


PG 的 Bgwriter 为什么搞得那么复杂
我是从C程序员转DBA的,所以遇到数据库的一些问题,我总是喜欢从一个码农的角度去发出灵魂拷问:为什么会这样?为什么要这样?这么做有啥必要?经过二十多年时间,Oracle的一些犄角旮旯的问题都被我理解和接受了。刚刚转向PG数据库的学习的时候,对PG这个简单但是庞大的数据库系统的一些行为十分不解。今天我们就来聊聊我对BGWRITER的一些思考。
PG的后台写入器(Background Writer, bgwriter)负责将脏页(即被修改但尚未写入磁盘的数据页)从共享缓冲区写回到磁盘,从而减少直接由前端查询进程执行写操作的需求,BGWRITER对数据库的性能优化具有重要作用。对Oracle的dbwr的算法比较了解的DBA刚开始可能很难理解PG的刷脏机制。因为除了BGWriter之外,Checkpoint、Backend都有刷脏的行为。Checkpoint刷脏比较容易理解,因为早期Oracle的CKPT也是有刷脏行为的。需要Checkpoint的时候,如果发现某些需要写入的脏块暂时还没有写入,并且这些数据块当前处于可以写入的状态,这种情况下CKPT顺手就做了。后来为了解决高并发环境下的闩锁开销问题,O记才让CKPT不再刷脏,提高Checkpoint推进的速度。
PG和O记最大的不同是Backend也是有刷脏行为的,这个设计刚开始的时候让我感到十分不解。BGWriter和Checkpoint都可以刷脏对于闩锁争用来说问题还不是太大,顶多是两个会话协同好就行了,而Backend的数量可能很庞大,如果同时又刷脏需求的话,协调好共享池相关数据结构的LWLOCK成本就低不了。
BGWriter在扫描共享缓冲区时,采用了一种基于LRU(Least Recently Used,最近最少使用)算法的启发式方法来选择要刷新的页面。具体来说BGWriter会优先对最近最少被使用的脏页进行回写,即这些页面在未来短时间内不太可能被再次访问,因此将它们写回到磁盘可以释放内存而不大影响性能。如果一个页面当前正被其他后端进程读取或修改,那么BGWriter会跳过该页面。除此之外,BGWriter的行为受bgwriter_lru_maxpages和bgwriter_lru_multiplier等参数的影响。每次循环中,BGWriter尝试写的最大脏页数由bgwriter_lru_maxpages指定,而实际尝试写的页数则根据系统近期需求动态调整,这取决于bgwriter_lru_multiplier。如果当前循环中已达到设定的最大写入页数限制,则即使还有未处理的脏页,也会暂时跳过。
bgwriter_lru_maxpages参数比较容易理解,就是bgwriter一个批处理任务中刷脏的最大脏页数量,刷够了这些页,bgwriter就结束这次任务,进入休眠。bgwriter_lru_multiplier 是一个用于调整PostgreSQL后台写入器(Background Writer, BGWriter)行为的重要参数。它决定了BGWriter尝试预测需要刷新多少页面到磁盘的积极程度,基于最近几次前台请求所需页面数量进行计算。BGWriter会监控最近几次前台请求所需的新缓冲区页面数,并将这个数值乘以 bgwriter_lru_multiplier 来决定下一次循环应该尝试刷新多少个脏页回到磁盘。假设最近几次前台请求所需的平均新缓冲区页面数为N,则在下一个周期内,BGWriter将会尝试刷新 N * bgwriter_lru_multiplier 个脏页。这意味着如果 bgwriter_lru_multiplier 设置得较高,BGWriter就会更积极地尝试将更多的脏页写回磁盘;反之,如果设置得较低,则BGWriter的行为会更加保守。
与BGWriter相对保守的刷脏策略相比,Checkpoint是一种强制刷脏机制。Checkpoint的主要目的是缩短崩溃恢复时间,因为它限定了恢复过程中需要回放的WAL(Write-Ahead Logging)日志的范围。Checkpoint可以由多种条件触发,包括达到checkpoint_timeout设定的时间间隔(默认为5分钟),或WAL文件使用量达到了max_wal_size。此外,也可以手动触发Checkpoint。当Checkpoint开始时,PostgreSQL会强制将所有脏数据页写回到磁盘。这包括但不限于共享缓冲区中的数据页。为了保证一致性,Checkpoint期间不允许新的事务提交(尽管允许读取和正在进行的事务继续)。整个过程包括了标记一个检查点记录到WAL日志中,并更新控制文件以反映最新的检查点信息。与BGWriter不同,Checkpoint刷脏的主要目的是提供一个已知的一致状态点,以便于系统崩溃后快速恢复。通过定期创建这些一致状态点,可以限制恢复过程中需要处理的日志量。
上面的刷脏机制还是比较容易理解的,PG中最不好理解的就是Backend也有写脏块的行为,而在其他数据库中,这个工作完全是由后台进程来完成的。当一个Backend进程需要读取一个新的数据块到共享缓冲区中,但当前没有可用的空闲缓冲区时,就会触发缓冲区替换机制(如使用 ClockSweep 算法)。如果选中的替换页面是脏页(Dirty Page),那么该页面必须被写回磁盘。
这个机制存在一个比较大的问题,那就是很可能一个SELECT操作操作会产生写IO操作,从而让某个SELECT操作的执行延时加大。我前两天也谈到Oracle也存在一些引起执行效率不稳定的行为。不过Oracle的这些行为发生的概率极低,甚至在一些负载不是特别大的系统中很少遇到。而在PG中我们经常会遇到这些情况的。
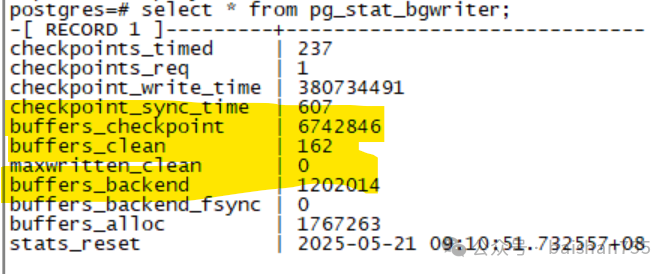 图片
图片
这是我们生产环境的一个PG 14数据库,可以看出,真正由BGWriter刷脏的数量只有162,而Backend刷脏的数量为120万块。似乎BGWriter有点不务正业了。
这种情况的发生与PG数据库的设计初衷有关,PG数据库作为最为流行的开源数据块之一,从开始并不是为高并发、高负载的企业级应用设计的,虽然这些年其企业级特性越来越多,但是一些根子上的问题还是沿用了早期的设计。为了适应早期的低成本IO设备,PG在性能上做出了大量的妥协。因为FULL PAGE WRITE机制的存在,导致了PG数据库总是希望脏块能够尽可能比较晚地回写到存储系统中,Checkpoint也尽可能的不要太快。将刷脏工作分散到大量的Backend中去,也是对IO的一种妥协,一方面可以缓解Checkpoint过重对IO的影响,一方面也简化了Backend在共享缓冲区不足时重用脏块的处置方法。
曾经在和一个搞PG的朋友谈到今天讨论的问题的时候,他十分兴奋地提出他的观点,他认为PG这方面的设计十分优秀,十分巧妙。我倒是有些不同的观点,认为这是PG数据库成为高负载的企业级数据库路上的一个必须优化的拦路虎。在现代硬件条件下,这方面的设计完全可以做优化了。我想随着AIO/DIO等IO技术的引进,消除Backend写脏块的条件也逐步成熟了。
今天时间有限,我们先谈到这里吧,明天我将继续这个话题,讨论一下,基于如此复杂的PG刷脏机制,DBA改如何去调整他们的数据库,从而适应自己的业务场景。明天再聊吧。









