


使用FastAPI和Redis Caching加快机器学习模型推理

译者 | 布加迪
审校 | 重楼
Redis 是一款开源内存数据结构存储系统,是机器学习应用领域中缓存的优选。它的速度、耐用性以及支持各种数据结构使其成为满足实时推理任务的高吞吐量需求的理想选择。
我们在本教程中将探讨Redis缓存在机器学习工作流程中的重要性。我们将演示如何使用FastAPI和Redis构建一个强大的机器学习应用程序。本教程介绍如何在Windows上安装Redis、在本地运行Redis以及如何将其集成到机器学习项目中。最后,我们将通过发送重复请求和独特请求来测试该应用程序,以验证Redis缓存系统正常运行。
为什么在机器学习中使用Redis缓存?
在当今快节奏的数字环境中,用户期望机器学习应用程序能够立即获得结果。比如说,使用推荐模型向用户推荐产品的电商平台。如果实施Redis来缓存重复请求,该平台就可以显著缩短响应时间。
当用户请求产品推荐时,系统先检查该请求是否已被缓存。如果已缓存,则在几微秒内返回缓存的响应,从而提供无缝的体验。如果没有缓存,模型就处理该请求,生成推荐,并将结果存储在Redis中供将来的请求使用。这种方法不仅提高了用户满意度,还优化了服务器资源,使模型能够高效地处理更多请求。
使用Redis构建网络钓鱼电子邮件分类应用程序
我们在本项目中将构建一个网络钓鱼电子邮件分类应用程序。整个过程包括加载和处理来自Kaggle的数据集,使用处理后的数据训练机器学习模型,评估其性能,保存经过训练的模型,最后构建带有Redis集成机制的FastAPI应用程序。
1. 设置
- 从Kaggle下载网络钓鱼电子邮件检测数据集,并将其放入到data/目录。
- 首先你需要安装Redis。在终端中运行以下命令安装Redis Python客户程序:
pip install redis- 如果你使用Windows系统,且未安装Windows Subsystem for Linux(WSL),请按照微软指南启用WSL,并从微软商店安装Linux发行版(比如Ubuntu)。
- WSL设置完成后,打开WSL终端,并执行以下命令安装Redis:
sudo apt update
sudo apt install redis-server- 要启动Redis服务器,请运行:
sudo service redis-server start你应该会看到一条确认消息,表明“redis-server”已成功启动。
2. 模型训练
训练脚本可加载数据集、处理数据、训练模型并将其保存在本地。
import joblib
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
def main():
# Load dataset
df = pd.read_csv("data/Phishing_Email.csv") # adjust the path as necessary
# Assume dataset has columns "text" and "label"
X = df["Email Text"].fillna("")
y = df["Email Type"]
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Create a pipeline with TF-IDF and Logistic Regression
pipeline = Pipeline(
[
("tfidf", TfidfVectorizer(stop_words="english")),
("clf", LogisticRegression(solver="liblinear")),
]
)
# Train the model
pipeline.fit(X_train, y_train)
# Save the trained model to a file
joblib.dump(pipeline, "phishing_model.pkl")
print("Model trained and saved as phishing_model.pkl")
if __name__ == "__main__":
main()
python train.py
Model trained and saved as phishing_model.pkl3. 模型评估
评估脚本可加载数据集和保存的模型文件以执行模型评估。
import pandas as pd
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import train_test_split
import joblib
def main():
# Load dataset
df = pd.read_csv("data/Phishing_Email.csv") # adjust the path as necessary
# Assume dataset has columns "text" and "label"
X = df["Email Text"].fillna("")
y = df["Email Type"]
# Split the dataset
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Load the trained model
model = joblib.load("phishing_model.pkl")
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model
print("Accuracy: ", accuracy_score(y_test, y_pred))
print("Classification Report:")
print(classification_report(y_test, y_pred))
if __name__ == "__main__":
main()结果近乎完美,F1分数也非常出色。
python validate.py
Accuracy: 0.9723860589812332
Classification Report:
precision recall f1-score support
Phishing Email 0.96 0.97 0.96 1457
Safe Email 0.98 0.97 0.98 2273
accuracy 0.97 3730
macro avg 0.97 0.97 0.97 3730
weighted avg 0.97 0.97 0.97 37304. 使用Redis提供模型服务
为了提供模型服务,我们将使用FastAPI创建REST API,并集成Redis以缓存预测。
import asyncio
import json
import joblib
from fastapi import FastAPI
from pydantic import BaseModel
import redis.asyncio as redis
# Create an asynchronous Redis client (make sure Redis is running on localhost:6379)
redis_client = redis.Redis(host="localhost", port=6379, db=0, decode_respnotallow=True)
# Load the trained model (synchronously)
model = joblib.load("phishing_model.pkl")
app = FastAPI()
# Define the request and response data models
class PredictionRequest(BaseModel):
text: str
class PredictionResponse(BaseModel):
prediction: str
probability: float
@app.post("/predict", response_model=PredictionResponse)
async def predict_email(data: PredictionRequest):
# Use the email text as a cache key
cache_key = f"prediction:{data.text}"
cached = await redis_client.get(cache_key)
if cached:
return json.loads(cached)
# Run model inference in a thread to avoid blocking the event loop
pred = await asyncio.to_thread(model.predict, [data.text])
prob = await asyncio.to_thread(lambda: model.predict_proba([data.text])[0].max())
result = {"prediction": str(pred[0]), "probability": float(prob)}
# Cache the result for 1 hour (3600 seconds)
await redis_client.setex(cache_key, 3600, json.dumps(result))
return result
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
python serve.py
INFO: Started server process [17640]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)你可以通过访问URL来查看REST API 文档。
本项目的源代码、配置文件、模型和数据集可以在kingabzpro/Redis-ml-project GitHub代码库中找到。如果你在运行上述代码时遇到任何问题,可随时参阅。
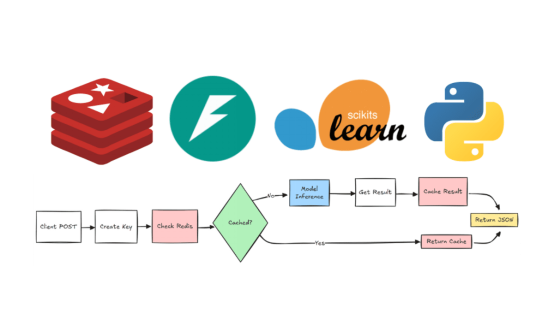
Redis缓存在机器学习应用中的工作原理
下面逐步解释Redis缓存在我们的机器学习应用程序中的运作方式,并附加一张流程图加以说明:

- 客户程序提交输入数据,请求机器学习模型进行预测。
- 系统根据输入数据生成独特的标识符,以检查预测是否已存在。
- 系统使用生成的键查询Redis缓存,以查找先前存储的预测。
A.如果找到缓存的预测,则检索该预测并以JSON响应的形式返回。
B.如果没有找到缓存的预测,则将输入数据传递给机器学习模型以生成新的预测。
- 新生成的预测存储在Redis缓存中供将来使用。
- 最终结果以JSON格式返回给客户程序。
测试网络钓鱼电子邮件分类应用程序
构建完网络钓鱼电子邮件分类应用程序后,就可以测试其功能了。我们在本节中将使用 `cURL` 命令发送多封电子邮件并分析响应来评估该应用程序。此外,我们将验证Redis数据库,以确保缓存系统正常运行。
使用CURL命令测试 API
为了测试API,我们将向`/predict`端点发送五个请求。其中三个请求包含独特的电子邮件文本,另外两个请求是之前发送的电子邮件的复制版本。这将使我们能够验证预测准确性和缓存机制。
echo "
===== Testing API Endpoint with 5 Requests =====
"
# First unique email
echo "
----- Request 1 (First unique email) -----"
curl -X 'POST'
'http://localhost:8000/predict'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"text": "todays floor meeting you may get a few pointed questions about today article about lays potential severance of $ 80 mm"
}'
# Second unique email
echo "
----- Request 2 (Second unique email) -----"
curl -X 'POST'
'http://localhost:8000/predict'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"text": "urgent action required: your account has been compromised, click here to reset your password immediately"
}'
# First duplicate (same as first email)
echo "
----- Request 3 (Duplicate of first email - should be cached) -----"
curl -X 'POST'
'http://localhost:8000/predict'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"text": "todays floor meeting you may get a few pointed questions about today article about lays potential severance of $ 80 mm"
}'
# Third unique email
echo "
----- Request 4 (Third unique email) -----"
curl -X 'POST'
'http://localhost:8000/predict'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"text": "congratulations you have won a free iphone, click here to claim your prize now before it expires"
}'
# Second duplicate (same as second email)
echo "
----- Request 5 (Duplicate of second email - should be cached) -----"
curl -X 'POST'
'http://localhost:8000/predict'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"text": "urgent action required: your account has been compromised, click here to reset your password immediately"
}'
echo "
===== Test Complete =====
"
echo "Now run 'python check_redis.py' to verify the Redis cache entries"运行上述脚本时,API应该返回每封电子邮件的预测结果。对于重复的请求,响应应该从Redis缓存中加以检索,以确保更快的响应时间。
sh test.sh
===== Testing API Endpoint with 5 Requests =====
----- Request 1 (First unique email) -----
{"prediction":"Safe Email","probability":0.7791625553383463}
----- Request 2 (Second unique email) -----
{"prediction":"Phishing Email","probability":0.8895319031315131}
----- Request 3 (Duplicate of first email - should be cached) -----
{"prediction":"Safe Email","probability":0.7791625553383463}
----- Request 4 (Third unique email) -----
{"prediction":"Phishing Email","probability":0.9169092144856761}
----- Request 5 (Duplicate of second email - should be cached) -----
{"prediction":"Phishing Email","probability":0.8895319031315131}
===== Test Complete =====
Now run 'python check_redis.py' to verify the Redis cache entries验证Redis缓存
为了确认缓存系统正常运行,我们将使用Python脚本`check_redis.py`来检查Redis数据库。该脚本检索缓存的预测结果,并将其以表格形式显示出来。
import redis
import json
from tabulate import tabulate
def main():
# Connect to Redis (ensure Redis is running on localhost:6379)
redis_client = redis.Redis(host="localhost", port=6379, db=0, decode_respnotallow=True)
# Retrieve all keys that start with "prediction:"
keys = redis_client.keys("prediction:*")
total_entries = len(keys)
print(f"Total number of cached prediction entries: {total_entries}
")
table_data = []
# Process only the first 5 entries
for key in keys[:5]:
# Remove the 'prediction:' prefix to get the original email text
email_text = key.replace("prediction:", "", 1)
# Retrieve the cached value
value = redis_client.get(key)
try:
data = json.loads(value)
except json.JSONDecodeError:
data = {}
prediction = data.get("prediction", "N/A")
# Display only the first 7 words of the email text
words = email_text.split()
truncated_text = " ".join(words[:7]) + ("..." if len(words) > 7 else "")
table_data.append([truncated_text, prediction])
# Print table using tabulate (only two columns now)
headers = ["Email Text (First 7 Words)", "Prediction"]
print(tabulate(table_data, headers=headers, tablefmt="pretty"))
if __name__ == "__main__":
main()当你运行check_redis.py脚本时,它会以表格形式显示缓存条目数量和已缓存的预测结果。
python check_redis.py
Total number of cached prediction entries: 3
+--------------------------------------------------+----------------+
| Email Text (First 7 Words) | Prediction |
+--------------------------------------------------+----------------+
| congratulations you have won a free iphone,... | Phishing Email |
| urgent action required: your account has been... | Phishing Email |
| todays floor meeting you may get a... | Safe Email |
+--------------------------------------------------+----------------+结语
通过使用多个请求测试钓鱼邮件分类应用程序,我们成功地演示了该API能够准确识别钓鱼邮件,同时还能使用Redis高效地缓存重复请求。这种缓存机制通过减少重复输入的冗余计算显著提升了性能,这在API处理庞大流量的实际应用场景中尤其大有助益。
虽然这是一个比较简单的机器学习模型,但在处理更庞大、更复杂的模型(比如图像识别)时,缓存的优势来得更为明显。比如说,如果你在部署一个大规模图像分类模型,缓存频繁处理输入的预测结果就可以节省大量计算资源,并显著缩短响应时间。
原文标题:Accelerate Machine Learning Model Serving with FastAPI and Redis Caching,作者:Abid Ali Awan









