


当AI邂逅向量数据库:重新定义智能时代的数据检索

译者 | 晶颜
审校 | 重楼
探究人工智能与向量数据库如何实现语义搜索,为更智能的推荐系统、聊天机器人及非结构化数据处理工具提供支撑。
在互联网时代,你是否期待搜索引擎不再局限于关键词匹配,而是能理解用户真实意图?这正是人工智能与向量数据库结合的价值所在。
传统数据库擅长处理电子表格等结构化数据,但面对社交动态、图片、语音笔记等非结构化数据时却力有不逮。人工智能擅长解析复杂数据,却需要高效的存储与检索系统,向量数据库应运而生——它以“语义”为核心,突破传统关键词匹配的局限。
本文将剖析这一组合如何革新信息发现与理解方式,通过一些实际案例、代码示例及技术流程解析其运行逻辑。
核心概念:向量数据库的本质
智能时代,人类与海量非结构化数据(文本、图像、音频、视频等)高频交互。传统数据库依赖关键词匹配或预定义结构(如SQL表),难以捕捉数据背后的语义关联。人工智能与向量数据库的融合,为解决这一难题提供了新路径。
关键问题
如何基于语义而非关键词检索数据?例如,系统能否理解“适合公寓饲养的犬种”与“体型小巧、喜静的犬类”为同义表述,即便二者用词不同?
解决方案
AI嵌入模型
深度学习模型(如大语言模型、Sentence-BERT文本模型、CLIP图文模型等)将复杂数据转化为高维空间中的“向量嵌入”。语义或特征相似的数据点在向量空间中位置相近,实现语义层面的量化表征。
向量数据库
专为存储、索引向量嵌入设计的数据库,采用近似最近邻搜索(ANN,如HNSW、IVF算法),可快速定位与查询向量最相似的数据点,实现毫秒级语义检索。
技术协同:AI与向量数据库的工作流程
那么,这个组合究竟是怎么运作的呢?具体流程如下:
- AI语义解析:AI模型对文本、图像等数据进行语义理解。
- 生成向量嵌入:根据语义理解结果,生成对应向量坐标,定位数据在语义空间中的位置。
- 向量数据库存储:存储向量坐标及数据ID,并构建高效索引以加速检索。
- 语义查询:用户输入文本或图像查询。
- 查询向量生成:同一AI模型将查询内容转化为向量坐标。
- 近邻搜索:向量数据库通过ANN算法,快速查找与查询向量最相似的向量点。
- 结果返回:根据向量相似度返回相关数据ID,实现基于语义的精准匹配。
技术优势:为何二者缺一不可?
- 语义理解:AI嵌入模型捕捉数据深层含义,超越表面词汇匹配。
- 检索效率:向量数据库支持数十亿级数据点的毫秒级近邻搜索,满足实时性需求。
- 数据适配:专为AI处理的复杂数据集设计,兼容多模态非结构化数据。
具体应用场景如下:
- 智能搜索:输入“适合跑步的舒适鞋”,系统可返回“适合慢跑的运动鞋”等语义相关结果,精准匹配用户意图。
- 个性化推荐:流媒体平台(如Netflix、Spotify)通过用户偏好向量与内容向量的相似度计算,实现精准内容推荐。
- 智能交互:聊天机器人基于语义匹配知识库内容,而非机械关键词响应,提升交互体验。
人工智能与向量数据库的深度融合,正推动数据检索从“关键词匹配”迈向“语义理解”,为智能时代的信息处理开启全新维度。
概念示例:基于语义的相似性检索
我们通过实例解析技术流程:假设已使用AI模型为大量句子生成向量坐标,并存储于Pinecone等向量数据库索引中。以下为查询相似句子的实现逻辑:
1 # (Assuming setup with 'pinecone-client' and an embedding 'model') Our question, or "query"
2 query_sentence = "AI is amazing in the world"
3
4 # 1. Ask the AI model for the coordinates of our query
5 query_embedding = model.encode([query_sentence])[0].tolist()
6
7 # 2. Ask the Vector DB (index) to find the 2 closest neighbors
8 results = index.query(vector=query_embedding, top_k=2, include_metadata=True)
9
10 # 3. Look at what it found!
11 print(f"We asked about: "{query_sentence}"
")
12 print("Here's what sounds similar:")
13
14 for match in results["matches"]:
15 original_text = match.get('metadata', {}).get('text', 'N/A') # Get the original text if stored
16
17 print(f" - Found: "{original_text}" (Similarity Score: {match['score']:.2f})") # Show score技术逻辑解析
- 向量转换:将查询语句(如“AI太神奇了……”)通过AI模型转换为高维空间中的向量坐标。
- 近邻搜索:向量数据库基于坐标距离(如余弦相似度)检索与查询向量最接近的存储数据,返回相似句子及相似度得分(如“人工智能的能力真的令人难以置信”,得分0.89)。
- 语义匹配:检索基于数据深层语义关联,而非字面匹配,实现“意义优先”的智能检索。
核心应用场景与价值
1. 智能搜索与推荐系统
- 图像语义检索:搜索“户外快乐狗狗的照片”,系统可识别未标注关键词的图片(如公园中玩耍的幼犬),基于视觉语义匹配结果。
- 个性化推荐:流媒体平台通过用户偏好向量与内容向量的相似度计算(如音乐风格、观影偏好),实现精准内容推荐。
2. 非结构化数据管理
- 媒体库语义检索:按视觉或听觉特征搜索照片/视频(如“海滩日落”),无需依赖文件名或人工标签。
- 金融安全监测:通过向量空间建模正常交易模式,实时识别偏离“语义地图”的异常行为(如潜在欺诈交易)。
3. 智能交互与问答
- 聊天机器人基于用户问题的向量嵌入,检索知识库中语义相关的答案,而非机械匹配关键词,提升交互效率与准确性。
基本旅程:输入数据,输出答案
以下是工作流程图:
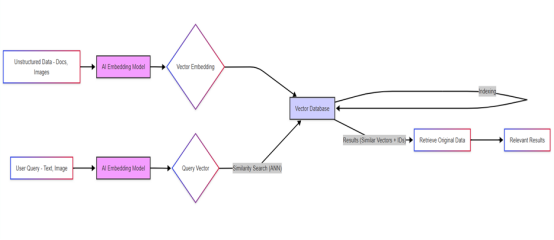
数据输入
原始数据(文本、图像、音频等)进入系统。
- AI语义建模:AI模型对数据进行语义分析,生成基于内容含义的向量嵌入(语义坐标)。
- 向量存储与索引:向量嵌入及原始数据引用指针被存储于向量数据库,并构建高效检索索引。
- 用户查询输入:用户通过文本输入或文件上传(如图像)发起查询请求。
- 查询向量生成:同一AI模型将用户查询转换为对应的向量嵌入(查询坐标)。
- 近邻检索执行:向量数据库通过近似最近邻算法,在向量空间中快速定位与查询坐标最接近的存储向量。
- 相似结果定位:数据库返回与查询向量相似度最高的原始数据引用标识。
- 原始数据提取:系统根据数据库返回的引用指针,调取对应的文本、图像或产品信息等原始数据。
- 结果输出:向用户交付语义相关的检索结果。
实战案例:电商智能推荐
当我们浏览在线商店时,点击“一双很酷的跑鞋”,并立即能看到其他类似鞋子的推荐,这通常就是AI+向量数据库在起作用!
- 预处理阶段:电商平台使用AI模型为商品(如红色跑鞋)生成向量坐标(基于描述、材质、图片特征等),存储于向量数据库。
- 实时推荐逻辑:
a.用户点击红色跑鞋;
b.系统获取其预先生成的向量坐标;
c.要求向量数据库:“快!给我找其他和这相近的鞋子!”
d.向量数据库毫秒级检索相似商品向量(如蓝色越野跑鞋、黑色运动袜),并返回对应商品ID;
e.前端展示相似鞋子的图片和价格。
f.最终,它们将出现在我们页面的“我们可能也喜欢”下面。
这种基于深度语义相似度提供关联建议的技术,看似浑然天成,实则通过智能算法精准捕捉数据内在关联,助力用户发现真正契合需求的产品。
结论
人工智能与向量数据库的融合堪称技术发展的重要里程碑。它突破了传统关键词搜索的局限,转向基于信息深层语义的检索逻辑,为智能搜索引擎、精准推荐系统及各类理解用户需求的应用提供了核心驱动力。
尽管当前技术仍在优化效率与成本(如提升检索速度、降低计算资源消耗),但其颠覆性价值已清晰显现——这一组合正重塑人类与信息交互的底层范式。无论是技术开发者构建应用场景,还是普通用户展望未来科技,理解AI与向量数据库的协同逻辑,都是在快速智能化的世界中把握发展脉络的关键。可以预见,这一技术组合将在更多领域持续释放创新潜力,成为智能时代的核心基础设施之一。
原文标题:AI Meets Vector Databases: Redefining Data Retrieval in the Age of Intelligence,作者:Anand Singh、Nilesh Charankar









