


基于 EasyExcel 实现高效导出
近期梳理文章,也看到自己早期写的关于基于easy excel导出的文章,遂打算重新整理梳理一下,当初对于这个工具类的使用技巧,希望对你有帮助。
本文的需求是将一个百万数据量MySQL8的数据导出到excel的功能,经查阅资料并结合实际场景需求整理出这样一套比较精简且使用的导出方案。

一、简述案例背景
为了更好演示笔者的方案,这里给出一个演示的需求,该需求是要求导出一个用户表的数据,该数据表是一张用户表,包含id和name,该用户表数据量在300w左右,以自增id作为主键,而功能要求我们在一分钟之内完成百万数据导出到excel。需要注意的是,我们导出的excel格式为xlsx,它的每一个sheet只能容纳100w的数据,这也就意味着我们的数据必须以100w作为批次写到不同的sheet中。
CREATE TABLE`t_user` (
`id`bigintNOTNULL,
`name`varchar(100) DEFAULTNULL,
`count`intDEFAULTNULL
) ENGINE=InnoDBDEFAULTCHARSET=utf8mb3;二、三个核心问题说明
我们先来说说需要解决的问题:
- 如果一次性查询300w左右的数据可能会占据大量的内存,如果对象字段很多的情况下,很可能出现内存溢出,我们要如何解决?
- 每个excel文件都有sheet,并且每个sheet只能容纳100w左右的数据,对于这个问题我们要如何解决?
- 数据写入到excel时,有没有合适的工具推荐?
三、如何解决查询问题
1. 分页查询
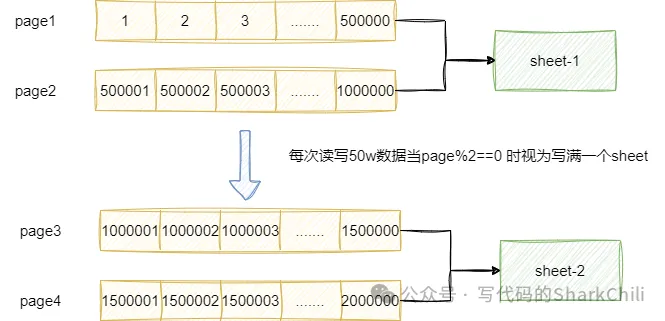
对于问题1我们两套解决方案: 方案1是采用分页查询的方式进行查询,参考自己堆内存的配置推算每次分页查询的数据量。因为问题1采用了分页查询,我们完全可以通过分页查询的次数推算出一个sheet写入了多少数据,例如我们每次分页查询50w的数据,那么每两次就可以视为一个sheet写满了,我们就可以创建一个新的sheet写入数据。
这里需要注意一点,因为我们分页查询面对的是百万级别的数据,所以随着分页的推进势必出现深分页导致查询效率势降低,所以为了提高分页查询的效率,我们可以利用查询数据有序的特性,通过id作为偏移进行分页查询。
例如我们第一次分页查询的sql语句为:
select * from t_user limit 500000 ;假如我们不以id作为索引,那么第二次的分页查询sql则是:
select * from t_user limit 500000,500000 ;查看该查询执行计划,可以看到该查询一次性查询到几乎全表的数据,并且还走了全秒扫描性能可想而知:
id|select_type|table |partitions|type|possible_keys|key|key_len|ref|rows |filtered|Extra|
--+-----------+------+----------+----+-------------+---+-------+---+-------+--------+-----+
1|SIMPLE |t_user| |ALL | | | | |2993040| 100.0| |因为我们的数据表是id自增的,所以我们查询的时候完全可以基于该特性通过上一次查询到的id作为筛选条件进行分页查询。
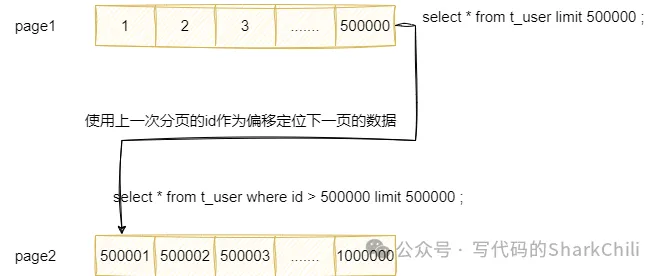
所以我们的分页查询可直接改为:
select * from t_user where id > 500000 limit 500000 ;再次查看执行计划可以发现该查询为范围查询,查询到的数据量也少了很多,性能显著提升:
id|select_type|table |partitions|type |possible_keys|key |key_len|ref|rows |filtered|Extra |
--+-----------+------+----------+-----+-------------+-------+-------+---+-------+--------+-----------+
1|SIMPLE |t_user| |range|PRIMARY |PRIMARY|8 | |1496520| 100.0|Using where|2. 流式查询
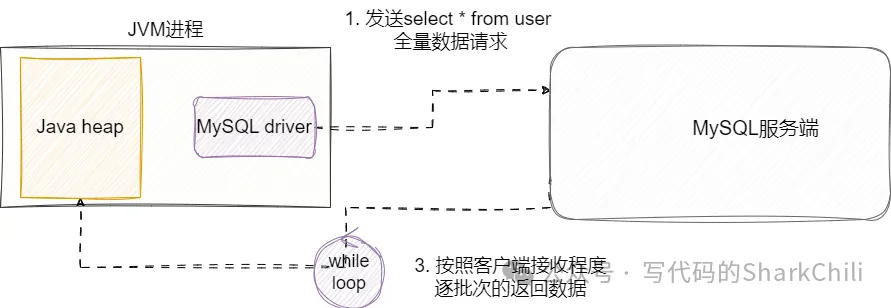
另外一种解决方案就是流式查询,通过流式查询将SQL语句直接提交给MySQL服务端,让服务端按照客户端程序接受程度不断推送数据,然后我们的java程序每次收集50w的数据,再写入到对应的excel文件中:
四、选用合适的导出工具
因为市面上比较多的excel导出工具,常见的就是Apache poi,但是它们的操作对于内存的消耗非常严重,对于我们这种大数据量的写入不是很友好,所以笔者更推荐使用阿里的EasyExcel,它对poi进行一定的封装和优化,同等数据量写入使用的内存更小,引用Easy Excel的说法:
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。 easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便
所以我们准备引入这个工具的依赖进行excel文件处理:
com.alibaba
easyexcel
4.0.3
解决上述问题之后,我们就可以说说代码实现思路了,以本文示例来说,有一张用户表有300w左右的数据,每次查询时只需查询id(4字节)和name(10字节),按照64位的操作系统来说,一个user对象所占用的内存大小为:
object header +pointer+id字段+name字段大小=8+8+4+10=30字节因为java对象内存大小需要16位对齐,需要补齐2个字节,所以实际大小为32字节,按照笔者对于堆内存的配置。
对于实用分页查方案来说,每次查询50w条数据是允许的,所以每次从数据库读取数据并转为java对象,也只需要32*500000/1024即15M内存即可。
确定每次分页查询50w条数据之后,我们就需要确定一共需要查询几个分页,然后就可以根据pageSize确定查询的页数。 因为每次查询50w条数据,所以每两次完成分页查询和写入基本上一个sheet就会满了,这时候我们就需要创建一个新的sheet进行数据写入了。
五、基于分页查询导出的落地示例
对于分页查询导出,我们的大体实现步骤为:
- 查询目标数据量大小。
- 根据每次分页大小确定查询页数(或使用流式查询)。
- 根据页数大小进行遍历,进行分页查询,并将数据写入到文件中。
- 基于页数确定sheet切换时机。
对应的我们也给出分页查询和导出的代码示例,逻辑和上述说明基本一致:
long start = System.currentTimeMillis();
UserMapper userMapper = SpringUtil.getBean(UserMapper.class);
//计算总的数据量
int count = Math.toIntExact(userMapper.selectCount(Wrappers.emptyWrapper()));
//获取分页总数
int queryCount = 50_0000;
int pageCount = count % queryCount == 0 ? count / queryCount : count / queryCount + 1;
log.info("pageCount: {}", pageCount);
//设置导出的文件名
String fileName = "F://tmp/result.xlsx";
//设置excel的sheet号码
int sheetNo = 1;
//设置第一个sheet的名字
String sheetName = "sheet-" + sheetNo;
// 创建writeSheet
WriteSheet writeSheet = EasyExcel.writerSheet(sheetNo, sheetName).build();
//记录每次分页查询的最大值
Long maxId = null;
//指定文件
try (ExcelWriter excelWriter = EasyExcel.write(fileName, User.class).build()) {
//写入每一页分页查询的数据
for (int i = 1; i <= pageCount; i++) {
// 分页去数据库查询数据 这里可以去数据库查询每一页的数据
long queryStart = System.currentTimeMillis();
List userList = null;
//如果是第一次则直接进行分页查询,反之基于上一次分页查询的分页定位实际偏移量,筛选前n条数据以达到分页效果
PageHelper.startPage(1, queryCount, false);
if (i == 1) {
userList = userMapper.selectList(Wrappers.emptyWrapper());
} elseif (maxId != null) {
QueryWrapper wrapper = new QueryWrapper();
wrapper.gt("id", maxId);//相当于where id=1
userList = userMapper.selectList(wrapper);
PageHelper.startPage(0, queryCount, false);
}
//更新下一次分页查询用的id
if (CollUtil.isNotEmpty(userList)) {
maxId = userList.get(userList.size() - 1).getId();
log.info("maxId: {}", maxId);
}
long queryEnd = System.currentTimeMillis();
log.info("数据大小:{},写入sheet位置:{},耗时:{}", userList.size(), sheetName, queryEnd - queryStart);
long writeStart = System.currentTimeMillis();
excelWriter.write(userList, writeSheet);
long writeEnd = System.currentTimeMillis();
log.info("本次写入耗时:{}", writeEnd - writeStart);
//如果% 2 == 0,则说明一个sheet写入了50*2即100w的数据,需要创建新的sheet进行写入
if (i % 2 == 0) {
sheetName = "sheet-" + (++sheetNo);
writeSheet = EasyExcel.writerSheet(sheetNo, sheetName).build();
log.info("写满一个sheet,切换到下一个sheet:{}", sheetName);
}
}
}
long total = System.currentTimeMillis() - start;
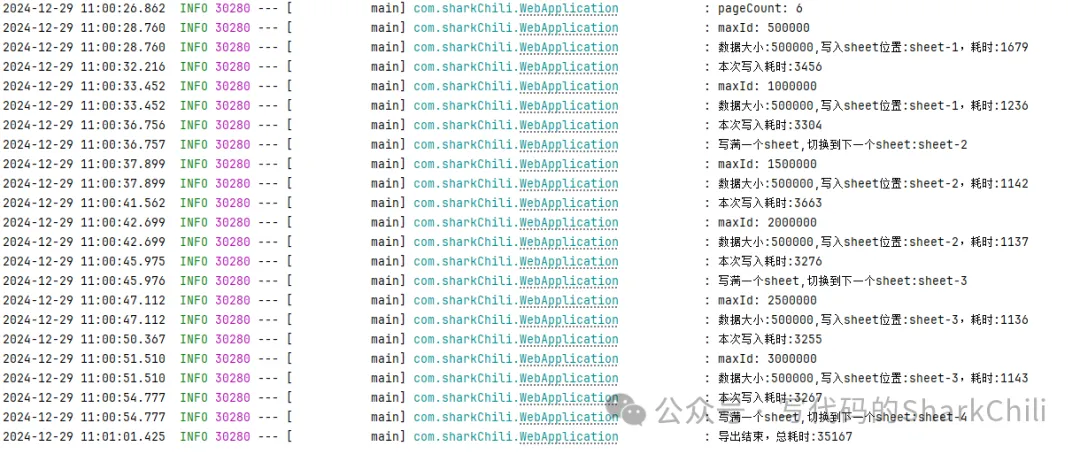
log.info("导出结束,总耗时:{}", total); 可能会有读者好奇笔者这个50w的数值设计思路是什么,除了考虑避免OOM以外,还考虑到每个sheet只能写入100w条的数据,为了方便通过分页查询的轮次确定当前写入的数据量大小,笔者尝试过20w、50w。 最终在压测结果上看出,50w读写耗时虽然是20w的2倍,但是IO次数却不到20w查询的二分之一,通过更少的IO操作获得更好的执行性能。
最终300w数据导出耗时大约35s,整体性能表现还是可以的:
六、使用流式编程导出(推荐)
对应我们也给出流式编程的导出方案,笔者针对查询语句做了流式编程的配置,通过这些配置保证MySQL服务端基于自己的迭代游标按照客户端处理效率按照顺序的数据流不断传输给客户端:
@Select("select * from user ")
@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = Integer.MIN_VALUE)
@ResultType(User.class)
void selectListByStream(ResultHandler handler); 关于流式查询的更多内容,建议读者参考笔者写的这篇文章:《MySQL 流式查询的奥秘与应用解析》。
基于上述查询语句,我们不断拿到user对象,因为流式查询避免的频繁的IO分页请求,所以真正的写入瓶颈点在于写入到excel文件中,所以笔者在流式聚合数据时是通过每1w条进行一次写入,保持每100w切换一次sheet。
需要注意的是因为笔者的ResultHandler用的是lambda表达式,为了让编译器通过编译所有的计数、sheet等修改操作都是通过原子类CAS完成的,具体读者可以参考笔者的注释:
long start = System.currentTimeMillis();
UserMapper userMapper = SpringUtil.getBean(UserMapper.class);
//设置导出的文件名
String fileName = "F://tmp/result.xlsx";
//设置excel的sheet号码,用原子类保证可以在lambda表达式中通过编译
AtomicInteger sheetNo = new AtomicInteger(1);
//设置第一个sheet的名字,用原子类保证可以在lambda表达式中通过编译
AtomicReference sheetName = new AtomicReference<>("sheet-" + sheetNo.get());
// 创建writeSheet,用原子类保证可以在lambda表达式中通过编译
WriteSheet writeSheet = EasyExcel.writerSheet(sheetNo.get(), sheetName.get()).build();
AtomicReference writeSheetRef = new AtomicReference<>(writeSheet);
List userList = new ArrayList<>();
AtomicReference> userListRef = new AtomicReference<>(userList);
//记录导出的size
AtomicInteger atomicCount = new AtomicInteger(0);
//指定文件
try (ExcelWriter excelWriter = EasyExcel.write(fileName, User.class).build()) {
userMapper.selectListByStream(res -> {
//存入list中
User user = res.getResultObject();
userListRef.get().add(user);
atomicCount.incrementAndGet();
//50w执行一次导出写入
if (userListRef.get().size() % 1_0000 == 0) {
long writeStart = System.currentTimeMillis();
//写入到文件
excelWriter.write(userListRef.get(), writeSheetRef.get());
//清空列表内部数据
userListRef.get().clear();
long writeEnd = System.currentTimeMillis();
log.info("本次写入耗时:{}", writeEnd - writeStart);
}
//写入100w条后,切换sheet
if (atomicCount.get() % 100_0000 == 0) {
//自增sheetNo
sheetNo.incrementAndGet();
//修改sheetName
sheetName.set("sheet-" + sheetNo.get());
//写入文件
writeSheetRef.set(EasyExcel.writerSheet(sheetNo.get(), sheetName.get()).build());
log.info("写满一个sheet,切换到下一个sheet:{}", sheetName);
}
});
//检查是否还有未写入的文件
if (CollectionUtil.isNotEmpty(userList)) {
log.info("存在未写入完成的数据,size:{}", userList.size());
excelWriter.write(userList, writeSheetRef.get());
}
long total = System.currentTimeMillis() - start;
log.info("导出结束,总耗时:{}", total);
} catch (Exception e) {
thrownew RuntimeException(e);
} 最终这种方案的执行耗时在最好的情况下差不多30s左右,总的来说流式查询天然内存友好且游标式顺序前进的特定,对于这种并发场景下的数据导出是非常友好的,所以这种方案也是笔者比较推荐的方案:

七、小结
以上便是笔者的百万级别数据导出的落地方案,可以看出笔者针对分页查询导出的方案着重在分页查询大小和分页查询sql上进行重点优化,通过平衡分页查询的数据量和IO次数找到合适的pageSize,再通过上一次分页查询结果定位下一次查询的id作为where条件,避免分页查询时的全秒扫描以得到符合业务需求的高性能sql。
对于流式查询,因为流式查询的特定,笔者在优化时更着重于找到写入到文件这块的耗时上,通过找到IO写入的平衡点找到最佳写入阈值,从而完成百万级别数据的高效导出。









