析:通过 K-means、Faiss-CPU 实现向量分组。
- 量化压缩:减少内存占用(如 INT8 量化可将内存降低 4 倍)。
核心功能:
- GPU 加速:基于 CUDA 实现并行计算。
- 量化压缩:乘积量化(PQ)降低内存占用。
技术特点:
- 单机库:无分布式、事务、高可用等数据库功能。
- 轻量集成:可作为其他系统(如 Milvus)的底层引擎。
性能分析:
- 十亿级向量:GPU 加速下查询延迟 <10ms。
- 内存占用:PQ 压缩后内存减少 4-64 倍。
应用场景:
- 学术研究、小规模生产环境(需自建封装)。
优缺点:
- 优点:极致性能、轻量灵活。
- 缺点:无数据库功能、扩展性差。
5 Chroma
轻量级开源向量数据库,专注 AI 应用集成(如 LangChain、LlamaIndex)。
基本功能:
- 向量存储:支持本地或轻量云部署。
- 语义检索:与 NLP 模型集成(如 Sentence-BERT)。
- 混合查询:联合文本和向量条件检索(如 "apple" AND image_vector ≈ query_vector)。
核心功能:
- 简单 API:Python/JavaScript 客户端快速接入。
- AI 工具链集成:预置 LangChain 插件。
技术特点:
- 嵌入式模式:可内存运行,适合原型开发。
- 轻量持久化:基于 SQLite 或 ClickHouse 扩展。
性能分析:
- 规模限制:单机支持百万级向量,查询延迟 <100ms。
- 吞吐量:1k-5k QPS(依赖硬件)。
应用场景:
- 聊天机器人、小型知识库检索。
- 知识库问答:企业文档检索与智能问答。
- 语义搜索:新闻标题相似度匹配、学术论文查重。
优缺点:
- 优点:极简部署、AI 生态友好。
- 缺点:不支持分布式、功能单一。
6 PGVector
PostgreSQL 的向量检索扩展,支持 SQL 原生向量操作。
基本功能:
- 向量存储:将向量作为 PostgreSQL vector 类型存储,支持浮点数组。
- 相似度计算:支持点积、余弦相似度等计算(如 SELECT * FROM images WHERE dot_product(embedding, query_vector) > 0.5)。
- 混合查询:联合文本和向量条件(如 "cat" IN keywords AND embedding ∼ query_embedding)。
核心功能:
- SQL 集成:向量查询与关系型查询结合(如 JOIN 过滤)。
- 索引支持:IVFFlat、HNSW(PostgreSQL 16+)。
技术特点:
- 事务支持:ACID 兼容,适合复杂业务逻辑。
- 扩展性:依赖 PostgreSQL 集群(如 Citus 扩展)。
性能分析:
- 千万级向量:HNSW 索引下延迟 10-50ms。
- 十亿级挑战:需手动分库分表,性能下降显著。
应用场景:
- 已用 PostgreSQL 的企业扩展向量能力(如用户画像推荐)。
优缺点:
- 优点:SQL 生态无缝衔接、事务支持。
- 缺点:性能天花板低、调优复杂。
7 Weaviate
开源多模态向量数据库,内置 NLP/图像模型,支持语义检索与自动数据增强。
基本功能:
- 多模态检索:文本、图像、视频向量化与混合搜索。
- 语义理解:集成 BERT、CLIP 等模型生成向量。
核心功能:
- GraphQL API:灵活定义数据模式与查询逻辑。
- 自动分类:支持零样本分类(Zero-shot Learning)。
技术特点:
- 模块化设计:可插拔模型(如 OpenAI、HuggingFace)。
- 语义缓存:减少重复模型推理开销。
性能分析:
- 千万级向量:HNSW 索引延迟 20-100ms。
- 多模态扩展:图像+文本联合检索延迟增加 30-50%。
应用场景:
- 跨模态内容推荐、智能知识图谱。
优缺点:
- 优点:开箱即用多模态、模型集成灵活。
- 缺点:社区较小、分布式功能待完善。
8 Qdrant
开源高性能向量数据库,Rust 实现,专注低延迟与高吞吐。
基本功能:
- 向量检索:支持稀疏与稠密向量,基于 HNSW、IVF、Annoy 等算法实现毫秒级响应。。
- 条件过滤:结合 JSON 元数据筛选结果,通过标量条件缩小检索范围(如 price > 100 AND category = "electronics")。
核心功能:
- 分层存储:热数据内存缓存,冷数据磁盘存储。
- 动态负载均衡:自动分配分片与副本。
技术特点:
- Rust 高性能:无 GC 延迟,内存安全。
- 云原生设计:支持 Kubernetes 部署。
性能分析:
- 十亿级向量:磁盘索引(DiskANN)延迟 <100ms。
- 吞吐量:单节点 15k QPS(内存索引)。
应用场景:
- 广告推荐、实时反欺诈检测。
优缺点:
- 优点:极致性能、开源免费。
- 缺点:生态较新、多模态支持有限。
Milvus Docker compose安装部署
在安装Milvus之前,检查硬件和软件是否符合要求。
硬件要求
组件 | 要求 | 推荐配置 | 备注 |
CPU | - Intel第二代酷睿CPU或更高 - Apple Silicon | - 单机:4核或更多 - 集群:8核或更多 | |
CPU指令集 | - SSE4.2 - AVX - AVX2 - AVX-512 | - SSE4.2 - AVX - AVX2 - AVX-512 | Milvus内的向量相似度搜索和索引构建需要CPU支持的单指令多数据(SIMD)扩展集。确保CPU至少支持其中一种SIMD扩展。请参阅支持AVX的CPU了解更多信息。 |
RAM | 单机:8G - 集群:32G | 单机:16G - 集群:128G | RAM的大小取决于数据量。 |
硬盘 | SATA 3.0 SSD或更高 | NVMe SSD或更高 | 硬盘的大小取决于数据量。 |
软件要求
操作系统 | 软件 | 备注 |
macOS 10.14或更高 | Docker Desktop | 将Docker虚拟机(VM)设置为使用至少2个虚拟CPU(vCPU)和8GB的初始内存。否则,可能安装失败。有关更多信息,请参见在Mac上安装Docker Desktop。 |
Linux平台 | - Docker 19.03或更高 - Docker Compose 1.25.1或更高 | 有关更多信息,请参见安装Docker Engine和安装Docker Compose。 |
启用了WSL 2的Windows | Docker Desktop | 我们建议将源代码和其他数据绑定挂载到Linux容器中的Linux文件系统而不是Windows文件系统中。有关更多信息,请参见在启用了WSL 2的Windows上安装Docker Desktop。 |
软件 | 版本 | 备注 |
etcd | 3.5.0 | 查看附加磁盘要求。 |
MinIO | RELEASE.2023-03-20T20-16-18Z | |
Pulsar | 2.8.2 |
Milvus 作为分布式向量数据库,其核心功能(数据管理、向量搜索)依赖于 etcd 和 MinIO 等组件的协作。以下是它们的职责分工和协作流程:
组件 | 角色 | 核心功能 | 类比 |
Milvus | 向量数据库 | 向量数据存储、索引构建、相似性搜索 | 数据库引擎(如MySQL) |
etcd | 元数据存储 | 存储集合、分片、节点状态等元信息 | 数据库的“目录系统” |
MinIO | 对象存储 | 存储原始向量数据、索引文件等大文件 | 数据库的“硬盘” |
附加磁盘要求
磁盘性能对于etcd至关重要。强烈建议您使用本地NVMe SSD。
较慢的磁盘响应可能导致频繁的集群选举,最终会降低etcd服务的性能。
下载YAML文件
手动下载milvus-standalone-docker-compose.yml将其保存为docker-compose.yml,或使用以下命令进行下载。
wget https://github.com/milvus-io/milvus/releases/download/v2.3.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
如果GIThub地址无法下载,点击本站milvus-standalone-docker-compose.yml下载地址
### 启动Milvus
在与docker-compose.yml文件相同的目录下运行以下命令启动Milvus:
docker-compose.yml如果上述命令无法运行,请检查您的系统是否安装了Docker Compose V1。
如果是这种情况,建议迁移到Docker Compose V2。
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done现在检查容器是否正在运行。
sudo docker compose ps在Milvus独立模式启动后,将有三个Docker容器正在运行,包括Milvus独立模式服务及其两个依赖项。
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
milvus-etcd etcd -advertise-client-url ... Up 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Up 0.0.0.0:19530->19530/tcp, 0.0.0.0:9091->9091/tcp连接到Milvus
验证Milvus服务器监听的本地端口。将容器名称替换为你自己的名称。
docker port milvus-standalone 19530/tcp你可以使用此命令返回的本地IP地址和端口号连接到Milvus。
停止Milvus
要停止Milvus独立运行版,请运行:
sudo docker compose down要在停止Milvus后删除数据,请运行:
sudo rm -rf volumesMilvus + K8S 集群部署
Milvus是一个高效的向量数据库,适用于处理大规模、高维度向量数据。
确保所有节点安装了必要的软件和依赖,包括Docker和Kubernetes。
部署架构
Milvus 核心服务:
- Data Node:处理数据写入和持久化。
- Query Node:处理向量搜索请求。
- Index Node:构建向量索引。
- Root Coordinator:协调集群元数据。
- Proxy:对外暴露 API 的入口。
依赖组件:
- etcd:存储元数据(3 节点集群)。
- MinIO:对象存储(替代生产环境的 S3)。
- Pulsar:消息队列(日志流)。
详细部署 YAML 代码
1. 创建 Namespace
apiVersion: v1
kind: Namespace
metadata:
name: milvus2. 部署 etcd 集群(元数据存储)
// etcd StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: etcd
namespace: milvus
spec:
serviceName: etcd
replicas: 3
selector:
matchLabels:
app: etcd
template:
metadata:
labels:
app: etcd
spec:
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.5.7
env:
- name: ETCD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ETCD_DATA_DIR
value: /var/lib/etcd
- name: ETCD_INITIAL_CLUSTER
value: "etcd-0=http://etcd-0.etcd:2380,etcd-1=http://etcd-1.etcd:2380,etcd-2=http://etcd-2.etcd:2380"
- name: ETCD_INITIAL_ADVERTISE_PEER_URLS
value: "http://$(POD_NAME).etcd:2380"
- name: ETCD_LISTEN_PEER_URLS
value: "http://0.0.0.0:2380"
- name: ETCD_LISTEN_CLIENT_URLS
value: "http://0.0.0.0:2379"
- name: ETCD_ADVERTISE_CLIENT_URLS
value: "http://$(POD_NAME).etcd:2379"
ports:
- containerPort: 2379
name: client
- containerPort: 2380
name: peer
volumeMounts:
- name: etcd-data
mountPath: /var/lib/etcd
volumeClaimTemplates:
- metadata:
name: etcd-data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "standard"
resources:
requests:
storage: 10Gi
---
// etcd Service
apiVersion: v1
kind: Service
metadata:
name: etcd
namespace: milvus
spec:
clusterIP: None
ports:
- port: 2379
name: client
- port: 2380
name: peer
selector:
app: etcd3. 部署 MinIO(对象存储)
// MinIO Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: minio
namespace: milvus
spec:
replicas: 1 # 生产环境建议 4 节点分布式部署
selector:
matchLabels:
app: minio
template:
metadata:
labels:
app: minio
spec:
containers:
- name: minio
image: minio/minio:RELEASE.2023-09-04T19-57-37Z
args:
- server
- /data
env:
- name: MINIO_ROOT_USER
value: "minioadmin"
- name: MINIO_ROOT_PASSWORD
value: "minioadmin"
ports:
- containerPort: 9000
- containerPort: 9001
volumeMounts:
- name: minio-data
mountPath: /data
volumes:
- name: minio-data
persistentVolumeClaim:
claimName: minio-pvc
---
//MinIO PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: minio-pvc
namespace: milvus
spec:
accessModes:
- ReadWriteOnce
storageClassName: "standard"
resources:
requests:
storage: 50Gi
---
// MinIO Service
apiVersion: v1
kind: Service
metadata:
name: minio
namespace: milvus
spec:
ports:
- port: 9000
targetPort: 9000
- port: 9001
targetPort: 9001
selector:
app: minio4. 部署 Milvus 核心服务
// Milvus Proxy Service (API 入口)
apiVersion: v1
kind: Service
metadata:
name: milvus-proxy
namespace: milvus
spec:
type: NodePort # 生产环境建议 LoadBalancer 或 Ingress
ports:
- port: 19530
targetPort: 19530
nodePort: 30001
selector:
app: milvus-proxy
---
// Milvus 组件 Deployment(示例:Proxy、Data Node、Query Node)
apiVersion: apps/v1
kind: Deployment
metadata:
name: milvus-proxy
namespace: milvus
spec:
replicas: 2
selector:
matchLabels:
app: milvus-proxy
template:
metadata:
labels:
app: milvus-proxy
spec:
containers:
- name: proxy
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "proxy"]
env:
- name: ETCD_ENDPOINTS
value: "etcd-0.etcd:2379,etcd-1.etcd:2379,etcd-2.etcd:2379"
- name: MINIO_ADDRESS
value: "minio:9000"
- name: MINIO_ACCESS_KEY
value: "minioadmin"
- name: MINIO_SECRET_KEY
value: "minioadmin"
ports:
- containerPort: 19530
resources:
requests:
memory: "2Gi"
cpu: "1"
limits:
memory: "4Gi"
cpu: "2"
// Data Node、Query Node、Index Node 类似,需分别部署验证部署
1、 检查 Pod 状态:
kubectl get pods -n milvus -l app=milvus-proxy2、 测试 Milvus 连接:
```
from pymilvus import connections, Collection
connections.connect(host="", port=30001) # 使用 NodePort 地址
print(connections.list_collections()) # 应返回空列表(新集群) 关键配置说明
1)高可用性:
- etcd:3 节点集群,避免元数据单点故障。
- Milvus 组件:Proxy、Data Node 等多副本部署。
2) 持久化存储:
- etcd:通过 PVC 持久化元数据。
- MinIO:存储向量数据文件,生产环境建议使用分布式存储(如 Ceph 或 AWS S3)。
3) 资源分配:
- Proxy:至少 2 CPU 核心和 4GB 内存。
- Data Node:根据数据量增加内存和存储。
1、生产环境优化建议
1)分离组件角色:
专用 Root Coordinator、Data Coordinator 等组件。
示例:Root Coordinator
```yaml
- name: rootcoord
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "rootcoord"]2)监控与日志:
- 集成 Prometheus + Grafana 监控集群指标。
- 使用 EFK(Elasticsearch + Fluentd + Kibana)收集日志。
3) 安全加固:
- 启用 MinIO TLS 加密。
- 配置 Milvus 身份验证(需企业版支持)。
通过以上配置,您可以在 Kubernetes 上部署一个基础的 Milvus 向量数据库集群,适用于开发测试环境。生产部署需根据负载调整副本数、存储方案及网络策略。
2、 协作流程(以数据写入为例)
(1) 用户写入数据
- Proxy 接收客户端请求(如插入向量数据)。
- Proxy 将数据写入消息队列(如 Pulsar/Kafka,未在YAML中体现,但实际部署需包含)。
- Root Coordinator 通过 etcd 记录元数据(如数据对应的分片、版本信息)。
(2) Data Node 处理数据
Data Node 消费消息队列中的数据,进行以下操作:
- 序列化:将向量数据转换为文件格式(如 Parquet)。
- 上传至 MinIO:将文件存储到 MinIO 的指定 Bucket。
- 更新元数据:通过 etcd 记录文件路径、版本等元信息。
(3) Index Node 构建索引
- Index Node 根据配置的索引类型(如 HNSW、IVF),从 MinIO 拉取数据文件。
- 构建索引后,将索引文件上传回 MinIO,并通过 etcd 记录索引元数据。
(4) Query Node 处理搜索请求
Query Node收到搜索请求后:
- 从 etcd 获取目标集合的元数据(如分片分布、索引类型)。
- 根据元数据定位 MinIO 中的索引文件和数据文件。
- 加载索引和数据,执行相似性搜索并返回结果。
3. 关键协作场景
(1) 元数据一致性
- etcd 作为分布式键值存储,确保所有 Milvus 节点访问的元数据一致。
- 例如:当创建新集合时,Root Coordinator 将集合的 Schema 和分片信息写入 etcd,所有节点通过监听 etcd 获知变更。
(2) 数据持久化与高可用
- MinIO 存储实际数据文件,确保即使 Milvus 节点宕机,数据仍可从对象存储恢复。
- 生产环境中,MinIO 需配置为分布式模式(多节点 + 纠删码),避免数据丢失。
(3) 故障恢复
- Data Node 宕机: Milvus 通过 etcd 检测节点状态,自动将宕机节点的分片迁移到其他健康节点,新节点从 MinIO 拉取数据重建服务。
- etcd 集群故障: etcd 基于 Raft 协议实现高可用,半数以上节点存活即可正常服务。若全部节点宕机,Milvus 将不可用,需优先恢复 etcd。
4. 生产环境优化建议
(1) etcd 高可用
- 部署 3/5 节点的 etcd 集群,跨可用区分布。
- 监控 etcd 性能(如写入延迟、存储空间)。
(2) MinIO 分布式部署
- 至少 4 节点 MinIO,启用纠删码(Erasure Coding)提高数据可靠性。
- 示例配置:
```
// MinIO 分布式部署(4节点)
apiVersion: apps/v1/v1
kind: StatefulSet
spec:
replicas: 4
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ReadWriteOnce]
storageClassName: "standard"
resources:
requests:
storage: 100Gi(3) 分离 Milvus 组件角色
- 专用 Root Coordinator、Data Node、Query Node,避免资源竞争。
- 示例配置(YAML 片段):
```
// 专用 Root Coordinator
- name: rootcoord
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "rootcoord"]
env:
- name: ETCD_ENDPOINTS
value: "etcd-0.etcd:2379,etcd-1.etcd:2379,etcd-2.etcd:2379"5. 总结
- etcd:Milvus 的“大脑”,管理元数据和集群状态。
- MinIO:Milvus 的“硬盘”,持久化存储向量和索引文件。
- 协作逻辑: 通过 etcd 维护一致性,通过 MinIO 实现数据持久化,Milvus 各组件基于两者协作完成向量数据的存储、索引和查询。 三者缺一不可,共同保障系统的可靠性、扩展性和高性能。
Python Milvus连接管理
管理Milvus连接
本主题介绍了如何连接和断开Milvus服务器。
在进行任何操作之前,请确保连接到了Milvus服务器。
Milvus支持两个端口,端口19530和端口9091:
- 端口19530用于gRPC。当使用不同的Milvus SDK连接到Milvus服务器时,它是默认端口。
- 端口9091用于RESTful API。当使用HTTP客户端连接到Milvus服务器时,使用该端口。
下面的示例连接到主机为localhost,端口为19530或9091的Milvus服务器,并断开连接。如果连接被拒绝,请尝试解除相应端口的阻止。
连接到Milvus服务器
构建一个Milvus连接。在进行任何操作之前,请确保连接到Milvus服务器。
```
from pymilvus import connections
connections.connect(
alias="default",
user='用户名',
password='密码',
host='localhost',
port='19530'
)参数 | 描述 |
| 要构建的Milvus连接的别名。 |
| Milvus服务器的用户名。 |
| Milvus服务器用户名的密码。 |
| Milvus服务器的IP地址。 |
| Milvus服务器的端口。 |
默认安装Milvus没有设置密码
返回值
通过传递的参数创建的Milvus连接。
异常
- NotImplementedError:如果连接参数中的处理程序不是GRPC。
- ParamError:如果连接参数中的池不受支持。
- 异常:如果参数中指定的服务器没有准备好,我们无法连接到服务器。
Python Milvus数据库管理
管理数据库
与传统的数据库引擎类似,您也可以在Milvus中创建数据库,并为特定用户分配权限来管理它们。然后这些用户有权管理数据库中的集合。Milvus集群支持最多64个数据库。
创建数据库
要创建数据库,您需要首先连接到Milvus集群,并准备一个名称:
from pymilvus import connections, db
conn = connections.connect(host="127.0.0.1", port=19530)
database = db.create_database("book")使用数据库
Milvus集群附带了一个默认数据库,名为”default”。除非另有指定,否则集合将在默认数据库中创建。
要更改默认数据库,请按照以下步骤操作:
db.using_database("book")您还可以在连接到Milvus集群时设置要使用的数据库,示例如下:
conn = connections.connect(
host="127.0.0.1",
port="19530",
db_name="default"
)列出数据库
要查找Milvus集群中所有现有的数据库,请按照以下步骤操作:
db.list_database()
['default', 'book']删除数据库
要删除数据库,您必须先删除其所有集合。否则,删除将失败。
db.drop_database("book")
db.list_database()
['default']Python Milvus集合管理
Milvus的集合(Collection)类似MYSQL的表,用于组织数据,由一个或多个分区组成。
创建集合
一个集合由一个或多个分区组成。
在创建新集合时,Milvus会创建一个名为_default的默认分区。
下面的示例将创建一个名为book的两个分区的集合,其中包括一个名为book_id的主键字段,一个名为word_count的INT64标量字段和一个名为book_intro的二维浮点向量字段。
实际应用程序往往会使用比示例更高维度的向量。
准备模式
模式类似MYSQL表结构定义。
要创建的集合必须包含一个主键字段和一个向量字段。主键字段支持INT64和VarChar数据类型。
首先,准备必要的参数,包括字段模式、集合模式和集合名称。
在定义集合模式之前,为集合中的每个字段创建一个模式。
为了减少数据插入中的复杂性,Milvus允许您为每个标量字段指定一个默认值(除主键字段外)。
这意味着,如果您在插入数据时将某个字段留空,将使用在字段模式创建期间配置的默认值。
from pymilvus import CollectionSchema, FieldSchema, DataType
book_id = FieldSchema(
name="book_id",
dtype=DataType.INT64,
is_primary=True,
)
book_name = FieldSchema(
name="book_name",
dtype=DataType.VARCHAR,
max_length=200,
default_value="Unknown" # 默认值为"Unknown"
)
word_count = FieldSchema(
name="word_count",
dtype=DataType.INT64,
default_value=9999 # 默认值为9999
)
book_intro = FieldSchema(
name="book_intro",
dtype=DataType.FLOAT_VECTOR,
dim=2
)
schema = CollectionSchema(
fields=[book_id, book_name, word_count, book_intro],
descriptinotallow="Test book search", # 描述为"测试图书搜索"
enable_dynamic_field=True # 启用动态模式
)
collection_name = "book"
from pymilvus import Collection
collection = Collection(
name=collection_name,
schema=schema,
using='default',
shards_num=2
)模式类型 | 参数 | 描述 | 选项 |
|
| 要创建的字段的名称。 | N/A |
| 要创建的字段的数据类型。 | 主键字段: - | |
| 控制字段是否为主键字段的开关。主键字段需要指定此参数。 |
| |
| 开启或关闭自动ID(主键)分配的开关。主键字段需要指定此参数,默认为 |
| |
| 允许插入的字符串的最大长度。 | [1, 65,535] | |
| 字段的默认值。此参数仅适用于非数组和非JSON标量字段。无法为主键字段指定默认值。有关更多信息,请参阅参数default_value。 | N/A | |
| 向量的维度。 | [1, 32,768] | |
| 字段的描述。 | N/A | |
|
| 要创建的集合的字段。 | N/A |
| 要创建的集合的描述。 | N/A | |
| 是否启用动态模式。数据类型: Boolean ( | ||
| 要创建的集合的名称。 | N/A |
创建带有模式的集合
然后,使用上面指定的模式创建一个集合。
from pymilvus import Collection
collection = Collection(
name=collection_name,
schema=schema,
using='default',
shards_num=2
)参数 | 描述 | 选项 |
| 在这里指定服务器的别名,可以选择在哪个Milvus服务器上创建集合。 | N/A |
| 要创建的集合的分片数。 | [1,16] |
| 要创建的集合的逻辑分区数。 | [1,4096] |
| 集合的存活时间为集合的过期时间。过期的集合中的数据将被清理,并且将不参与搜索或查询。以秒为单位指定TTL。 | 值应为0或更大。0表示禁用TTL。 |
限制
资源配置
功能 | 最大限制 |
集合名称长度 | 255个字符 |
集合中的分区数 | 4,096 |
集合中的字段数 | 64 |
集合中的分片数 | 16 |
default_value参数
- default_value仅适用于非数组和非JSON标量字段。
- default_value不适用于主键。
- default_value的数据类型必须与dtype中指定的数据类型相同。否则,可能会发生错误。
- 在使用auto_id的情况下,不允许将所有剩余字段都设置为使用默认值。也就是说,在执行插入或更新操作时,您至少需要指定一个字段的值。否则,可能会发生错误。
重命名集合
如果您想要重命名一个集合,您可以使用集合重命名API与Milvus进行交互。本指南将帮助您了解如何使用您选择的SDK来重命名现有集合。
在以下代码片段中,我们创建一个集合并将其命名为old_collection,然后用rename_collection 方法,将其重命名为new_collection。
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType, connections, utility
connections.connect(alias="default")
schema = CollectionSchema(fields=[
... FieldSchema("int64", DataType.INT64, descriptinotallow="int64", is_primary=True),
... FieldSchema("float_vector", DataType.FLOAT_VECTOR, is_primary=False, dim=128),
... ])
collection = Collection(name="old_collection", schema=schema)
utility.rename_collection("old_collection", "new_collection") # 输出: True
utility.drop_collection("new_collection")
utility.has_collection("new_collection") # 输出: False修改集合
目前,TTL功能仅在Python中可用。
collection.set_properties(properties={"collection.ttl.seconds": 1800})上面的示例将集合的TTL更改为1800秒。
检查集合是否存在
验证集合是否存在于Milvus中。
from pymilvus import utility
utility.has_collection("book")检查集合详情
from pymilvus import Collection
collection = Collection("book") # 获取现有集合。
collection.schema # 返回集合的模式CollectionSchema。
collection.description # 返回集合的描述。
collection.name # 返回集合的名称。
collection.is_empty # 返回一个布尔值,指示集合是否为空。
collection.num_entities # 返回集合中的实体数。
collection.primary_field # 返回主键字段的schema.FieldSchema。
collection.partitions # 返回list [Partition]对象。
collection.indexes # 返回list [Index]对象。
collection.properties # 返回集合中数据的过期时间。列出所有集合
from pymilvus import utility
utility.list_collections()删除集合
from pymilvus import utility
utility.drop_collection("book")创建集合别名
from pymilvus import utility
utility.create_alias(
collection_name = "book",
alias = "publication"
)删除集合别名
from pymilvus import utility
utility.drop_alias(alias = "publication")修改集合别名
将现有的别名更改为另一个集合。
以下示例基于别名 publication 最初是为另一个集合创建的情况。
from pymilvus import utility
utility.alter_alias(
collection_name = "book",
alias = "publication"
)加载集合
在进行搜索或查询之前如何将集合加载到内存中。在Milvus中,所有搜索和查询操作都在内存中执行。
Milvus允许用户将集合加载为多个副本,以利用额外的查询节点的CPU和内存资源。这个功能提高了整体的QPS和吞吐量,而无需额外的硬件。在加载集合之前,请确保您已经为其创建了索引。
from pymilvus import Collection, utility
collection = Collection("book")
collection.load(replica_number=2)
utility.load_state("book")
utility.loading_progress("book")释放集合
如何在搜索或查询后释放集合以减少内存使用。
from pymilvus import Collection
collection = Collection("book") # 获取现有的集合。
collection.release()向量索引和搜索的基本原理
对于传统数据库,搜索功能都是基于不同的索引方式(B+Tree、倒排索引等)加上精确匹配和排序算法(BM25、TF-IDF)等实现的。
BM25、TF-IDF 本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
对于向量搜索,通过比较向量之间的距离来判断它们的相似度。
1、相似性测量(Similarity Measurement)
在相似性搜索中,需要计算两个向量之间的距离,然后根据距离来判断它们的相似度。
而如何计算向量在高维空间的距离呢?
有三种常见的向量相似度算法:欧几里德距离、余弦相似度和点积相似度。
(1)欧几里得距离(Euclidean Distance)
欧几里得距离(Eucidean Distance),也称为欧氏距离,是数学中最常见的距离度量方式之一,用于计算两个点在欧几里得空间中的直线距离。
在二维空间中,如果有两个点 P1(x1,y1)和 P2(x2,y2)那么它们之间的欧几里得距离 d 可以通过下面的公式计算:
在三维空间中,如果有两个点 P1(x1,y1,z1)和 P2(x2,y2,z2),那么它们之间的欧几里得距离 d 可以通过下面的公式计算:
对于更高维度的空间,欧几里得距离的计算公式可以推广为:
其中,x1i 和 x2i 分别是点 P1 和 P2在第 i 个维度上的坐标值。
欧几里得距离算法的优点是可以反映向量的绝对距离,适用于需要考虑向量长度的相似性计算。
例如推荐系统中,需要根据用户的历史行为来推荐相似的商品,要考虑用户历史行为的数值,不只是用户历史行为。
(2)余弦相似度(Cosine Similarity)
余弦相似度(Cosine Similarity)是一种常用于度量两个向量在空间中的相似度的方法。
它通过计算两个向量的点积和它们各自的模长来确定这两个向量之间的余弦角,从而反映它们之间的相似程度。
定义对于两个向量A和B,余弦相似度 cos(0)定义为:
其中:
 图片
图片
计算公式:
如果向量A和B分别表示为:
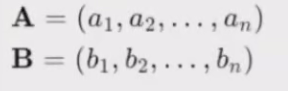 图片
图片
那么:
 图片
图片
余弦相似度对向量的长度不敏感,只关注向量的方向,因此适用于高维向量的相似性计算。例如语义搜索和文档分类。
余弦相似度的范围从-1到1,其中1表示完全相同的方向(完全相似),0表示正交(完全不相似),-1表示完全相反的方向(完全不相似)。
(3)点积相似度(Dot product similarity)
点积相似度(Dot Product Similarity),也称为向量内积相似度,是一种衡量两个向量之间相似度的方法。
它通过计算两个向量的点积来评估它们之间的相似性。
定义
对于两个向量 A 和 B,点积相似度定义为:
Dot Product Similarity =A · B
其中,点积 A · B 计算为:
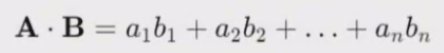 图片
图片
计算公式
如果点积结果为正数,表示两个向量之间存在正相关性,即它们在某种程度上是相似的。如果点积结果为负数,表示两个向量之间存在负相关性,即它们在某种程度上是相反的。如果点积结果为零,表示两个向量之间没有线性相关性。
特点
- 无归一化:点积相似度没有进行归一化处理,因此它对向量的长度敏感,这意味着如果两个向量的长度不同,即使它们的方向相同,它们的点积也可能不同。
- 范围:点积的值可以是正的、负的或零,取决于向量之间的相对方向,正点积表示向量之间的角度接近0度,负点积表示向量之间的角度接近180度,而零点积表示向量正交。
与余弦相似度比较
点积相似度与余弦相似度的主要区别在于:
- 点积相似度:对向量的长度敏感,没有归一化。
- 余弦相似度:对向量的长度不敏感,因为已经通过模长进行了归一化。
2、相似性搜索(Similarity Search)
对于向量搜索,通过比较向量之间的距离来判断它们的相似度。
想要在一个海量的数据中找到和某个向量最相似的向量,需要对数据库中的每个向量进行一次比较计算,计算量非常巨大。
高效的搜索算法有很多,其主要思想是通过两种方式提高搜索效率:减少向量大小——通过降维或减少表示向量值的长度。缩小搜索范围——可以通过聚类或将向量组织成基于树形、图形结构来实现,并限制搜索范围仅在最接近的族中进行,或者通过最相似的分支进行过滤。
大部分算法共有的核心概念,也就是聚类。
(1)K-Means
K-means算法的核心思想是将数据划分为K个独立的簇(cluster)。
- 使得每个簇内的数据点距离尽可能小。
- 而簇与旗之间的距离尽可能大。
下面是K-means算法的具体步骤:
1.初始化:选择K个数据点作为初始质心(centroid),这些质心可以是随机选择的,也可以是通过其他方法选定的。2.分配:将每个数据点分配到离它最近的质心所代表的簇中。3.更新:重新计算每个族的质心,方法是将簇内所有数据点的均值作为新的质心。4.重复步骤2和3,直到质心不再发生显著变化或达到迭代次数上限。
选择了三个初始质点:
 图片
图片
更新完成质点后:
 图片
图片
聚类数目(K)的选择
K-Means算法的第一步是确定要将数据划分成多少个簇。
这个选择通常基于领域知识或使用Elbow方法等统计技巧来确定。
K的选择对于聚类结果有着重要的影响。
- 如果K选择过小,可能会导致簇的划分不够细致,无法准确地反映数据的结构;
- 如果K选择过大,可能会导致簇的划分过于细致,会被数据的声影响,导致分类不准确。
距离的度量K-Means使用欧式距离(Euclidean distance)来度量数据点之间的相似性,但也可以根据具体问题选择其他距离度量方法。
质心
每个簇都有一个质心,它是该簇内所有数据点的均值。质心代表了簇的中心位置。
优化目标
K-Means的优化目标是最小化每个数据点到其所属簇质心的距离之和。
优点K-means算法具有以下优点:
1)简单易懂:K-means算法的步骡简单,容易理解和实现。
2)计算效率高:K-means算法的时间复杂度相对较低,适用于大规模数据集。
3)可扩展性强:K-means算法可以通过各种改进和优化应用于不同类型的教据和问题。
缺点K-means算法也存在一些局限性:
1)需要预先指定K值:在实际应用中,选定合适的K值可能需要尝试多种方法。
2)对初始质心敏感:算法的结果可能受到初始质心选择的影响,导致局部最优解。
3)对噪声和离群点敏感:K-means算法容易受到噪声和离群点的影响,可能导致簇划分不准确。
4)对簇形状和大小敏感:K-means算法假设簇是凸的和大小相似的,对于其他形状和大小的簇可能效果不佳。
(2)改进方法
针对K-means算法的局限性,有以下改进方法:
1)选择合适的K值:可以尝试不同的K值,通过轮廓系数(Silhouette Coefficient)、肘部法则(Elbow Method)等方法评估聚类效果,选择最佳的K值。
2)优化初始质心选择:使用K-means++算法改进初始质心选择,降低算法收敛到局部最优解的风险。
3)增量式K-means:对于大规模数据集,可以采用增量式K-means算法进行分布式计算,提高计算效率。
4)引入核函数:将K·means算法扩展为Kernel K-means算法,使用核函数将数据映射到高维空间,处理非线性可分的数据。
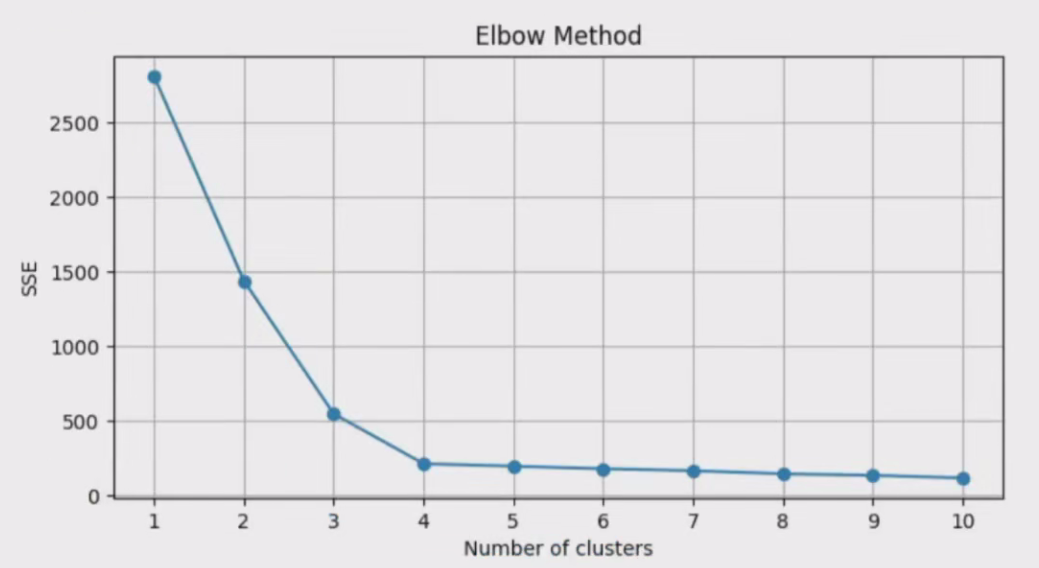
肘部法则(Elbow Method)
基本原理是,随着簇数量K的增加,每个簇内的样本数会减少,因此簇内样本与簇中心的平均距离(即簇内误差平方和SSE)会逐渐减小。当K增加到一定程度后,每增加一个簇,SSE的下降幅度会逐渐减小,形成一个“肘部”拐点。
这个拐点就是最佳的簇数量,因为在此之后增加簇数所带来的分类精度提升将不再显著。
在实际操作中,我们通常会绘制一个曲线图,横轴表示簇的数量K,纵轴表示SSE。
然后,观察曲线的变化趋势,寻找“肘部”位置。
在Python中,可以使用matplotlib库来绘制这个曲线图,并通过观察图形来确定最佳的K值。
 图片
图片
K-means++K-means++ 是一种改进的 K-means 算法,主要针对初始质心选择的问题。
K-means++的优势在于能够选择更好的初始质心,从而提高算法的收敛速度,降低陷入局部最优解的风险。
初始质心选取的基本思路就是,初始的聚类中心之间的相互距离要尽可能的远。
算法描述如下:1、随机选取一个样本作为第一个聚类中心c1;2、计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用 D(x)表示;这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法选出下一个聚类中心;3、重复2,直到选出k个聚类中心。4、使用选定的初始质心运行K-means 算法。
Kernel K-meansKernel K-means 是一种基于核方法的K-means 算法,可以处理非线性可分的数据。核方法通过将数据映射到高维特征空间,使得原本在低维空间中不可分的教据在高维空间中变得线性可分,
Kernel K-means 的主要步骤如下:1.选择合适的核函数(如 RBF 核、多项式核等)和参数。2.将数据集映射到高维特征空间。3.在高维特征空间中执行 K-means 算法。4.将聚类结果投影回原始数据空间。
Kernel K-means 可以处理复杂的数据结构,但计算复杂度相对较高,可能不适合大规模数据集。在实际应用中,可以根据问题的特点选择合适的K-means 算法变体。
应用场景K-means算法广泛应用于各个领域,如:1.图像分割:将图像中的像素聚类为K个簇,可以实现图像分割和简化。2.文档聚类:将文档按照内容相似度进行聚类,有助于文档分类、信息检索和推荐系统。3.客户细分:将客户按照购买行为、兴趣爱好等特征进行聚类,有助于企业针对不同群体制定个性化的营销策略。4.异常检测:通过聚类,可以发现数据中的离群点或异常点,进而进行异常检测或数据清洗。5.降维:K-means算法可以与主成分分析(PCA)等降维技术结合,实现数据降维和可视化。
3、近似邻近(ANN)
除了暴力搜索能完美的搜索出最相邻,所有的搜索算法只能在速度和质量还有内存上做一个权衡,这些算法也被称为近似最相邻(Approximate Nearest Neighbor)。
(1)Product Quantization(PQ)乘积量化
在大规模数据集中,聚类算法最大的问题在于内存占用太大。
这主要体现在两个方面,
- 首先因为需要保存每个向量的坐标,而每个坐标都是一个 浮点数 ,占用的内存就已经非常大了。
- 除此之外,还需要维护聚类中心和每个向量的聚类中心索引,这也会占用大量的内存。
对于第一个问题,可以通过量化(Quantization)的方式解决,也就是常见的有损压缩。
假设图片检索库有1000万张图片,每张图片提取多个128维的特征向量,把这128维向量分成8个短向量,每个短向量是16维,也就是说检索库总共包含1000万x8这么多个16维的短向量。
如果当做2维矩阵的话就是1000万行x8列,每一列就是1000万个的短向量,每一列就是由每个原始128维向量对应16维子向量组成。 图片
图片
把每一列的子向量都用 k-means 聚类为 256 类,每一个短向是我们都找到他属于一堆短向量的256类中的哪一类。这样每一行的8个短向量,都会对应于各自列的256类中的一个(一共有8个独立的256类),用0-255表示(也叫码字)。
从存储上来说是 8/16xsizeof(type),type是如 foat32,float16等等,比如原来16个foat16的向量,变成了一个8bt的值,也就是1/32(保存有256个类的中心数据,不过对比1000万个数据来说已经很小啦)。
现在128维向量,由8个8bit的数字组成。
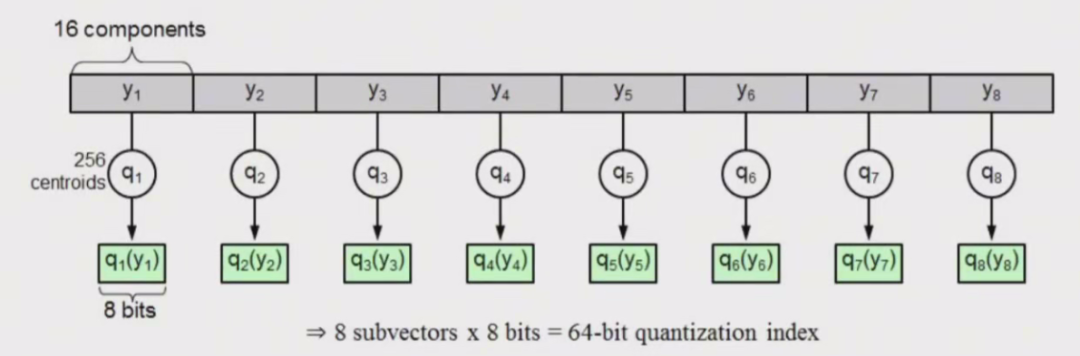 图片
图片
距离计算
查询x的时候,也需要把x先PQ量化
对称距离计算:直接使用两个压缩向量x,y的索引值所对应的码字q(x),q(y)之间的距离代替之,而q(x),q(y)之间的距离可以离线计算,相当于计算两个子类中心的距离可以把q(x),q(y)之间的距离制作成查找表,只要按照压缩向量的索引值进行对应的查找就可以了,所以速度非常快,每k=256个类别对应256x256个距离,一共只需要8x256x256个距离。
非对称距离计算:使用x,q(y)之间的距离代替x,y之间的距离,其中x是查询向量。虽然y的个数可能有上百万个,但是q(y)的个数只有k=256个,对于每个x,我们只需要在输入x之后先计算一遍x和k个q(y)的距离,相当于计算 x和每个子类中心的距离。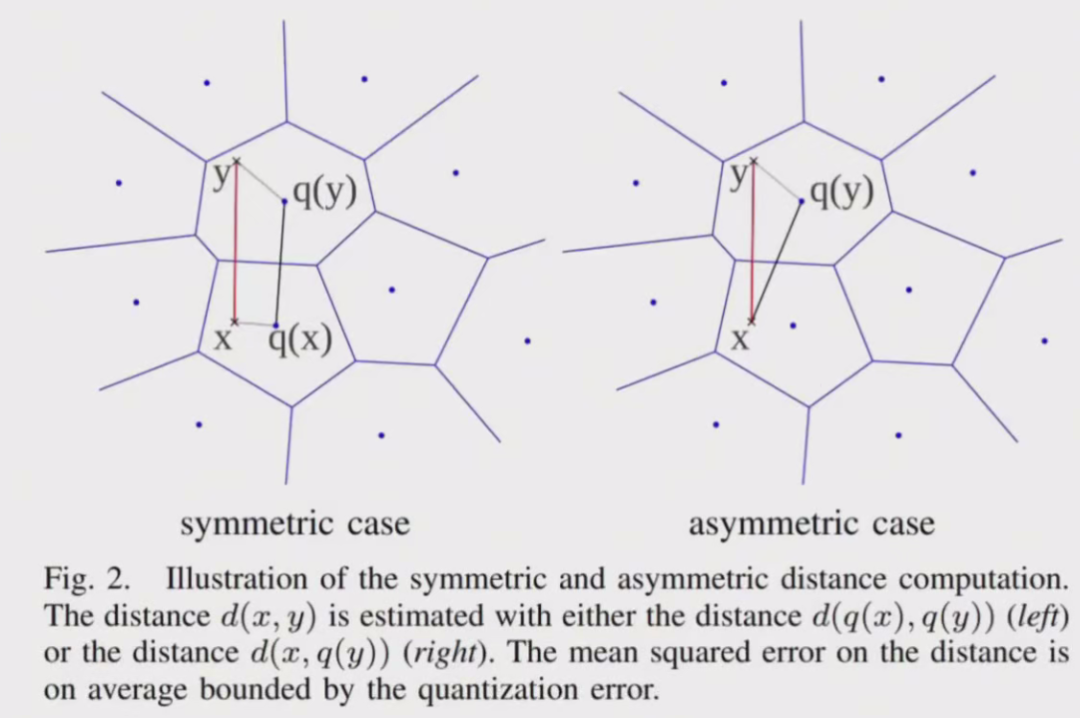 图片
图片
(2)分层小世界导航(HNSW)
除了聚类以外,也可以通过构建树或者构建图的方式来实现近似最近邻搜索。
这种方法的基本思想是每次将向量加到数据库中的时候,就先找到与它最相邻的向量,然后将它们连接起来,这样就构成了一个图。
当需要搜索的时候,就可以从图中的某个节点开始,不断的进行最相邻搜索和最短路径计算,直到找到最相似的向量。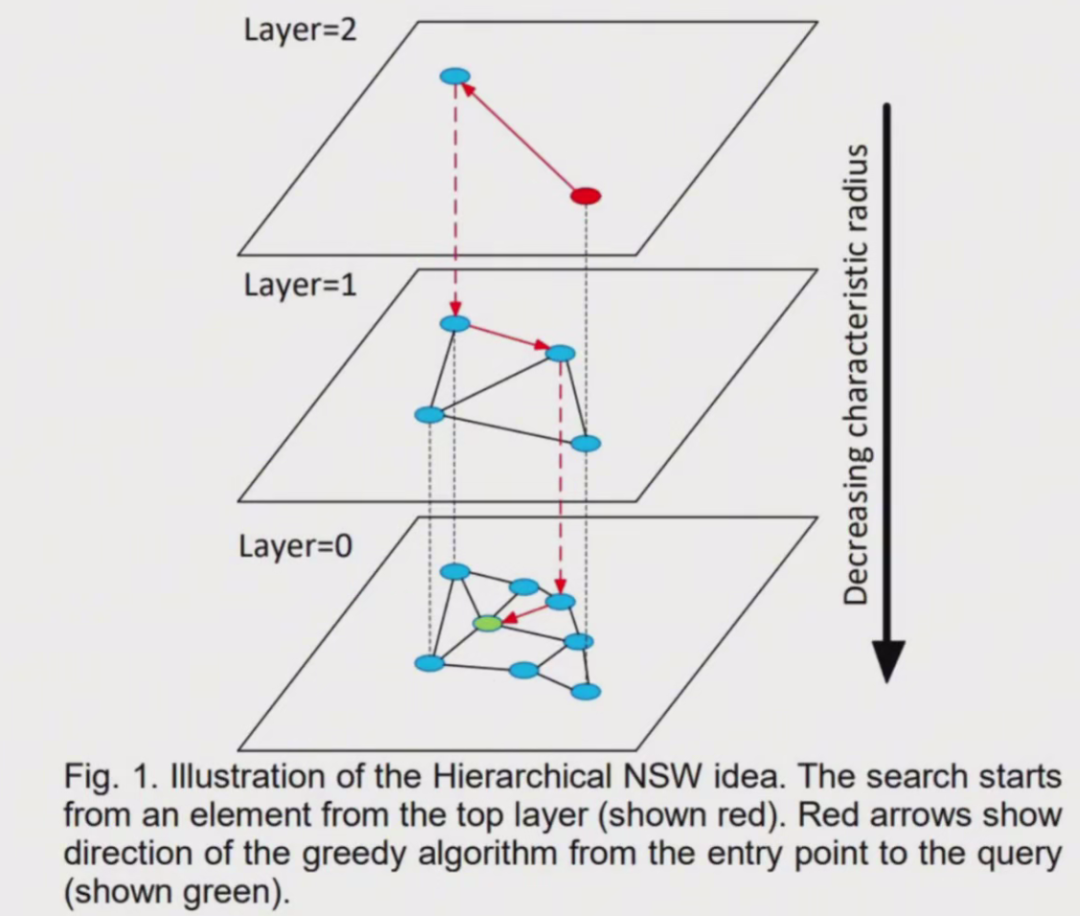 图片
图片
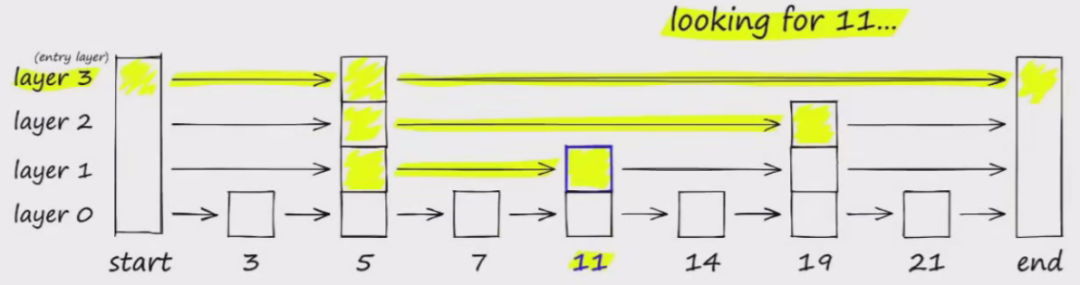
使用类似跳表算法,如下图要搜索跳表,从最高层开始,沿着具有最长“跳过”的边向右移动。
如果发现当前节点的值大于要搜索的值,表示超过了目标,因此我们会在下一级中向前一个节点。
 图片
图片
HNSW 继承了相同的分层格式,最高层具有更长的边缘(用于快速搜索),而较低层具有较短的边缘(用于准确搜索)。
具体来说,可以将图分为多层,每一层都是一个小世界,图中的节点都是相互连接的。
而且每一层的节点都会连接到上一层的节点,当需要搜索的时候,就可以从最上层开始,因为最上层的节点之间距离很长,可以减少搜索的时间,然后再逐层向下搜索,又因为最下层相似节点之间相互关联,所以可以保证搜索的质量,能够找到最相似的向量。
HNSW 算法是一种经典的空间换时间的算法,它的搜索质量和搜索速度都比较高,但是它的内存开销也比较大,因为不仅需要将所有的向量都存储在内存中,还需要维护一个图的结构,也同样需要存储。所以这类算法需要根据实际的场景来选择。
(3)局部敏感哈希(LSH)
局部敏感哈希(Locality Sensitive Hashing,LSH)也是一种使用近似最近邻搜索的索引技术。它的特点是快速,同时仍然提供一个近似、非穷举的结果。
LSH 使用一组哈希函教将相似向量映射到“桶”中,从而使相似向量具有相同的哈希值,这样,就可以通过比较哈希值来判断向量之间的相似度。
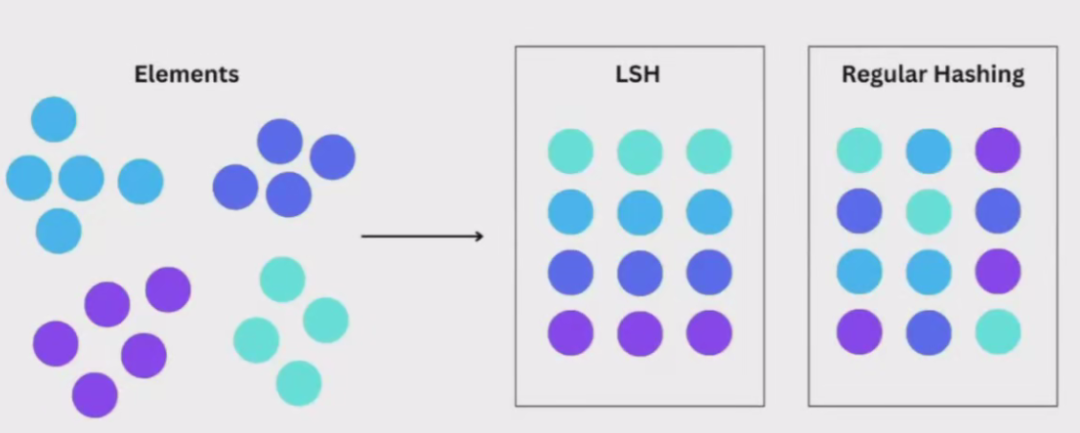 图片
图片
传统hash算法通常设计的哈希算法都是力求减少哈希碰撞的次数,因为哈希函数的搜索时间复杂度是 O(1)。
如果存在哈希碰撞,即两个不同的关键字被映射到同一个桶中,那么就需要使用链表等教据结构来解决冲突。
搜索的时间复杂度通常是 O(n),其中n是链表的长度。为了提高哈希函数搜索效率,会让哈希函数碰撞概率尽可能小。
局部敏感哈希 LSH
但是在向量搜索中,我们的目的是为了找到相似的向量,可以专门设计一种哈希函数,使得哈希碰撞的概率尽可能高,并且位置越近或者越相似的向量越容易碰撞,这样相似的向量就会被映射到同一个桶中。
在搜索特定向量时,为了找到给定查询向量的最近邻居,使用相同的哈希函教将类似向量“分桶“到哈希表中。
查询向量被散列到特定表中,然后与该表中的其他向量进行比较以找到最接近的匹配项。
这种方法比搜索整个数据集要快得多,因为每个哈希表桶中的向是远少于整个空间中的向量数。
其实就是将高维数据转化为低维数据,同时还能在一定程度上保持原始数据的相似性。
但 LSH 是不确定的,是概率性的,有可能将两个原本很相似的数据映射成两个不同的 hash 值,或者原本不相似的数据映射成同一hash值。
这是高维数据降维过程中所不能避免的(因为降维势必会造成某种程度上数据的失真),可以设计LSH 让参数控制出现这种错误的概率。
Milvus 的存储设计
Milvus是一个高性能的向量 数据库 ,专为处理大规模向量数据而设计。它采用了一种混合存储架构,结合了内存存储和磁盘存储的优点,以提高数据处理的效率和灵活性。
Milvus 内存存储
Milvus利用内存存储进行高效的数据处理和实时查询。当数据被插入时,首先存储在内存中。内存存储的主要优点是速度快,可以实现低延迟的实时查询。
Milvus 磁盘存储
为了持久化数据,Milvus会定期将内存中的数据刷写到磁盘上。
磁盘存储的主要优点是容量大,可以存储海量的数据。通过这种方式,Milvus既能提供高效的查询性能,又能保证数据的持久性。
Milvus 数据存储架构的设计思想
Milvus的数据存储架构设计思想是结合内存和磁盘的优点,达到性能和持久性之间的平衡。
这种设计有以下几个优点:
(1) 高性能:通过内存存储,Milvus可以实现低延迟的实时查询,满足高性能需求。
(2) 大容量:通过磁盘存储,Milvus可以存储海量数据,满足大规模数据处理需求。
(3) 数据安全:通过定期将内存数据刷写到磁盘,Milvus保证了数据的持久性和安全性。
(4) 灵活性:混合存储架构使得Milvus在处理不同规模和类型的数据时具有更大的灵活性。
数据存储架构设计思想高性能大容量数据安全灵活性
Milvus 数据存储的架构和设计思想
Milvus的数据存储架构结合了内存和磁盘的优点,既能提供高效的查询性能,又能保证数据的持久性。
以下是数据存储架构的详细设计思想和优点:
1. 混合存储架构
Milvus采用混合存储架构,将数据存储在内存和磁盘中。
内存存储用于高效的实时查询,而磁盘存储用于持久化数据。
通过这种方式,Milvus既能提供高性能的查询,又能保证数据的持久性。
2. 分层存储
数据分层存储的设计使得Milvus能够根据数据的重要性和访问频率,动态调整存储策略。
热数据存储在内存中,冷数据存储在磁盘上。
这种分层存储的设计提高了数据的访问效率。
3. 高并发支持
Milvus的数据存储架构支持高并发访问,能够处理大量并发查询请求。
通过优化内存和磁盘的读写操作,Milvus实现了高并发访问下的高效查询。
4. 自动化运维
Milvus的数据存储架构支持自动化运维,
能够自动进行数据备份、故障恢复等操作。
通过自动化运维,Milvus保证了数据的安全性和可用性。
数据存储架构设计思想混合存储架构分层存储高并发支持自动化运维内存存储磁盘存储热数据冷数据
优点
(1) 高性能:通过内存存储,Milvus能够提供低延迟的实时查询。
(2) 大容量:通过磁盘存储,Milvus能够存储海量数据。
(3) 数据安全:通过定期将内存数据刷写到磁盘,Milvus保证了数据的持久性和安全性。
(4) 灵活性:混合存储架构使得Milvus在处理不同规模和类型的数据时具有更大的灵活性。
(5) 高并发:通过优化内存和磁盘的读写操作,Milvus实现了高并发访问下的高效查询。
(6) 自动化:自动化运维保证了数据的安全性和可用性,减少了运维成本。
数据存储架构优点高性能大容量数据安全灵活性高并发自动化
Milvus的 索引类型 与适用场景
索引是提高检索效率的重要手段。
Milvus提供了多种索引类型,以适应不同的应用场景。
以下是Milvus支持的主要索引类型及其适用场景:
Milvus索引类型
- IVF 倒排文件
- HNSW
- ANNOY
- FLAT
- DISKANN
索引类型 | 适用场景 | 特点 | 典型参数 |
IVF | 大规模数据,平衡速度与精度 | 聚类+倒排列表,查询可控 |
|
HNSW | 高维数据,高精度要求 | 分层图结构,精度优先 |
|
ANNOY | 中等规模,内存敏感场景 | 随机森林,低内存占用 |
|
FLAT | 小数据,100%召回率 | 暴力搜索,精确匹配 | 无需参数 |
DISKANN | 超大规模数据,磁盘优化 | 磁盘驻留索引,减少内存依赖 |
|
1、IVF(Inverted File) 倒排文件
IVF(Inverted File)是一种基于倒排文件的索引结构,通过对向量进行聚类,创建倒排列表。
每个倒排列表存储一组相似的向量,从而加速近似最近邻搜索。
IVF 倒排文件 适用场景
IVF适用于大规模数据集,特别是在需要快速近似搜索的场景中。
IVF 在查询速度和存储空间之间取得了良好的平衡。
IVF 倒排文件 架构
IVF索引的构建过程包括以下几个步骤:
(1) 聚类:使用K-means算法将数据集划分为若干个簇。
(2) 创建倒排列表:每个簇对应一个倒排列表,存储属于该簇的向量。
(3) 搜索:在查询时,首先找到与查询向量最近的簇,然后在该簇的倒排列表中进行精确搜索。
Java代码示例
import io.milvus.param.index.CreateIndexParam;
public class MilvusIVFExample {
public static void main(String[] args) {
MilvusClient client = connectMilvus();
// 创建IVF索引
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("example_collection")
.withFieldName("vector")
.withIndexType("IVF_FLAT") // IVF_FLAT类型索引
.withMetricType("L2") // 使用L2距离度量
.withParamsInJson("{"nlist": 128}") // IVF参数,nlist表示聚类中心数量
.build();
client.createIndex(createIndexParam);
System.out.println("IVF index created successfully!");
}
}python代码示例
from pymilvus import connections, utility, Collection, CollectionSchema, FieldSchema, DataType, index
// 连接Milvus
connections.connect("default", host="localhost", port="19530")
// 创建集合
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, "IVF示例集合")
collection = Collection("example_collection", schema)
// 创建IVF索引
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
}
collection.create_index("vector", index_params)
print("IVF index created successfully!")2、HNSW(Hierarchical Navigable Small World)
HNSW是一种基于图的索引结构,通过构建小世界图,实现高效的向量检索。
HNSW的核心思想是利用小世界特性,进行快速的近似搜索。
HNSW 适用场景
HNSW适用于高维向量数据集,尤其是在需要高精度搜索的场景中。它在查询速度和精度之间取得了良好的平衡。
HNSW 架构
HNSW索引的构建过程包括以下几个步骤:
(1) 构建层次结构:将向量按照不同层次进行组织,较高层次的节点连接较多,较低层次的节点连接较少。
(2) 构建小世界图:在每个层次构建小世界图,节点之间的连接遵循小世界特性。
(3) 搜索:在查询时,从最高层开始,通过小世界图的导航,逐层向下找到最相似的向量。
Java代码示例
import io.milvus.param.index.CreateIndexParam;
public class MilvusHNSWExample {
public static void main(String[] args) {
MilvusClient client = connectMilvus();
// 创建HNSW索引
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("example_collection")
.withFieldName("vector")
.withIndexType("HNSW") // HNSW类型索引
.withMetricType("L2") // 使用L2距离度量
.withParamsInJson("{"M": 16, "efConstruction": 200}") // HNSW参数,M和efConstruction分别表示图中最大连接数和构建时的effort
.build();
client.createIndex(createIndexParam);
System.out.println("HNSW index created successfully!");
}
}python代码示例
from pymilvus import connections, utility, Collection, CollectionSchema, FieldSchema, DataType, index
// 连接Milvus
connections.connect("default", host="localhost", port="19530")
// 创建集合
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, "HNSW示例集合")
collection = Collection("example_collection", schema)
// 创建HNSW索引
index_params = {
"index_type": "HNSW",
"metric_type": "L2",
"params": {"M": 16, "efConstruction": 200}
}
collection.create_index("vector", index_params)
print("HNSW index created successfully!")3、 ANNOY(Approximate Nearest Neighbors Oh Yeah)
ANNOY(Approximate Nearest Neighbors Oh Yeah)是一种基于随机树的索引结构,通过构建多棵随机树,实现近似最近邻搜索。
ANNOY的核心思想是利用随机树结构,进行快速的近似搜索。
ANNOY适用场景
ANNOY适用于中等规模的数据集,特别是在内存受限的场景中。它在查询速度和内存消耗之间取得了良好的平衡。
ANNOY架构
ANNOY索引的构建过程包括以下几个步骤:
(1) 构建随机树:通过随机选择数据点和分裂点,构建多棵随机树。
(2) 搜索:在查询时,利用多棵随机树进行搜索,并合并结果,找到近似最近邻。
Java代码示例
import io.milvus.param.index.CreateIndexParam;
public class MilvusANNOYExample {
public static void main(String[] args) {
MilvusClient client = connectMilvus();
// 创建ANNOY索引
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("example_collection")
.withFieldName("vector")
.withIndexType("ANNOY") // ANNOY类型索引
.withMetricType("L2") // 使用L2距离度量
.withParamsInJson("{"n_trees": 10}") // ANNOY参数,n_trees表示随机树的数量
.build();
client.createIndex(createIndexParam);
System.out.println("ANNOY index created successfully!");
}
}python代码示例
from pymilvus import connections, utility, Collection, CollectionSchema, FieldSchema, DataType, index
// 连接Milvus
connections.connect("default", host="localhost", port="19530")
// 创建集合
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, "ANNOY示例集合")
collection = Collection("example_collection", schema)
// 创建ANNOY索引
index_params = {
"index_type": "ANNOY",
"metric_type": "L2",
"params": {"n_trees": 10}
}
collection.create_index("vector", index_params)
print("ANNOY index created successfully!")4、 FLAT(Brute-force)
FLAT(Brute-force)是一种基于暴力搜索的索引结构,通过遍历所有向量进行精确搜索。
FLAT的核心思想是利用线性扫描,进行精确的最近邻搜索。
FLAT 适用场景
FLAT适用于小规模的数据集,特别是在需要高精度搜索的场景中。它在查询精度和计算开销之间取得了良好的平衡。
FLAT 架构
FLAT索引的构建过程非常简单,主要包括以下步骤:
(1) 存储向量:将所有向量存储在一个数组中。
(2) 搜索:在查询时,遍历所有向量,计算距离,找到最近邻。
FLAT原理存储向量数组存储搜索遍历所有向量计算距离找到最近邻
Java代码示例
import io.milvus.param.index.CreateIndexParam;
public class MilvusFLATExample {
public static void main(String[] args) {
MilvusClient client = connectMilvus();
// 创建FLAT索引
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("example_collection")
.withFieldName("vector")
.withIndexType("FLAT") // FLAT类型索引
.withMetricType("L2") // 使用L2距离度量
.build();
client.createIndex(createIndexParam);
System.out.println("FLAT index created successfully!");
}
}5、DISKANN(Disk-based Approximate Nearest Neighbors)
DISKANN(Disk-based Approximate Nearest Neighbors)是一种基于磁盘的近似最近邻搜索索引,通过将数据存储在磁盘上,实现大规模数据集的高效检索。
DISKANN的核心思想是利用磁盘存储,进行快速的近似搜索。
DISKANN适用场景
DISKANN适用于超大规模的数据集,特别是在内存受限但需要高效检索的场景中。它在存储容量和查询速度之间取得了良好的平衡。
DISKANN架构
DISKANN索引的构建过程包括以下几个步骤:
(1) 构建索引:将数据分块并存储在磁盘上,创建索引文件。
(2) 加载索引:在查询时,从磁盘加载索引文件。
(3) 搜索:利用磁盘上的索引,进行快速的近似搜索。
DISKANN原理构建索引数据分块存储在磁盘加载索引从磁盘加载搜索利用索引快速搜索
Java代码示例
import io.milvus.param.index.CreateIndexParam;
public class MilvusDISKANNExample {
public static void main(String[] args) {
MilvusClient client = connectMilvus();
// 创建DISKANN索引
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("example_collection")
.withFieldName("vector")
.withIndexType("DISKANN") // DISKANN类型索引
.withMetricType("L2") // 使用L2距离度量
.withParamsInJson("{"index_file_size": 1024}") // DISKANN参数,index_file_size表示索引文件的大小
.build();
client.createIndex(createIndexParam);
System.out.println("DISKANN index created successfully!");
}
}python代码示例
from pymilvus import connections, utility, Collection, CollectionSchema, FieldSchema, DataType
// 连接Milvus
connections.connect("default", host="localhost", port="19530")
// 创建集合
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, "DISKANN示例集合")
collection = Collection("example_collection", schema)
// 创建DISKANN索引
index_params = {
"index_type": "DISKANN",
"metric_type": "L2",
"params": {"index_file_size": 1024}
}
collection.create_index("vector", index_params)
print("DISKANN index created successfully!")向量数据库Milvus的索引选择和优化策略:
索引选择策略
维度一:根据数据规模选择:
- 小规模数据集:当数据集规模较小时,如千级向量数据,FLAT索引是一个不错的选择。它能够提供精确的搜索结果,并且查询时间相对较短。
- 中等规模数据集:对于中等规模的数据集,如十万级向量数据,ANNOY索引较为合适。它能在查询速度和内存消耗之间取得良好平衡,适合内存受限的场景。
- 大规模数据集:在处理大规模数据集时,IVF和DISKANN是常用的索引类型。IVF通过聚类和倒排列表加速查询,适用于数据量较大且对查询速度有一定要求的场景。DISKANN则通过磁盘存储实现大规模数据集的高效检索,适合内存资源有限但需要处理大规模数据的情况。
- 高维向量数据集:对于高维稠密向量数据,如文本嵌入、图像特征等,HNSW索引表现出色。它基于小世界网络的思想,能维持较高的查询精度,同时提供较快的查询速度。
维度二:根据查询精度要求选择:
- 高精度要求:如果应用场景对查询精度要求极高,如一些需要精确匹配的检索任务,FLAT索引是首选,因为它能保证100%的召回率,提供精确的搜索结果。此外,IVF_FLAT和HNSW等索引类型也可以通过调整参数来提高查询精度。
- 适度精度要求:在对查询精度要求不是绝对严格的情况下,可以选择一些在精度和速度之间取得平衡的索引类型,如IVF、ANNOY等。这些索引能够在一定程度上满足查询精度的需求,同时提供较快的查询速度。
维度三:根据存储和计算资源选择:
- 存储资源充足:当存储资源较为充足时,可以选择一些存储开销相对较大的索引类型,如HNSW、IVF_FLAT等。这些索引类型通常能够提供更好的查询性能。
- 存储资源有限:如果存储资源受限,PQ索引是一个较好的选择。它通过量化的方式减少存储和计算开销,适用于内存和存储资源有限的场景。
索引优化策略
一:调整索引参数:
- IVF相关参数:对于IVF类索引,nlist参数表示簇的数量,一般建议nlist=4×sqrt(N),其中N为数据量。例如,对于100万数据量,nlist可设置为2000左右。nprobe参数表示查询时搜索的簇的数量,nprobe越大,召回率越高,但查询性能可能下降。通常可以从nprobe=16开始尝试,根据实际情况进行调整。
- HNSW相关参数:M参数控制每个节点的最大连接数,M越大,查询精度越高,但内存消耗也越大,一般建议设置在8-32之间。efConstruction参数用于控制图的构建精度,值越大,构建时会搜索更多的候选节点,精度越高,但构建时间也越长。efSearch参数在查询时使用,值越大,查询精度越高,但查询时间也会相应增加。
- PQ相关参数:m参数表示将每个向量拆分成的子向量数量,m越大,精度越高,但存储需求和计算开销也越大。nbits参数表示每段量化器占用的bit数目,默认为8,一般不建议调整。
二:结合索引类型:在某些场景下,可以考虑结合多种索引类型来提高查询效率和精度。例如,将IVF和HNSW结合,先通过IVF缩小搜索空间,再在每个簇内部使用HNSW进行精确的相似度计算,适用于数据量大且需要高精度的场景。
三:定期更新索引:随着数据的不断插入和更新,索引的性能可能会受到影响。因此,需要定期对索引进行更新和重建,以保证查询性能。例如,当数据量增加到一定程度或查询性能明显下降时,可以考虑重建索引。
四:监控和评估索引性能:在实际应用中,需要持续监控和评估索引的性能,包括查询延迟、吞吐量、召回率等指标。通过分析这些指标,可以及时发现索引性能问题,并采取相应的优化措施。
五:硬件资源优化:合理配置和优化硬件资源也对索引性能有重要影响。例如,增加内存容量、使用高速存储设备、优化网络带宽等,都可以提高Milvus的查询性能和索引构建速度
Milvus 的默认索引机制
Milvus 不主动创建任何索引,当未显式指定索引时,默认使用 FLAT(暴力搜索)模式进行向量检索。
FLAT(暴力搜索)模式 模式特点:
- 无需预处理:数据插入后直接可查询
- 100%召回率:保证搜索结果的绝对准确性
- 线性复杂度:查询时间与数据量成正比
行为表现
- 适用场景:数据量 < 100万的低频查询验证场景
- 性能特征:CPU单核查询速度约 200 QPS(128维,100万数据)
- 存储要求:原始向量数据量 × 内存系数(如100万128维向量占用约500MB内存)
IVF 是常用的索引类型
IVF(Inverted File)是一种基于倒排文件的索引结构,通过对向量进行聚类,创建倒排列表。
每个倒排列表存储一组相似的向量,从而加速近似最近邻搜索。
IVF 倒排文件 适用场景
IVF适用于大规模数据集,特别是在需要快速近似搜索的场景中。
IVF 在查询速度和存储空间之间取得了良好的平衡。
创建IVF索引 的 python代码示例
from pymilvus import connections, utility, Collection, CollectionSchema, FieldSchema, DataType, index
// 连接Milvus
connections.connect("default", host="localhost", port="19530")
// 创建集合
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, "IVF示例集合")
collection = Collection("example_collection", schema)
// 创建IVF索引
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
}
collection.create_index("vector", index_params)
print("IVF index created successfully!")查询 IVF索引 的 python代码示例
from pymilvus import connections, Collection
import numpy as np
// 连接到Milvus服务
connections.connect("default", host="localhost", port="19530")
// 获取已存在的集合
collection = Collection("example_collection")
// 加载数据到内存(查询前必须步骤)
collection.load()
// 生成测试查询向量(128维)
query_vectors = np.random.rand(2, 128).tolist() # 同时查询2个向量
// 设置搜索参数
search_params = {
"data": query_vectors,
"anns_field": "vector", # 指定向量字段
"param": {
"metric_type": "L2", # 距离计算方式与索引一致
"params": {"nprobe": 10} # 搜索簇数量参数
},
"limit": 5, # 返回每个查询的前5条结果
"output_fields": ["vector"], # 指定返回向量字段
"consistency_level": "Bounded" # 一致性级别设置
}
// 执行向量搜索
results = collection.search(**search_params)
// 解析查询结果
for i, result in enumerate(results):
print(f"
=== 查询向量 {i+1} 的匹配结果 ===")
for hit in result:
print(f"ID: {hit.id} | 距离: {hit.distance:.4f}")
print(f"存储向量: {hit.entity.get('vector')[:5]}...") # 显示前5个维度








