


MySQL InnoDB 磁盘架构:如何管理和存储各数据?系统表、独立表、通用表、撤销表、临时表空间是什么?表和索引如何管理?
MySQL innoDB 引擎架构可以分为两大块,分别是内存架构(In-Memory Structure)和磁盘架构(On-Disk Structure)。
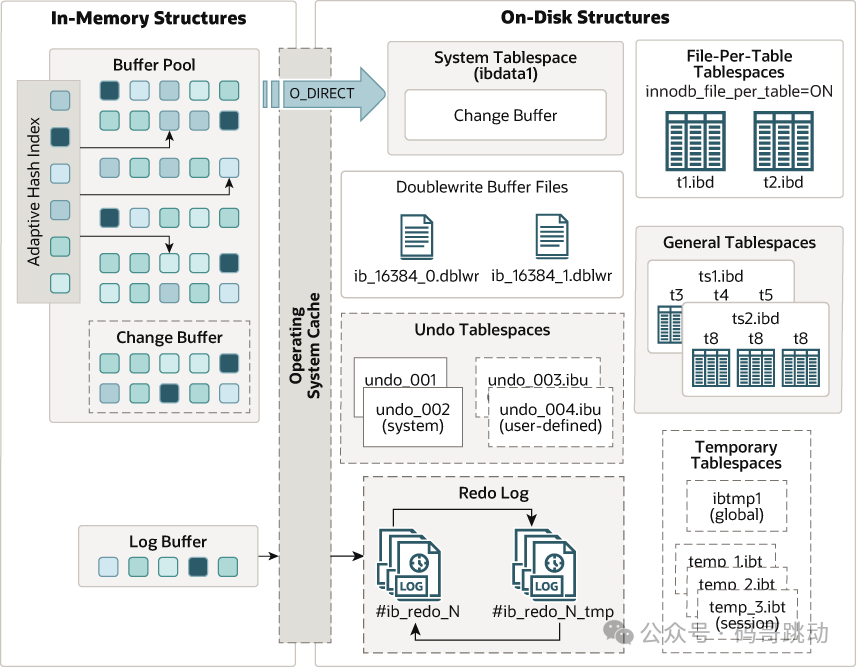 图 1
图 1
书接上回《MySQL InnoDB 架构 Buffer Pool、Change Buffer、自适应哈希索引、Log Buffer》,我们掌握了 InnoDB 引擎的内存架构。
数据最终要持久化到磁盘,其磁盘架构设计融合了复杂的存储结构和精巧的机制,本文将深入剖析其核心模块的设计原理,并通过图片辅助理解。
MySQL 到底是怎么管理和存储各种各样的数据呢?比如创建一张表、索引、表中的每一行数据、查询过程中临时存储的数据都存在哪里,又如何管理?
这一切都归功于 MySQL 的 Tablespaces (表空间)的设计,内容较多,本篇就关于以下类型 Tablespaces (表空间)作用和实现原理展开:
- 系统表空间(System Tablespace)
- 独立表空间(File-Per-Table Tablespaces)
- 通用表空间(General Tablespaces)
- 撤销表空间(Undo Tablespaces)
- 临时表空间(Temporary Tablespaces)
- Tables(表)
- Indexes(索引)
Tablespaces (表空间)
表空间可以看做是 InnoDB 存储引擎逻辑结构的最高层,所有的数据都存放在表空间中,称之为表空间(tablespace)。
从物理文件的分类来看:
- 日志文件(Undo Log、Redo Log)。
- 系统表空间(System Tablespace)文件 ibdata1。
- Undo tablespace 。
- 独立表空间(File-Per-Table Tablespaces)
- 通用表空间(General Tablespaces)
- 临时表空间文件(Temporary Tablespaces)
所以表空间根据不同的场景也分了多种类型,我分别介绍下……
系统表空间(System Tablespace)
默认配置下会有一个初始大小为 10MB,名为 ibdata1 的文件。该文件就是默认的表空间文件(tablespace file)。
系统表空间是 Change Buffer 的存储区域。
如果表是在系统表空间而非独立表空间或通用表空间中创建的,它也可能包含表和索引数据。
增加系统表空间大小的最简单方法是将其配置为自动扩展。
为此,在 innodb_data_file_path 设置中为最后一个数据文件指定 autoextend 属性,并重启服务器。
innodb_data_file_path=ibdata1:10M:autoextend为避免系统表空间过大,可考虑使用独立表空间或通用表空间存储数据。
独立表空间是默认的表空间类型,在创建 InnoDB 表时会隐式使用。
独立表空间(File-Per-Table Tablespaces)
独立表空间,顾名思义,就是用户创建的表空间,如果开启独立表空间参数,那么一个表空间会对应磁盘上的一个物理文件,每张表对应一个文件,支持事务独立管理。
其实表空间文件内部还是组织为更复杂的逻辑结构,自顶向下可分为 segment(段)、extent(区)和 page(页)。
page 则是表空间数据存储的基本单位,innodb 将表文件(xxx.ibd)按 page 切分,依类型不同,page 内容也有所区别,最为常见的是存储数据库表的行记录。
表空间下一级称为 segment。segment 与数据库中的索引相映射。
Innodb 引擎内,每个索引对应两个 segment:管理叶子节点的 segment 和管理非叶子节点 segment。
创建索引中很关键的步骤便是分配 segment,Innodb 内部使用 INODE 来描述 segment。
segment 的下一级是 extent,extent 代表一组连续的 page,默认为 64 个 page,大小 1MB。
InnoDB 存储引擎的逻辑存储结构大致如图 2 所示。
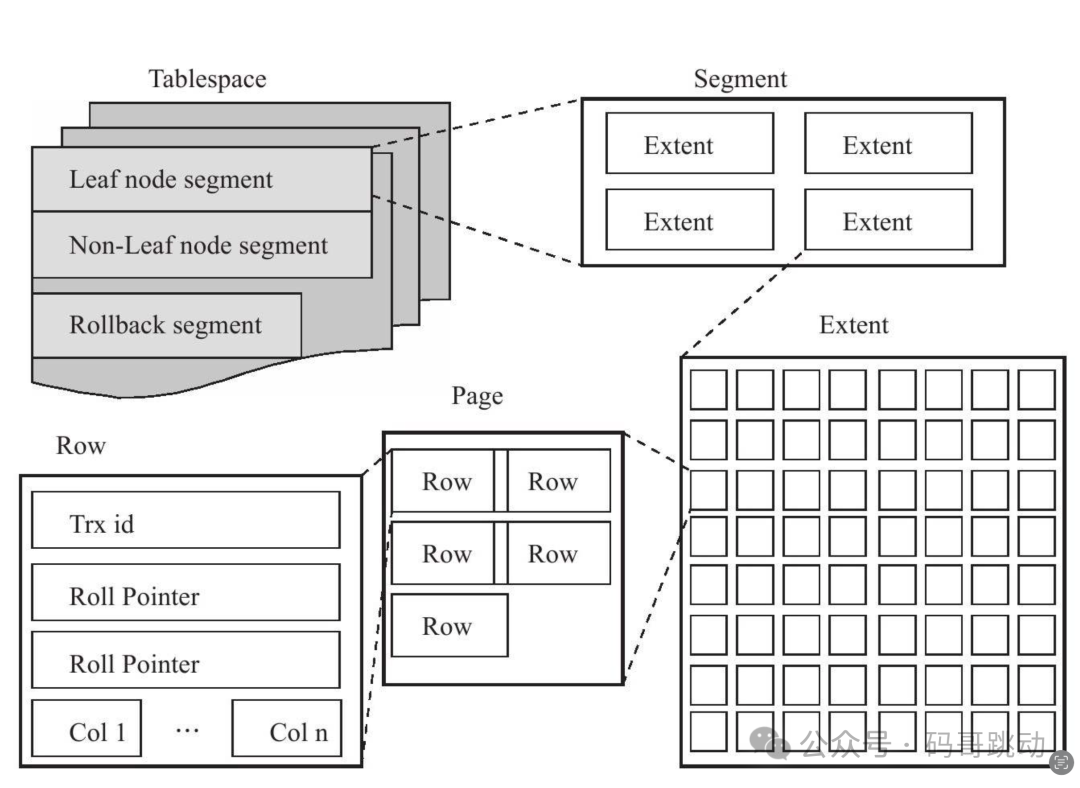 图 2
图 2
图 2
默认情况下 InnoDB 存储引擎有一个共享表空间 ibdata1,即所有数据都存放在这个表空间内。
如果用户启用了参数innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内。
如果启用了innodb_file_per_table的参数,需要注意的是每张表的表空间内存放的只是数据、索引和插入缓冲 Bitmap 页.
其他类的数据,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等还是存放在原来的系统表空间内。
通用表空间(General Tablespaces)
通用表空间是一种共享的 InnoDB 表空间,通过 CREATE TABLESPACE 语法创建。
通用表空间提供以下功能:
- 类似于系统表空间,通用表空间是一种共享表空间,能够存储多张表的数据。
- 通用表空间在内存占用上可能优于独立表空间。服务器会在表空间生命周期内将表空间元数据保留在内存中。相较于相同数量的表分散在多个独立表空间中,更少的通用表空间内存储多张表能减少表空间元数据的内存消耗。
通用表空间通过 CREATE TABLESPACE 语法创建。
CREATE TABLESPACE tablespace_name
[ADD DATAFILE 'file_name']
[FILE_BLOCK_SIZE = value]
[ENGINE [=] engine_name]通用表空间有什么不足?
通用表空间限制有以下限制:
- 现有的表空间无法更改为通用表空间。
- 不支持创建临时通用表空间。
- 通用表空间不支持临时表。
- 不支持将表分区放置在通用表空间中。
- 在复制环境中,如果源和副本位于同一主机上,则不支持使用
ADD DATAFILE子句,因为这会导致源和副本在同一位置创建同名的表空间,而这是不被支持的。
撤销表空间(Undo Tablespaces)
MySQL InnoDB 引擎的 Undo Tablespaces(撤销表空间)是磁盘架构设计中用于管理事务回滚日志(Undo Log)的核心组件。
唐二婷:InnoDB 引擎的 Undo Tablespaces(撤销表空间)有啥用?
Undo 日志(Undo Log)主要用于事务异常时的数据回滚,在磁盘上 undo 日志保存在 Undo Tablespaces 中。
- 事务回滚与 MVCC 支持Undo 表空间存储的 Undo Log 记录了事务对数据的修改前镜像,用于:
事务回滚时恢复数据原状;
实现多版本并发控制(MVCC),支持非锁定一致性读。
- 分离系统表空间负载在 MySQL 5.7 之前,Undo Log 默认存储在系统表空间(
ibdata1)中。
随着事务频繁操作,ibdata1文件会无限增长且无法自动回收空间。
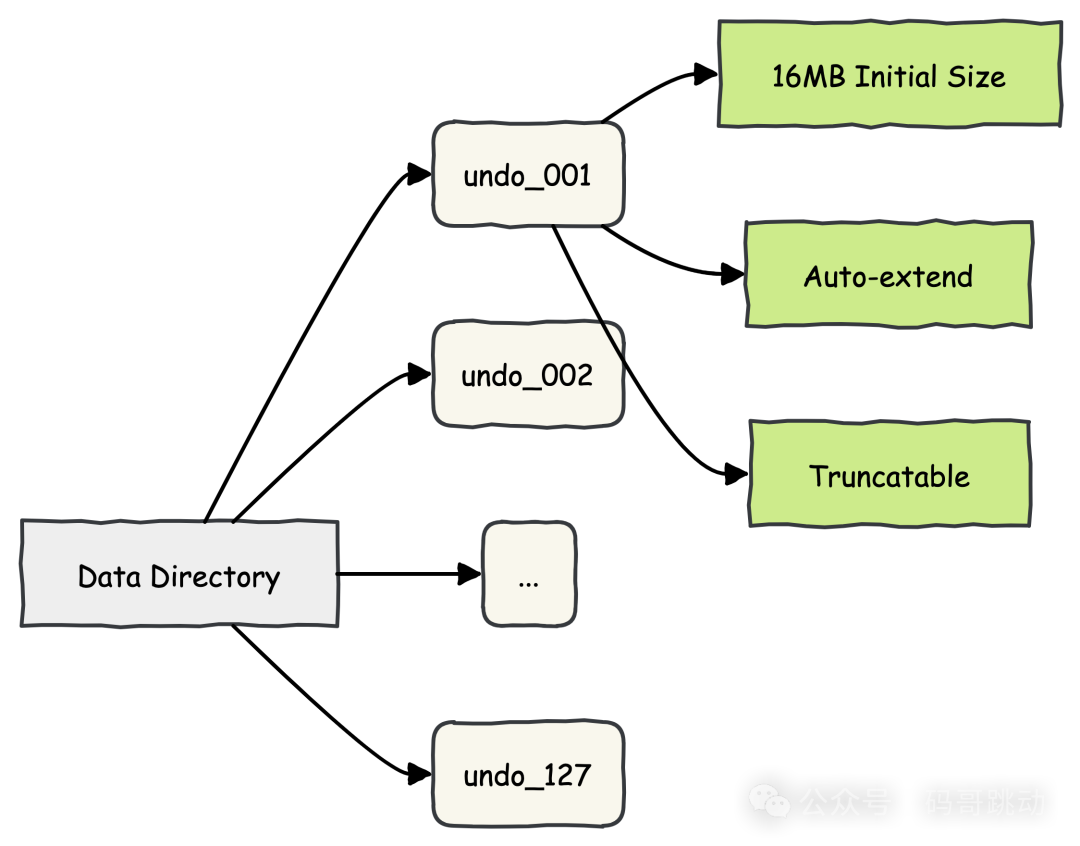
5.7 及更高版本引入独立 Undo 表空间,通过物理隔离减轻系统表空间压力,提升性能。
MySQL 8.0 默认创建 2 个 Undo 表空间文件(undo_001 和 undo_002),每个初始大小为 16MB,通过参数 innodb_undo_tablespaces 可调整数量(范围 2-127),每个文件初始 16MB,支持自动扩展和截断回收。
 图片
图片
唐二婷:“Undo 表空间的逻辑层级管理是咋样的?”
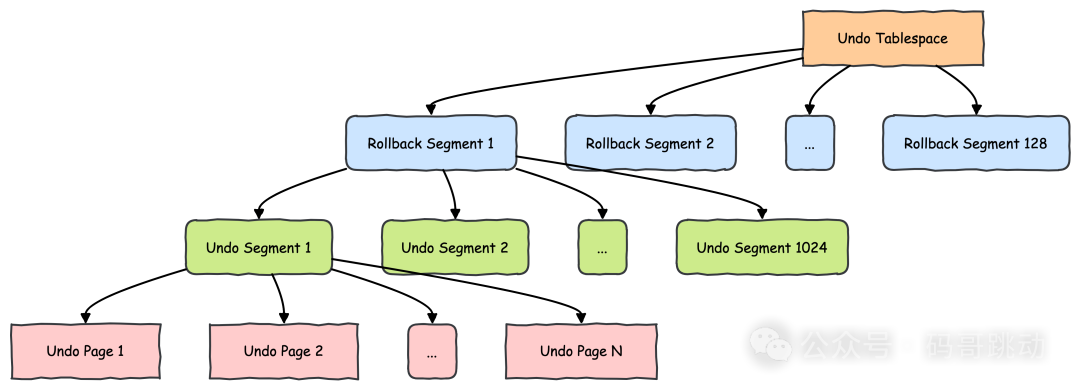
回滚段(Rollback Segments):每个 Undo 表空间包含 128 个回滚段(由 innodb_rollback_segments 控制),每个回滚段管理 1024 个 Undo 段(Undo Segments)。
Undo 页与日志记录:Undo 段由多个 16KB 的页组成,按事务类型分为 Insert Undo 段(仅用于回滚)和 Update Undo 段(用于 MVCC),前者事务提交后立即释放,后者需等待无活跃读视图时清除。
通过多 Undo 表空间与回滚段的分区设计,理论上支持高达数万级并发事务(例如:128 表空间 × 128 回滚段 × 1024 Undo 段)。
如下图所示。
 图片
图片
关键说明:
- 每个 Undo 表空间包含 128 个回滚段
- 每个回滚段管理 1024 个 Undo 段(按事务类型分类)
- Undo 段由 16KB 页 组成,存储具体日志记录
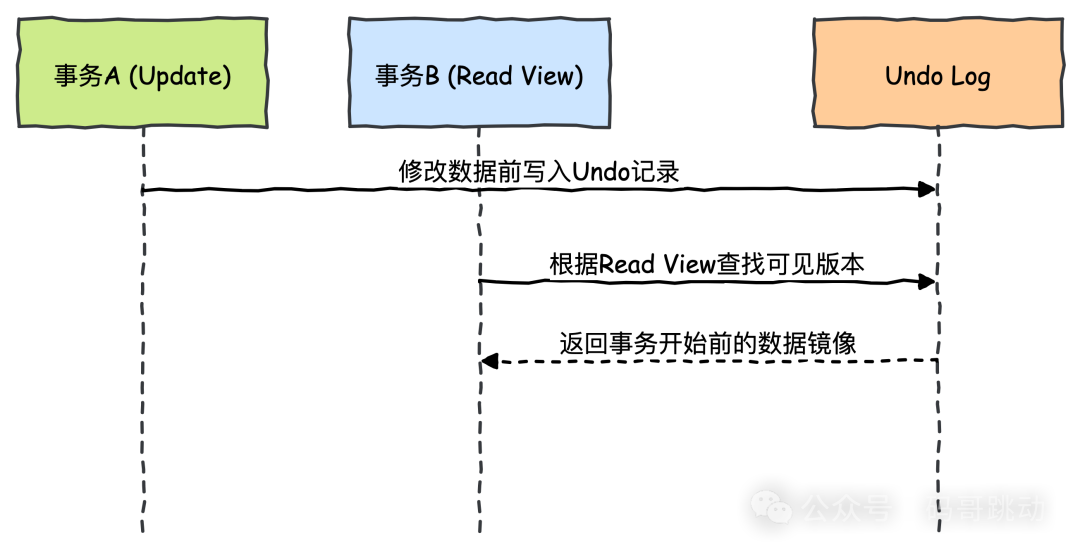
唐二婷:说说 Undo Log 与 MVCC 的协作机制
Undo Log 与 MVCC 的协作机制如下图所示:
 图片
图片
运作原理:
- 事务修改前将旧数据写入 Undo Log
- 读事务通过 Read View 判断可见性
- 多版本数据通过 Undo Log 链回溯访问
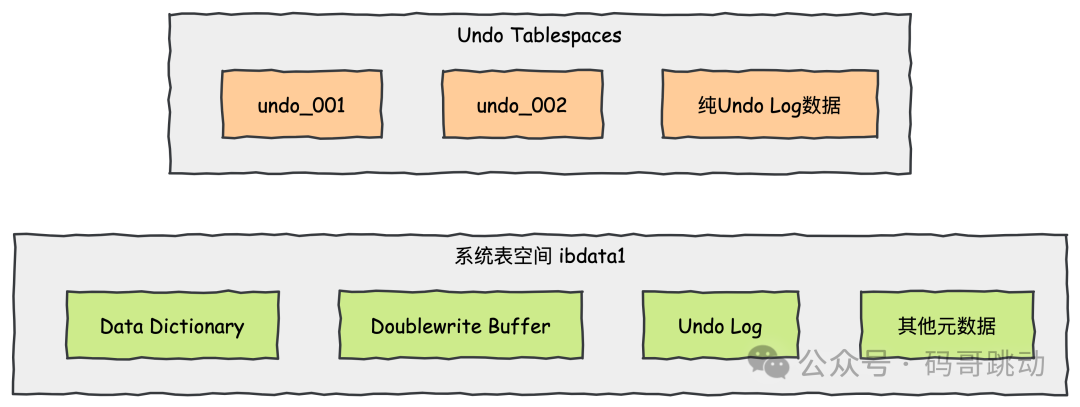
唐二婷:“系统表空间与 Undo 表空间存储有啥区别?”
 图片
图片
特性 | Undo 表空间 | 系统表空间(历史方案) |
存储内容 | 仅 Undo Log | 数据字典、双写缓冲、Undo Log 等混合内容 |
空间管理 | 支持自动截断,避免文件膨胀 | 无法自动回收,需手动调整或重建 |
性能影响 | 减少 I/O 竞争,提升并发处理能力 | 高频事务易导致文件过大,性能下降 |
版本支持 | MySQL 5.7+ 默认方案 | MySQL 5.6 及更早版本 |
临时表空间(Temporary Tablespaces)
InnoDB 临时表空间分为 会话临时表空间 和 全局临时表空间,分别承担不同角色:
- 会话临时表空间(Session Temporary Tablespaces)
用途:存储用户显式创建的临时表(CREATE TEMPORARY TABLE)以及优化器生成的内部临时表(如排序、分组操作)。
生命周期:会话断开时自动截断并释放回池,文件扩展名为 .ibt,默认位于 #innodb_temp 目录。
分配机制:首次需要创建磁盘临时表时,从预分配的池中分配(默认池包含 10 个表空间文件),每个会话最多分配 2 个表空间(用户临时表与优化器内部临时表各一)。
- 全局临时表空间(Global Temporary Tablespace):
用途:存储用户临时表的回滚段(Rollback Segments),支持事务回滚操作。
文件配置:默认文件名为
ibtmp1,初始大小 12MB,支持自动扩展,由参数innodb_temp_data_file_path控制路径与属性。回收机制:服务器重启时自动删除并重建,意外崩溃时需手动清理。
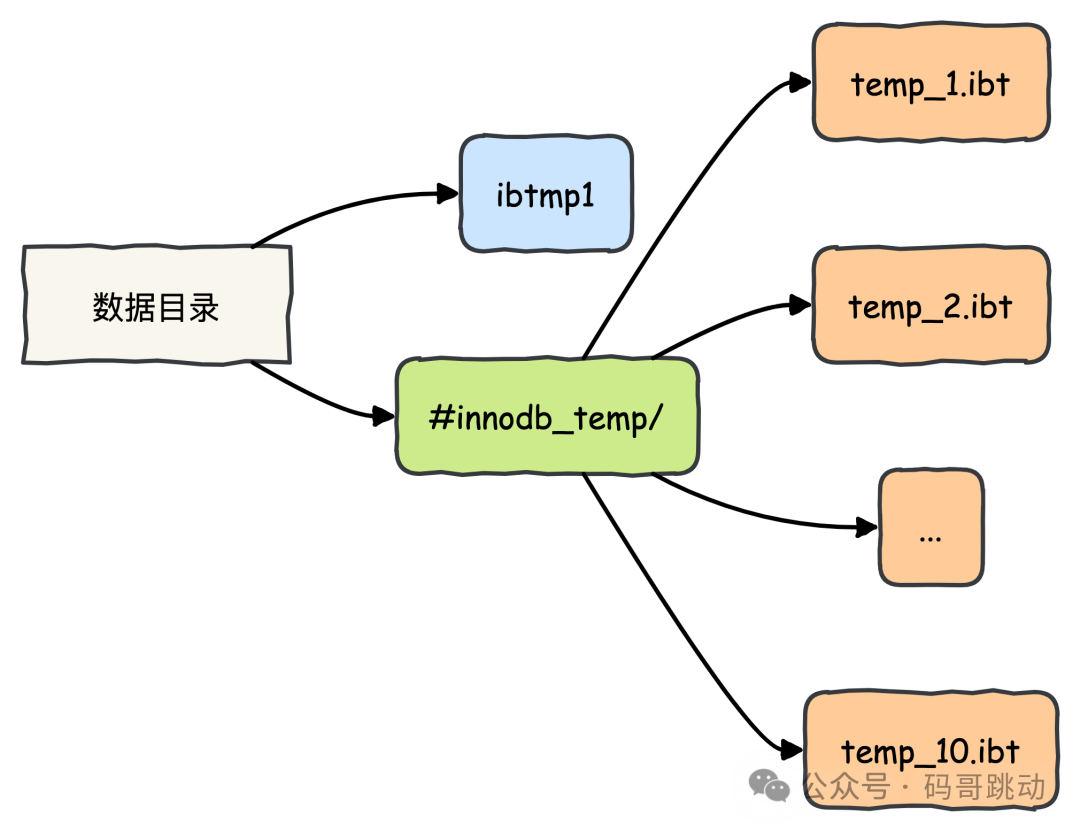
Temporary Tablespaces 物理结构
 图片
图片
图示说明:
- 全局临时表空间:
ibtmp1存储用户临时表的回滚段 - 会话临时表空间:
#innodb_temp目录下预分配 10 个.ibt文件池(默认配置) - 每个会话最多激活 2 个临时表空间(用户临时表 + 优化器内部临时表)。
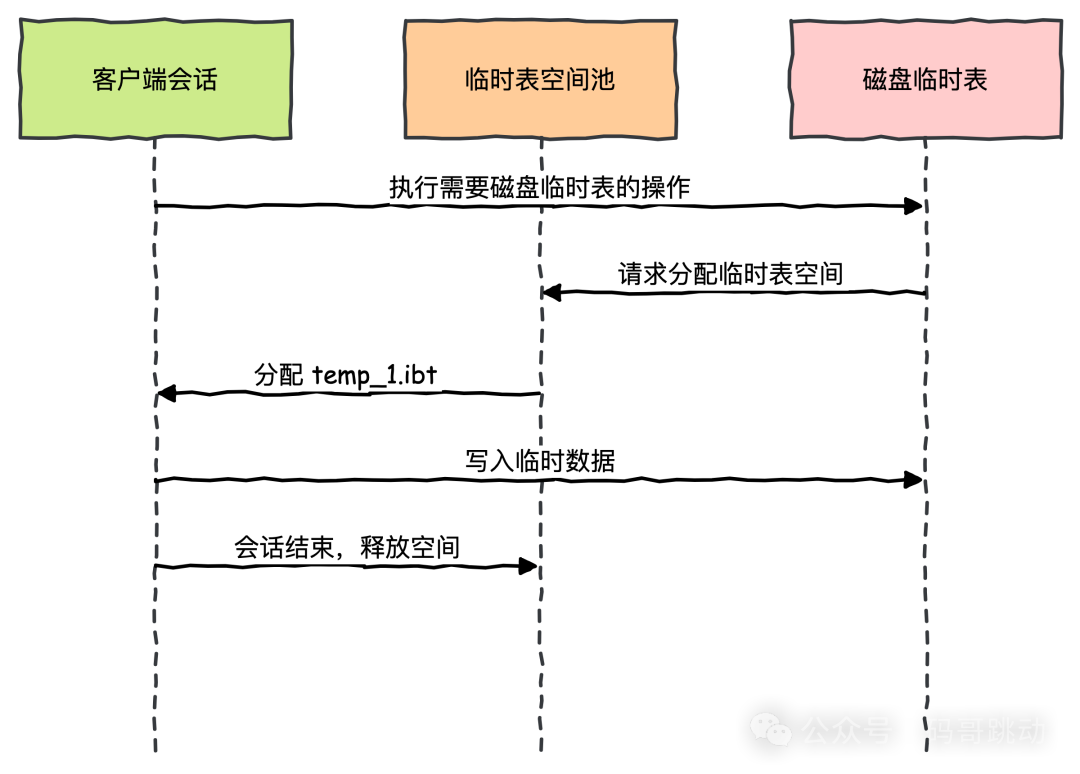
会话级临时表空间生命周期
 图片
图片
关键点:
- 首次需要磁盘临时表时从池中分配
- 会话断开连接后立即归还空间
- 文件物理保留但内容截断(类似内存池机制)
临时表空间使用查询流程
前面说过临时表空间可存储用户显式创建的临时表(CREATE TEMPORARY TABLE)以及优化器生成的内部临时表(如排序、分组操作)。
那它的查询过程是怎样的呢?
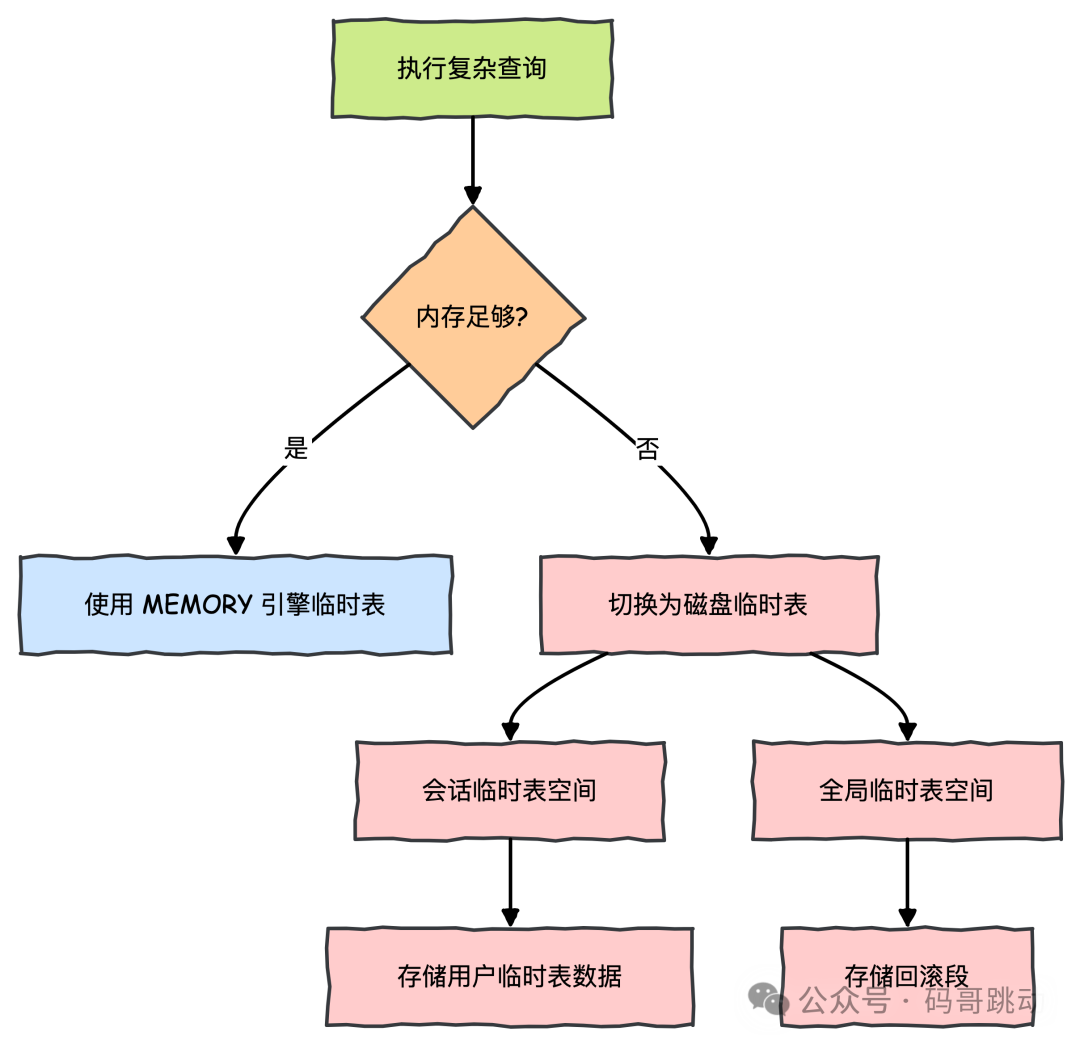 图片
图片
Tables(表)
唐二婷:“在 MySQL 如何创建一张表?”
InnoDB 表通过 CREATE TABLE 语句创建;例如:
CREATE TABLE t1 (a INT, b CHAR (20), PRIMARY KEY (a)) ENGINE=InnoDB;默认情况下, InnoDB 表创建于每表独立的表空间中。若要在 InnoDB 系统表空间中创建 InnoDB 表,需在创建表前禁用 innodb_file_per_table 变量。
比如,在数据库 test 中创建一个表 show_index ,在 mysql 的 dataDirectory 目录下就回出现一个名为 show_index.ibd 的数据文件。
在单个表的数据文件中,数据就是以多个页的形式进行排列。MySQL 默认配置下,每 16K,即为一个页。
InnoDB 表以 B+树 组织数据,每个表对应一个 聚簇索引(Clustered Index),数据行的物理存储顺序与主键顺序一致。
若未显式定义主键,InnoDB 会隐式生成一个 6 字节的 Row ID 作为主键。
Row Formats 行格式
唐二婷:表中的每一行数据是怎么存储的?
表的 InnoDB 行格式决定了其行在磁盘上的物理存储方式。
InnoDB 支持四种行格式,每种格式具有不同的存储特性。
支持的行格式包括 REDUNDANT 、 COMPACT 、 DYNAMIC 和 COMPRESSED 。其中, DYNAMIC 行格式为默认格式。
唐二婷:它们有啥区别?
REDUNDANT 和 COMPACT 行格式支持的最大索引键前缀长度为 767 字节,而 DYNAMIC 和 COMPRESSED 行格式则支持 3072 字节的索引键前缀长度。
在复制环境中,若源服务器上的 innodb_default_row_format 变量设置为 DYNAMIC ,而副本上设置为 COMPACT ,则以下未明确指定行格式的 DDL 语句在源服务器上执行成功,但在副本上会失败。
Primary Keys 主键
建议为创建的每个表定义一个主键。在选择主键列时,应选择具有以下特征的列:
- 重要的查询语句使用的列。
- 列不能为空。
- 从不包含重复值的列。
- 一旦插入后极少甚至从不更改值的列。
例如,在包含人员信息的表中,你不会将主键设在 (firstname, lastname) 上,因为可能有多个人员拥有相同的姓名,姓名列可能留空,且有时人们会更改姓名。
面对如此多的限制条件,通常没有明显的一组列适合作为主键,因此你会创建一个带有数字 ID 的新列,作为主键。
最好的方式就是使用趋势递增的数字作为主键。
你也可以 在 InnoDB 表中使用 AUTO_INCREMENT 的列来定义主键自动生成。
AUTO_INCREMENT 实现原理是什么?会锁全表码?
自增锁模式通过 innodb_autoinc_lock_mode 变量在启动时配置。
自增主键锁
“传统”锁模式
innodb_autoinc_lock_mode = 0 (“传统”锁模式),所有“INSERT 类”语句在向具有 AUTO_INCREMENT 列的表中插入时都会获得一个特殊的表级 AUTO-INC 锁。
此锁通常保持到语句的末尾(而不是事务的末尾),以确保在给定的 INSERT 语句序列中自动增量值按可预测和可重复的顺序分配,并确保任何给定语句分配的自动增量值是连续的。
“连续”锁模式
innodb_autoinc_lock_mode = 1 (“连续”锁模式),“批量插入”使用特殊的 AUTO-INC 表级锁,并保持到语句结束。这适用于所有 INSERT ... SELECT 、 REPLACE ... SELECT 和 LOAD DATA 语句。
这种锁模式确保,在存在 INSERT 语句且行数未知(并且自增值在语句执行过程中分配)的情况下,任何“ INSERT -类似”语句分配的所有自增值都是连续的,并且操作对基于语句的复制是安全的。
innodb_autoinc_lock_mode = 2 (“交错”锁模式)
在这种锁模式中,没有“ INSERT -like”语句使用表级 AUTO-INC 锁,并且多个语句可以同时执行。
这是最快且最可扩展的锁模式,但在使用基于语句的复制或从二进制日志重放 SQL 语句的恢复场景时是不安全的。
在此锁定模式下,自动增量值在整个并发执行的“ INSERT -like”语句中保证是唯一的且单调递增。
然而,由于多个语句可以同时生成数字(即,数字的分配在语句之间交错进行),任何给定语句插入的行生成的值可能不是连续的。
Indexes(索引)
InnoDB 的索引分为 聚簇索引 和 二级索引(Secondary Index),均采用 B+树结构:
- 聚簇索引:也称 Clustered Index。是指关系表记录的物理顺序与索引的逻辑顺序相同。由于一张表只能按照一种物理顺序存放,一张表最多也只能存在一个聚集索引。叶子节点直接存储行数据。
- 二级索引:也叫 Secondary Index。指的是非叶子节点按照索引的键值顺序存放,叶子节点存放索引键值以及对应的主键键值。MySQL 里除了 INNODB 表主键外,其他的都是二级索引。叶子节点存储主键值,需通过主键回表查询数据。
下图是一个聚集索引的 B+ Tree 图。
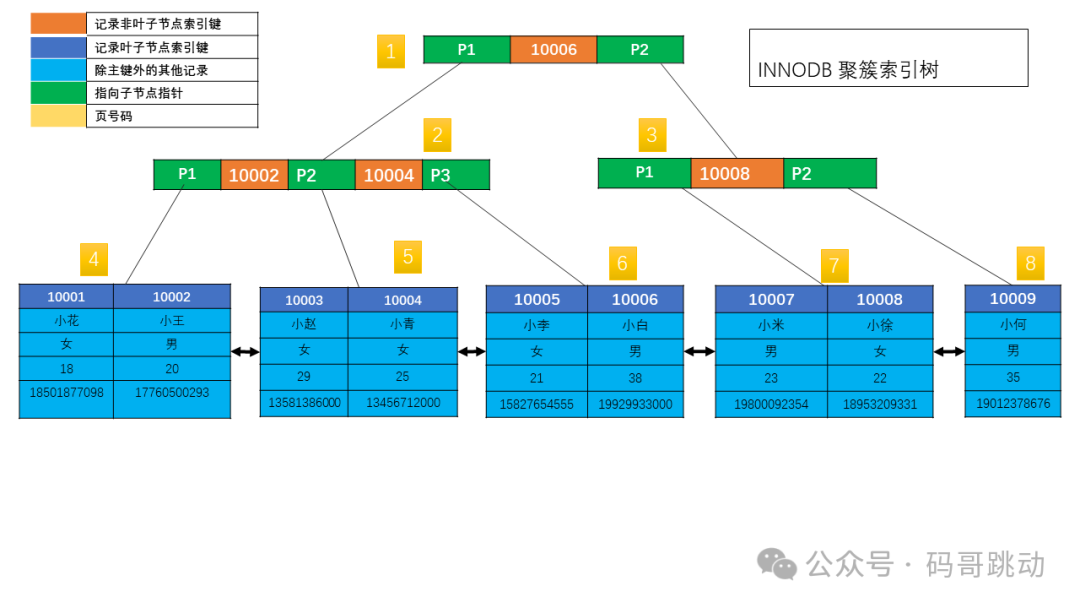 图片
图片
1 个 B+ Tree Node,占据一个页。
- 在索引页,页的主要记录部分(
User Records)存放的Record=record header+index key+page pointer。 - 在数据页,则是按表创建时的
row_format类型存放完整数据行记录。 row_format 类型分别有:Compact、Redundant、Compressed和Dynamic。
因此,在聚集索引中,非叶子节点都为索引页,叶子节点为数据页;
在辅助索引中,非叶子节点和叶子节点都为索引页。不同的是,叶子节点里记录的是聚集索引中的主键 ID 值。
INNODB 表的二级索引,如下图所示,图片来自「一树一溪」:
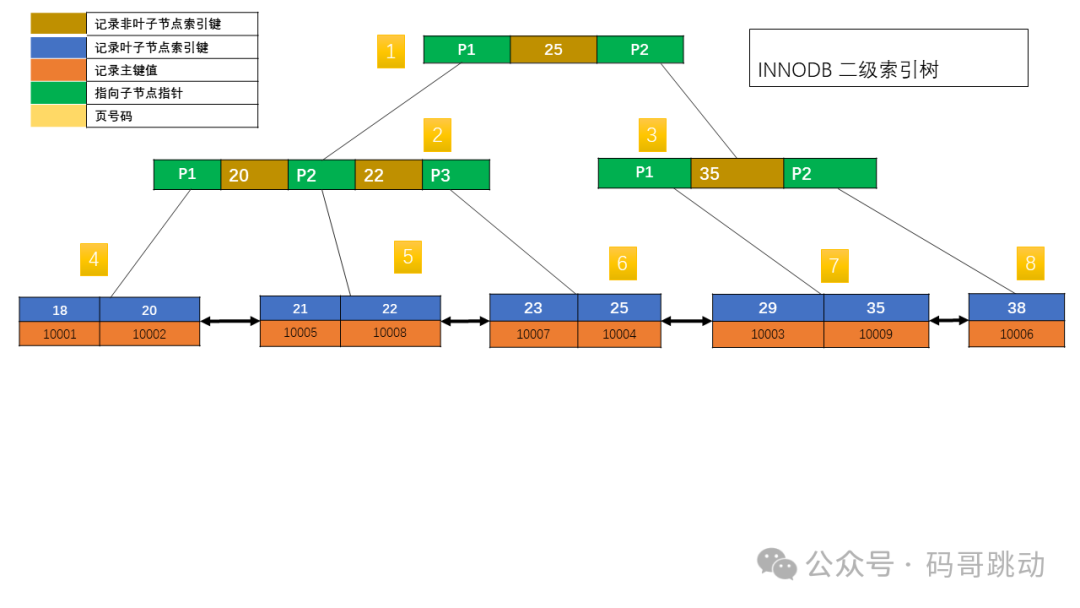 图片
图片
注意,在索引页的 Record 中的page pointer,指向的是页,而非具体的记录行。
并且 Record 的index key,为指向的 page records 的起始键值。
如果主键较长,二级索引会占用更多空间,因此拥有较短的主键是有利的。
在表空间文件的一个页的结构上,内容布局为:
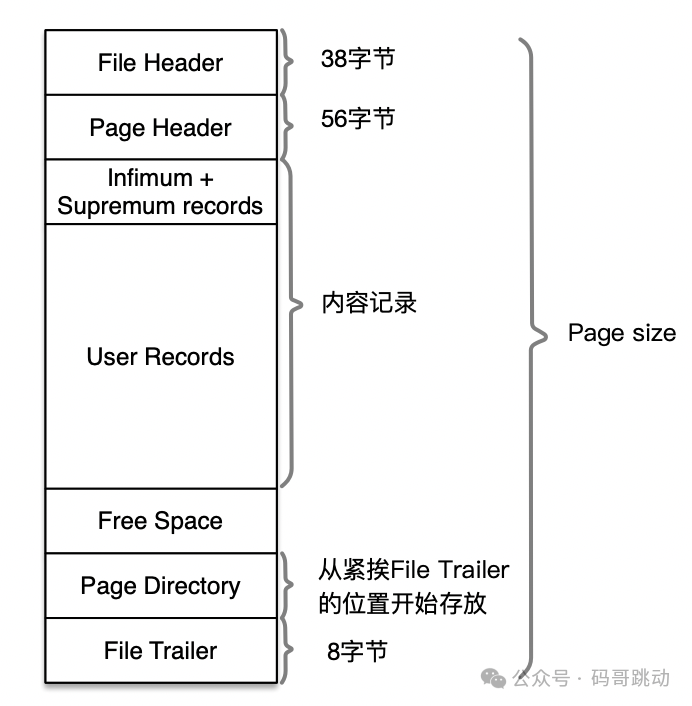 图片
图片
在聚集索引中,数据页内除了按照主键大小进行记录存放以外,在File header中,有两个字段:fil_page_prev 和fil_page_next, 分别记录了上一页/下一页的偏移量(offset),用以实现数据页在 B+ Tree 叶子位置的双向链表结构。
数据如何被查找检索呢?
通过 B+ Tree 结构,可以明显看到,通过 B+ Tree 查找,可以定位到索引最后指向的数据页,并不能找到具体的记录本身。
这时,数据库会将该页加载到内存中,然后通过Page Directory进行二分查找。









