


SQL窗口函数原理和使用
今天我们来聊聊 SQL 窗口函数。你是不是经常对复杂的报表查询感到比较头疼?在网上找到了一些窗口函数的 demo,但因为对实现原理一知半解,经常导致写的 SQL 查询的数据口径对不上。如果你有这样的问题,就静下心来好好学习一下这一讲的内容。我会给你详细地介绍 SQL 窗口函数的原理和使用方法,帮你找到解决问题的方案。
SQL 窗口函数介绍
首先,我们先对 SQL 窗口函数的使用场景、所处的执行阶段以及它的原理做一个简单的了解。
- SQL 窗口函数的使用场景:窗口函数只能在 select 查询列表中使用,不能用于 update 和 delete 语句。窗口函数不影响查询记录的数量,它的作用仅仅是在 select 列表里面新增一个列而已,且多个窗口函数之间互不影响。
- SQL 窗口函数所处的执行阶段:它只能出现在 select 列表中,晚于 from、where、group by、having 的执行。早于 order by、limit、select distinct 的执行。
- SQL 窗口函数的原理:窗口函数顾名思义,就是将 SQL 查询出来的结果看成一个大窗口。可以对整个窗口进行分区(partition by), 每个分区包含一个滑动窗口(frame)。
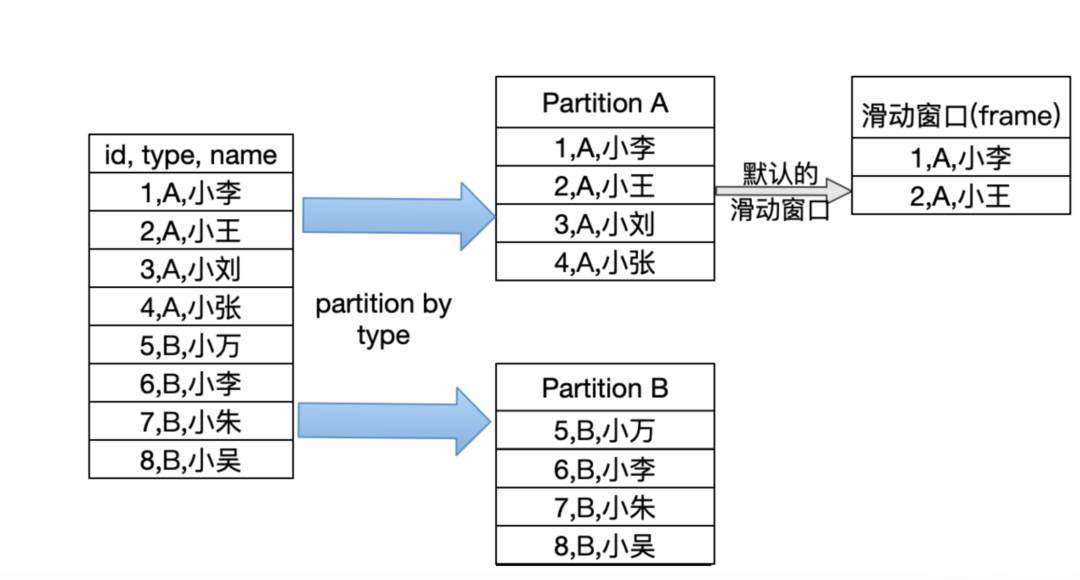
over() 函数
在我们的 SQL 中通过调用 over() 函数,我们可以生成一个窗口(基于 SQL 查询的全部结果)。over 函数内部支持如下参数:
- partition by <分区列名>;
- order by <列名 [asc|desc] ,用于指定分区内的数据的排列先后顺序>;
语法解释
- 当 over 函数内的参数为空时,整个结果集就是一个分区(不指定 partition by)。滑动窗口的大小也是整个结果集。
- 当 order by 不指定的时候,记录行(rows)使用默认的顺序,也就是从数据库查询出来的顺序。因为窗口函数在 order by 语句之前执行,所以顺序只能是默认的顺序。在此我强烈建议窗口函数都带上 order by 从句,否则结果列可能会是不确定的值。MySQL 可以支持不带 order by,但在 Oracle 和 SQL Server 上,指定滑动窗口时,必须带上 order by,否则就会报错。
- 当没有指定滑动窗口大小的参数时,即没有指定 range 或者 rows 从句,滑动窗口的默认大小为:上边界=分区的第一条记录,下边界=当前记录。
滑动窗口(Frame)语法讲解
滑动窗口是基于当前行的,它有一个上边界和一个下边界,滑动窗口不能脱离 partition 独立存在。当指定了 partition by 和 order by,而不指定滑动窗口时,滑动窗口默认的上边界为 partition 内第一条记录,下边界为当前记录。每一行记录都有一个滑动窗口。
指定滑动窗口的时候,必须是已经有了 partition by 从句,否则 SQL 会报错。虽然 MySQL8 支持,但是不建议你这样使用。当 over 函数里面没有 partition by 从句和滑动窗口从句时,默认的滑动窗口就是整个结果集。
滑动窗口大小支持两种模式,range 模式和 rows 模式。
- rows 模式
rows between N preceding and M following
滑动窗口的构成以当前逻辑行为基准点,向上指定 N 行 (逻辑行) 为上边界,向下指定 M 行 (逻辑行) 为下边界。
- range 模式(注意:range 模式必须指定 order by 从句)
range between N preceding and M following
滑动窗口的构成以当前逻辑行为基准点,值是 order by 从句中使用的列的值。
上边界:当前逻辑行之前 值 >= 当前逻辑行的值 - N 的所有逻辑行
下边界:当前逻辑行之后 值 <= 当前逻辑行的值 + M 的所有逻辑行
边界常量
- unbounded preceding:表示分区内第一条记录 (逻辑行),不管是否指定 order by 从句。
- unbounded following:表示分区内最后一条记录 (逻辑行),不管是否指定 order by 从句。
- current row:字面意思是当前行,在 rows 模式下,表示当前逻辑行。在 range 模式下,表示在当前逻辑行前后,值和当前逻辑行的值相等的所有逻辑行 (range 模式下指定了 order by,值都是有序的)。
- N preceding 和 N following:参考 range 和 rows 模式里面的解释,分别表示往前 N 行的数据和往后 N 行的数据。
操作函数
当 over 函数指定了窗口之后,需要操作函数对分区内(partition)或者滑动窗口内(Frame)的数据进行操作。
窗口函数分为 聚合函数和 非聚合函数。聚合函数处理数据大部分都是基于滑动窗口的。非聚合函数处理数据有基于滑动窗口的,也有基于分区的。下表是常用的操作函数,另外不同的数据库还会实现自身特有的操作函数。
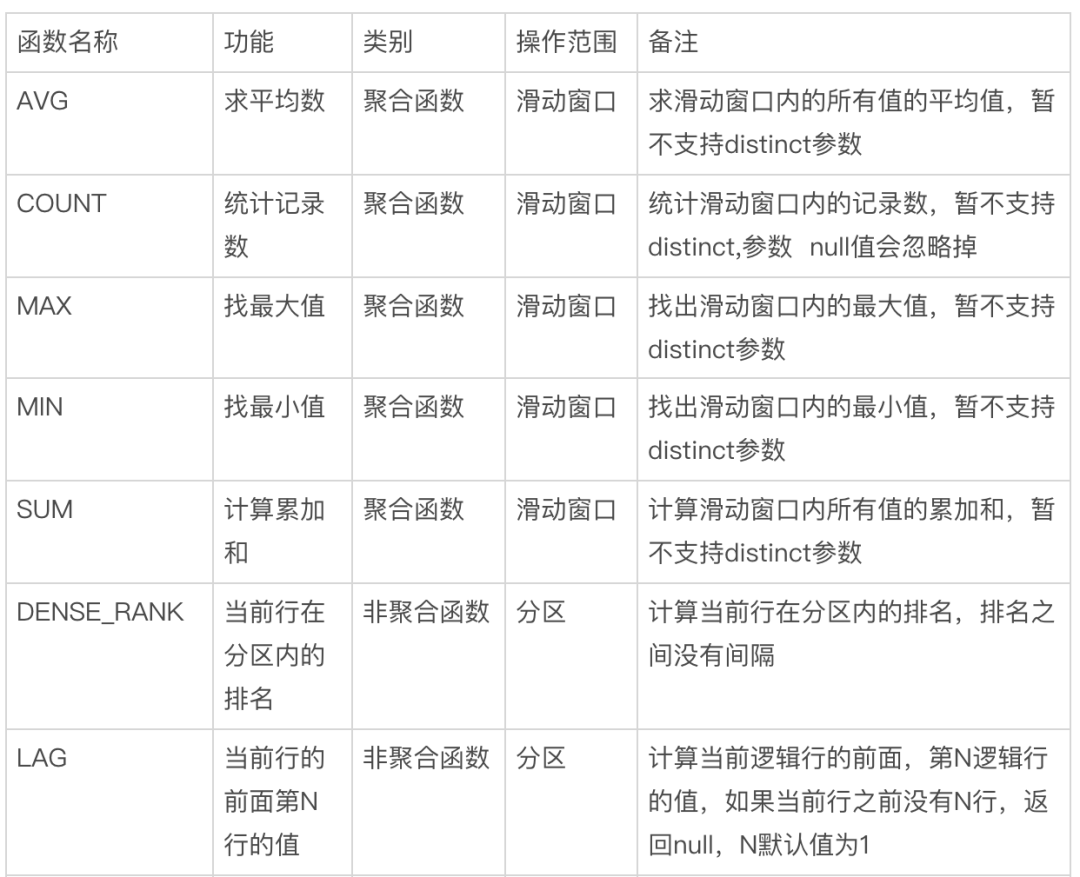
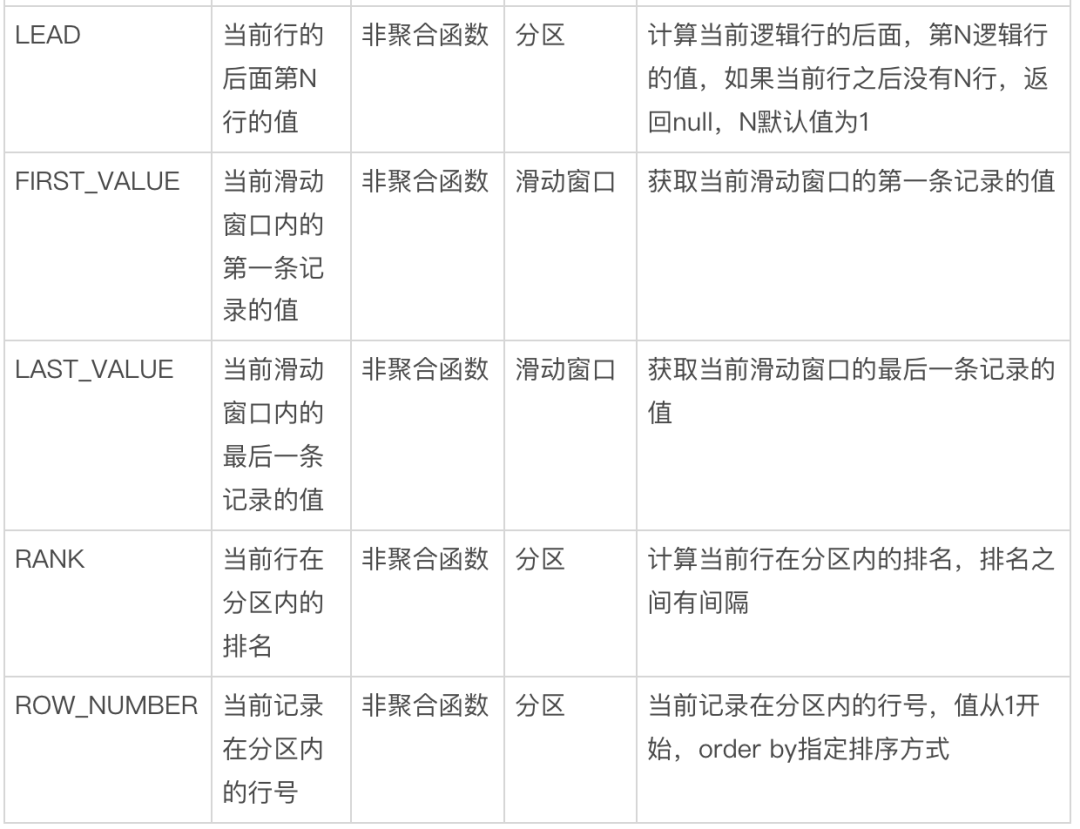
关于操作函数的详细描述和具体的使用方式,感兴趣的话你可以参考链接中的内容:
https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
示例
接下来我们通过示例表 names,来具体操作一下。这是示例的数据。

- row_number 函数
按照 name 列分区,为每一行记录生成行号,行号按照 val 列的值倒序生成。
select name,val,
row_number() over(partition by name order by val desc) num
from names- dense_rank 函数
按照 name 列分区,为每一行记录按照 val 列的值倒序生成排名。排名不能有间隔。
select name,val,
dense_rank() over(partition by name order by val desc) rnk
from names- rank 函数
按照 name 列分区,为每一行记录按照 val 列的值倒序生成排名。排名允许有间隔。
select name,val,
rank() over(partition by name order by val desc) rnk
from names- lag 函数
按照 name 列分区,为每一行记录生成 val 列和它前面一条记录的差值,前面的记录不存在用 0 表示。
select name,val,
val - lag(val,1,0) over(partition by name order by val desc) diff
from names其中 lag(val,1,0) 表示,获取当前行前面 1 行的 val 字段的值,如果前面一行不存在,用 0 表示默认值。
- first_value 函数
按照 name 列分区,为每一行记录生成 val 列和他所在滑动窗口内,第一条记录 val 列表的差值,按照 val 的值倒序排列。
select name,val,
val - first_value(val) over(partition by name order by val desc) diff
from names- 混合使用
select name,val,
row_number() over(partitionbynameorderby val desc) num,
val - first_value(val) over(partitionbynameorderby val desc) diff,
dense_rank() over(partitionbynameorderby val desc) rnk
fromnames因为每个窗口函数都是独立的,互不影响,可以在 select 列表里面使用多个窗口函数生成多列,各个列也互不影响。
总结
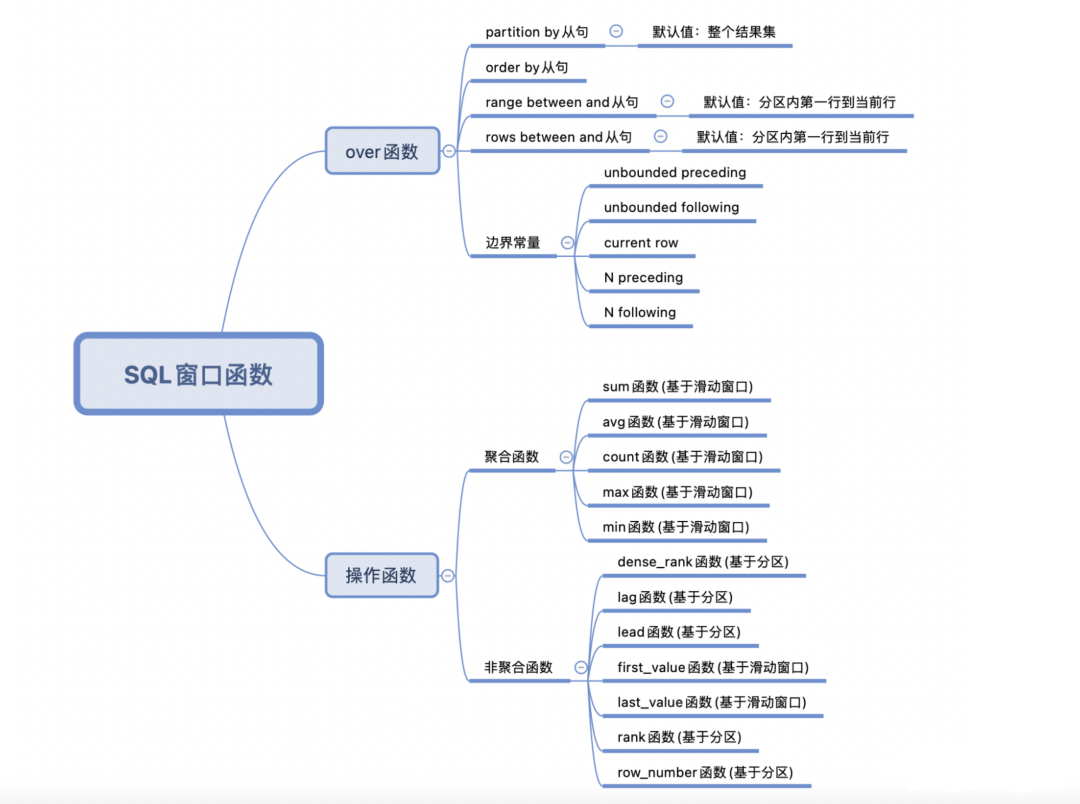
通过学习,相信你对 SQL 窗口函数已经有了一个整体和直观的认识,对其中的使用细节也有了一定的理解,特别是对分区、滑动窗口、range 和 rows 模式下滑动窗口的边界,以及操作函数的作用范围和使用方式有了一个清楚的认知。但想要牢固地掌握这些知识,还需要你学以致用,多多练习。









