


从手工打标签到自动识别:LangChain4j如何革新文本分类?
引言
哈喽大家好,我是小米!
最近啊,办公室的几个同事围着我问:“你不是在搞 LangChain4j 吗?我们公司要做一个小型的智能问答系统,能不能用这个把客户的问题自动分类一下?”
我当时笑了笑,心里在想:你们问对人啦!
这篇文章,我就来跟大家聊聊我最近研究的一个小主题:LangChain4j 在文本向量化分类上的应用。别急,我保证讲得通俗易懂,代码示例安排上,连我妈(如果她想学编程)都能看懂!
故事从“搜索难题”开始
先说说我是怎么掉进 LangChain4j 这个“兔子洞”的。
那天是周四下午,我正窝在公司角落喝着平替星巴克,突然产品小姐姐跑过来:“小米,我们的客户支持后台太傻了,能不能加个功能,把客户提问自动分类,比如属于‘支付问题’、‘物流问题’、‘售后问题’的,都标好?”
我点了点头,说了三个字:“没问题!”(其实我心里慌得一批)
于是我开始查资料:分类问题,传统方法如朴素贝叶斯、SVM 已经用烂了,语义太弱。然后我突然想起,前段时间不是玩过 LangChain4j 吗?它不是支持 Embedding 和向量数据库吗?
灵感就这么来了:我们用 Embedding 把每条文本向量化,然后拿去匹配、分类不就行了?
LangChain4j 是个啥?
在深入前,咱们先快速介绍一下这个神器:LangChain4j。它是 Java 世界中专为接入 LLM(大语言模型)打造的一套框架。
简单说,它的作用有三个:
- 接入 OpenAI、Claude、百度文心一言等大模型。
- 支持 RAG(检索增强生成),和向量数据库联动。
- 提供链式调用,方便构建类似 ChatGPT 的复杂对话流程。
换句话说,它是 Java 开发者对接大模型的高速通道。
而文本向量化(embedding)功能,就是我们今天要用的核心工具之一!
文本分类的思路:Embedding + 向量匹配
我们来想一下文本分类怎么做。
传统做法:
- 定义分类标签,比如“支付”、“物流”、“售后”
- 把用户问题和标签一起丢给模型训练分类器
BUT!训练模型太重,太慢,太累,我们只想“轻量上云”!
于是我采用了新的思路,核心逻辑是这样的:
1. 每个分类(比如“支付问题”、“物流问题”)写一个“描述文本”
2. 用 LangChain4j 的 Embedding 工具把这些描述转为向量,存进向量数据库(比如 FAISS)
3. 客户提问来了,把问题文本也 Embedding 一下
4. 跟向量库里的分类向量比对,找最接近的
5. 得出分类,返回结果
是不是很聪明?而且零训练、零调参、部署简单!
实战开始!一步步实现分类系统
下面,我手把手教你怎么用 LangChain4j 实现一个文本分类系统!
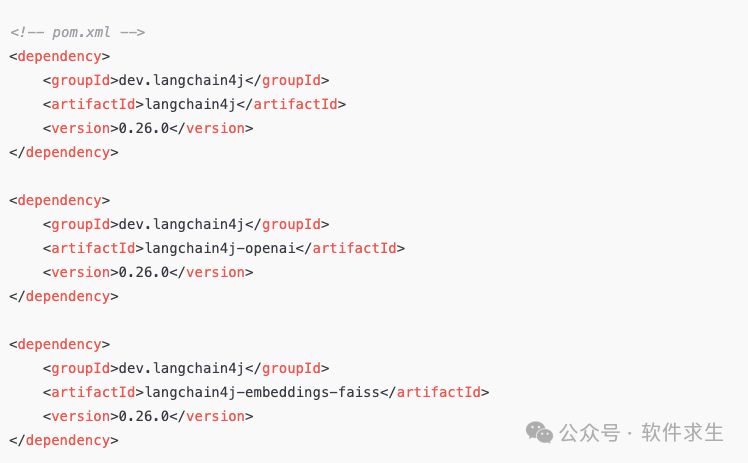
第一步:引入依赖
首先在你的 Java 项目中引入 LangChain4j 和 OpenAI 依赖:
 图片
图片
记得加上 OpenAI 的 API Key 配置哦。
第二步:构建你的分类向量库
 图片
图片
我们把分类定义为 label+说明,并通过 embeddingStore 向量化后存进去。
第三步:处理客户问题,分类定位

输入客户问题,通过 embedding 后和已有分类向量比相似度,返回最相近的 label!
第四步:我们测试一下
 图片
图片
是不是爽到飞起?
小米的改进建议
当然啦,一个系统做到这还远远不够,我还尝试了几个优化方向:
- 分类语料扩展:每个分类不仅只有一句话,可以扩展到多个“描述短句”,向量平均处理后效果更稳。
- 多分类返回:可以设置返回 Top-3 分类,显示相似度,做成一个“候选建议”系统。
- 落地结合数据库:我用 SQLite 存 Embedding + 分类标签,做到持久化。
- 结合 Chat Completion 做进一步 Q&A 跳转:分类完之后,跳转给 ChatGPT 去细化对话,闭环!
一行 Embedding,打开智能应用的潘多拉盒子
说实话,自从我把这个“文本向量化分类”的 Demo 做出来,产品那边简直爱死了:“哇,小米你这简直就是分类神器啊!”
而我想说的其实是:大模型+Embedding,让我们这种普通程序员,也能用极小的代价,搭建出过去需要专业算法团队才能完成的系统。
LangChain4j 是我见过最 Java 友好的 LLM 框架之一,如果你和我一样爱 Java,又不想被时代落下,真的建议你试试!









