


数据脱敏的六种方案,真香!
前言
某次新来的同事,在开发环境执行了这样的代码:
// 反例:直接将生产数据同步到测试环境
public void syncUserToTest(User user) {
testDB.insert(user); // 包含手机号、身份证等敏感字段
}直接将生产的数据,比如:手机号、身份证等敏感字段,同步到了测试环境。
结果1天后,受到了公司领导的批评。
这个案例揭示了数据脱敏的极端重要性。
这篇文章给大家分享6种常用的数据脱敏方案,希望对你会有所帮助。
方案1:字符串替换(青铜级)
技术原理:通过正则表达式对敏感数据进行部分字符替换
典型代码实现:
public class StringMasker {
// 手机号脱敏:13812345678 → 138****5678
public static String maskMobile(String mobile) {
return mobile.replaceAll("(d{3})d{4}(d{4})", "$1****$2");
}
// 身份证脱敏:110101199003077777 → 1101********7777
public static String maskIdCard(String idCard) {
if (idCard.length() == 18) {
return idCard.replaceAll("(d{4})d{10}(w{4})", "$1****$2");
}
return idCard; // 处理15位旧身份证
}
}使用正则表达式将关键字字段替换成了*
适用场景对比:
 图片
图片
优缺点分析:
- ✅ 优点:实现简单、性能高(时间复杂度O(n))
- ❌ 缺点:
- 无法恢复原始数据
- 正则表达式需考虑多国数据格式差异
- 存在模式被破解风险(如固定位置替换)
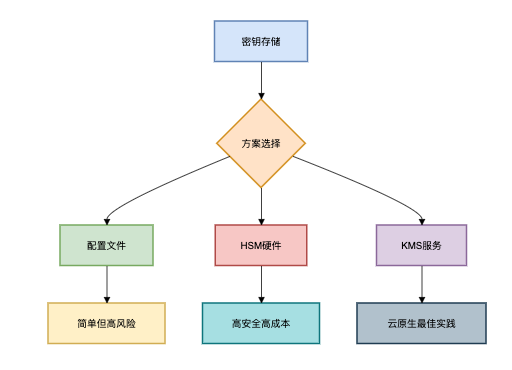
方案2:加密算法(白银级)
加密算法选型:
算法类型 | 代表算法 | 特点 | 适用场景 |
对称加密 | AES | 加解密快,密钥管理复杂 | 支付信息存储 |
非对称加密 | RSA | 速度慢,安全性高 | 密钥交换 |
国密算法 | SM4 | 符合国家标准 | 政府/金融系统 |
完整实现示例:
public class AESEncryptor {
privatestaticfinal String ALGORITHM = "AES/GCM/NoPadding";
privatestaticfinalint TAG_LENGTH = 128; // 认证标签长度
public static String encrypt(String plaintext, SecretKey key) {
byte[] iv = newbyte[12]; // GCM推荐12字节IV
SecureRandom random = new SecureRandom();
random.nextBytes(iv);
Cipher cipher = Cipher.getInstance(ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, key, new GCMParameterSpec(TAG_LENGTH, iv));
byte[] ciphertext = cipher.doFinal(plaintext.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(iv) + ":" +
Base64.getEncoder().encodeToString(ciphertext);
}
// 解密方法类似...
}密钥管理方案对比:
 图片
图片
方案3:数据遮蔽(黄金级)
数据库层实现数据遮蔽:
-- 创建脱敏视图
CREATE VIEW masked_customers AS
SELECT
id,
CONCAT(SUBSTR(name,1,1), '***') AS name,
CONCAT(SUBSTR(mobile,1,3), '****', SUBSTR(mobile,8,4)) AS mobile
FROM customers;
-- 使用列级权限控制
GRANT SELECT (id, name, mobile) ON masked_customers TO test_user;创建数据脱敏视图,在视图中将关键字段做遮蔽。
然后在后面需要用到这些字段的代码,需要统一从视图中查询数据。
代理层实现(ShardingSphere示例):
rules:
-!MASK
tables:
user:
columns:
phone:
maskAlgorithm:phone_mask
maskAlgorithms:
phone_mask:
type:MD5
props:
salt:abcdefg123456性能影响测试数据:
数据量 | 原始查询(ms) | 遮蔽查询(ms) | 性能损耗 |
10万 | 120 | 145 | 20.8% |
100万 | 980 | 1150 | 17.3% |
1000万 | 10500 | 12200 | 16.2% |
方案4:数据替换(铂金级)
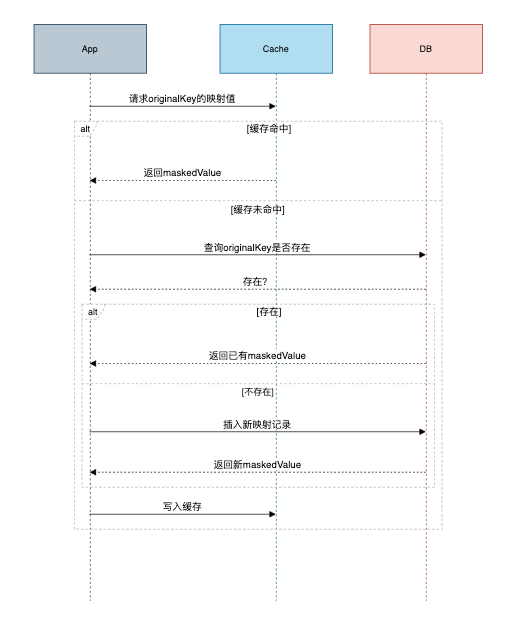
将原始数据和脱敏的数据保存到cache中,方便后面快速的做转换。
映射表设计:
// 使用Guava Cache实现LRU缓存
LoadingCache dataMapping = CacheBuilder.newBuilder()
.maximumSize(100000)
.expireAfterAccess(30, TimeUnit.MINUTES)
.build(new CacheLoader() {
public String load(String key) {
return UUID.randomUUID().toString().replace("-", "");
}
});
public String replaceData(String original) {
return dataMapping.get(original);
} 替换流程:
 图片
图片
方案5:动态脱敏(钻石级)
应用层实现(Spring AOP示例):
@Aspect
@Component
publicclass DataMaskAspect {
@Around("@annotation(requiresMasking)")
public Object maskData(ProceedingJoinPoint joinPoint, RequiresMasking requiresMasking) throws Throwable {
Object result = joinPoint.proceed();
return mask(result, requiresMasking.type());
}
private Object mask(Object data, MaskType type) {
if (data instanceof User) {
User user = (User) data;
switch(type) {
case MOBILE:
user.setMobile(MaskUtil.maskMobile(user.getMobile()));
break;
case ID_CARD:
user.setIdCard(MaskUtil.maskIdCard(user.getIdCard()));
break;
}
}
return data;
}
}在需要做数据脱敏的字段上技术RequiresMasking注解,然后在Spring的AOP拦截器中,通过工具类动态实现数据的脱敏。
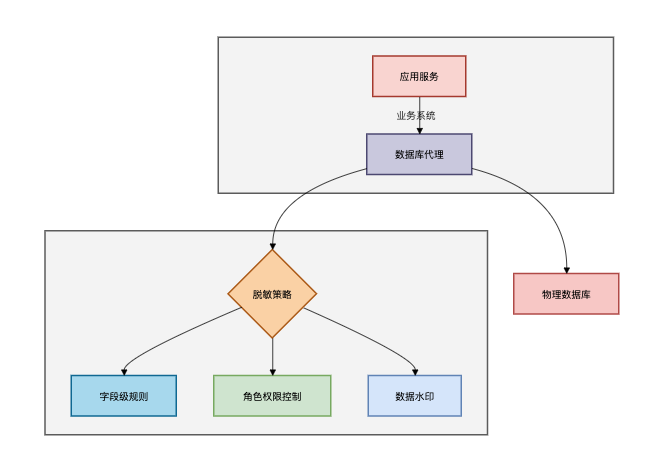
数据库代理层架构:
 图片
图片
方案6:K匿名化(王者级)
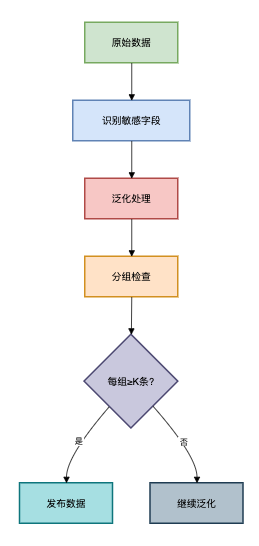
1. 通俗原理解释
假设医院发布就诊数据:
年龄 | 性别 | 疾病 |
25 | 男 | 感冒 |
25 | 男 | 发烧 |
25 | 男 | 骨折 |
当K=3时,攻击者无法确定具体某人的疾病,因为3人都具有相同特征(25岁男性)。
2. 实现步骤
 图片
图片
医疗数据泛化示例:
public class KAnonymity {
// 年龄泛化:精确值→范围
public static String generalizeAge(int age) {
int range = 10; // K=10
int lower = (age / range) * range;
int upper = lower + range - 1;
return lower + "-" + upper;
}
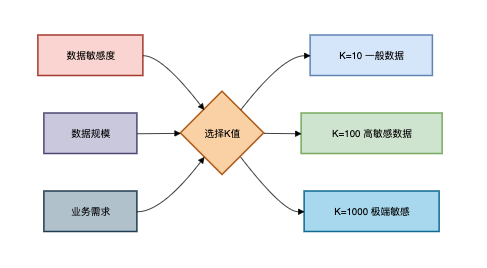
}假设range是K值,等于10。
generalizeAge方法中,通过一定的算法,将年龄的精确值,泛化成一个区间范围。
输入年龄28,返回20-29。
K值选择原则:
 图片
图片
总结
方案 | 安全性 | 性能 | 可逆性 | 适用场景 |
字符串替换 | ★★ | ★★★★ | 不可逆 | 日志/展示 |
加密算法 | ★★★★ | ★★ | 可逆 | 支付信息存储 |
数据遮蔽 | ★★★ | ★★★ | 部分可逆 | 数据库查询 |
数据替换 | ★★★★ | ★★ | 可逆 | 测试数据生成 |
动态脱敏 | ★★★★ | ★★★ | 动态可控 | 生产环境查询 |
K匿名化 | ★★★★★ | ★ | 不可逆 | 医疗/位置数据 |
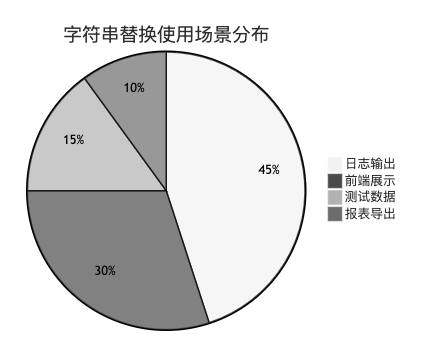
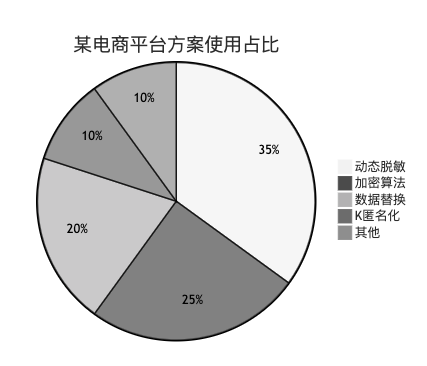
下面是某电商平台各方案的使用占比:
 图片
图片
苏三的3个核心建议:
- 数据分类分级:不同级别数据采用不同脱敏策略
- 定期审计:使用自动化工具扫描敏感数据泄露
- 最小化原则:能不收集的敏感数据坚决不收集
灵魂拷问:当黑客攻破你的数据库时,里面的数据是否像诺基亚功能机一样"防摔"?
安全大礼包
- 敏感数据扫描工具
- 脱敏策略检查表
- 数据安全架构白皮书









