


如何应对 Redis 大 Key 问题
日常业务运行过程中,Redis 实例经常因各种 Big keys / Hot Keys 的问题未及时处理,导致服务性能下降、访问超时、用户体验变差,甚至可能造成实例大范围故障 。
这篇文章,我们聊聊生产环境,如何应对 Redis 大 Key 问题。
 图片
图片
一、什么是大 key
大 Key 具体表现为 Redis 中的 Key 对应的 Value 很大,占用 Redis 空间比较大,本质上是大 Value 问题。
对于 Redis 中不同的数据结构类型,常见示例如下所示:
对于 String 类型的 Value 值,值超过 10MB(数据值太大)。
对于 Set 类型的 Value 值,含有的成员数量为 10000 个(成员数量多)。
对于 List 类型的 Value 值,含有的成员数量为 10000 个(成员数量多)。
对于 Hash 格式的 Value 值,含有的成员数量 1000 个,但所有成员变量的总 Value 值大小为 1000 MB(成员总的体积过大)。
在 Redis 的实际应用中,大 Key 问题的定义和评判标准并非固定不变,而是需要结合具体业务场景和性能需求进行综合考量。
例如,在高并发、低延迟的敏感场景下,即使 10 KB 的数据也可能被视为大 Key;而在低并发、高吞吐量的离线处理环境中,大 Key 的阈值可能放宽至 100 KB 甚至更高。
因此,在 Redis 的设计和使用过程中,应该基于业务特性和性能指标来制定合理的大 Key 评估标准。
二、大 key 有什么影响
Redis 是单线程执行命令 ,当前面的任务完成不了,那后面的命令就会阻塞,从而导致如下的结果:
1.请求响应时间上升,超时阻塞。
Redis 是单线程架构,操作大 Key 耗时较长,可能造成请求阻塞。
2.同步中断或主从切换
内存不足时,对大 Key 进行驱逐操作或者 rename 一个大 Key,容易长时间阻塞主库,进而可能引发同步中断或主从切换。
3.网络拥塞
一个大 Key 占用空间是 1MB,每秒访问1000 次,就有1000 MB 的流量,可能造成实例或局域网的带宽被占满,自身服务变慢,同时影响其他服务。
4.内存使用不均匀
在 Redis 集群架构中,某个数据分片的内存使用率远超其他数据分片,内存资源无法达到均衡。另外,Redis 内存可能达到 maxmemory 参数定义的上限,导致重要的 Key 被逐出,甚至引发内存溢出。
需要强调的是:
对于 Java 应用来讲,高并发场景 大 Key 问题容易导致应用服务器 CPU Load / 内存占用飙高。
 图片
图片
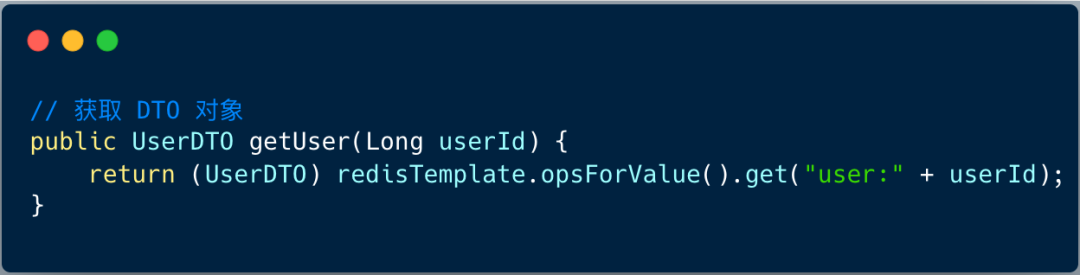
如图,这个一个非常标准的通过 redisTemplate 查询用户缓存信息的方法。
但当用户 DTO 对象占用内存大小达到 300k ~ 500k 时,并发高情况下,海量 UserDTO 对象会在新生代产生,对象序列化 和 GC 线程会大量占用 CPU 资源,导致 CPU Load 飙高 ,最终应用线程大面积阻塞。
三、大 key 是如何产生的
1.错误的技术选型
比如使用 String 类型的 Key 存放大体积二进制文件型数据,从而造成 key 对应的 value 值特别大 ;
2.List 、Set 数据类型数据未清理

如图,我们经常使用 Redis List 作为消息队列,在实际使用中经常出现如下问题:生产者发送消息过快,但消费者消费消息速度低,导致数据堆积占用大量内存空间 。
3.数据没有合理做分片
业务上线前,对业务分析不准确,没有对 Key 中的成员进行合理的拆分,造成个别 Key 中的成员数量过多。
四、如何找到大 key
1.bigkeys 命令
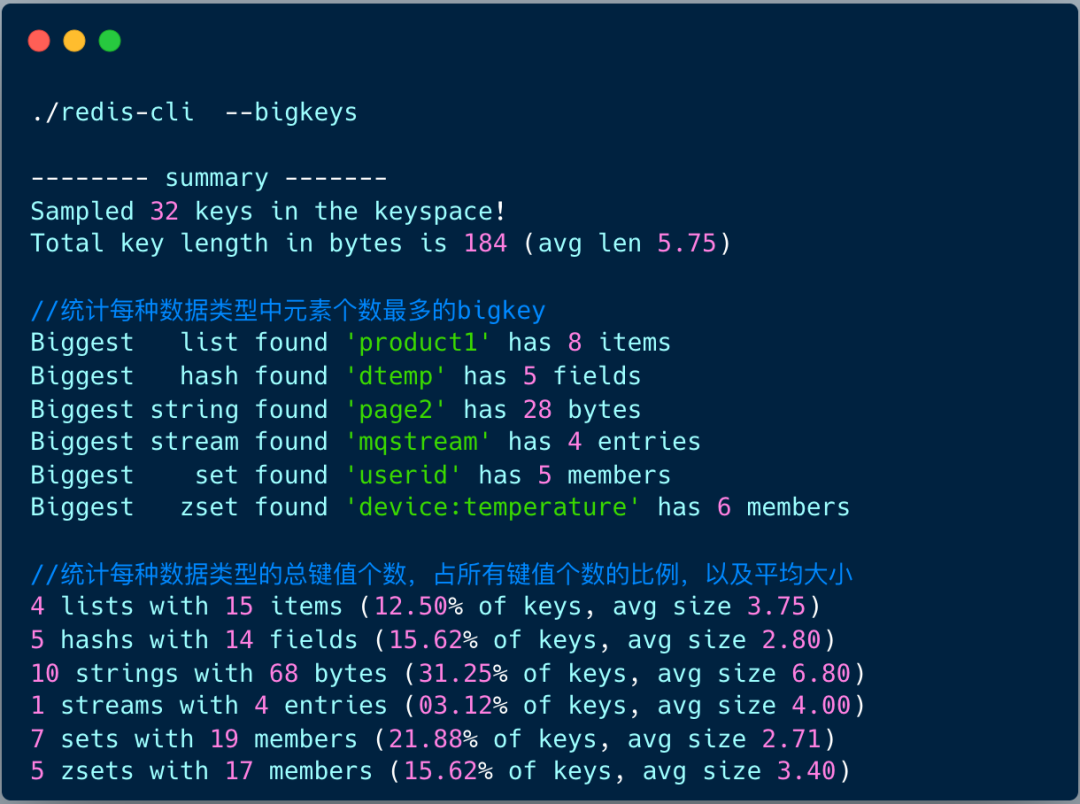
执行 redis-cli 命令时带上–bigkeys 选项,对整个数据库中的键值对大小情况进行统计分析,统计每种数据类型的键值对个数以及平均大小。
此外,这个命令执行后,会输出每种数据类型中最大的 bigkey 的信息:
- 对于 String 类型来说,会输出最大 bigkey 的字节长度
- 对于集合类型来说,会输出最大 bigkey 的元素个数
 图片
图片
bigkeys 是通过扫描数据库来查找的,在执行的过程中,会对 Redis 实例的性能产生影响。
- 主从集群,建议在从节点上执行该命令,避免阻塞主节点。
- 没有从节点情况下,在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行。
2.监控平台
公有云或者公司内部架构部门一般都有监控平台,可以可视化分析 Redis 服务监控指标。
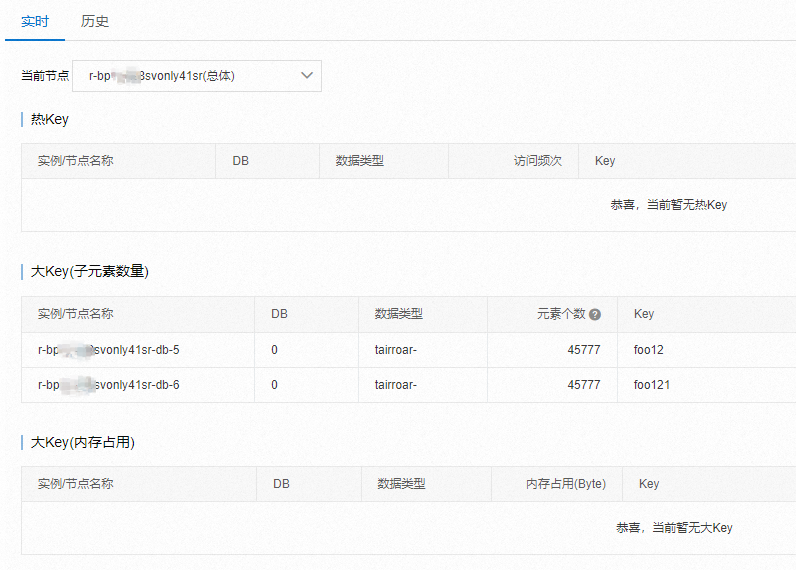
如下图是阿里云的 Redis 监控大 Key 分析界面 。
 图片
图片
假如是架构部门自己的监控平台,可以添加 Redis 的 Key 监控统计。
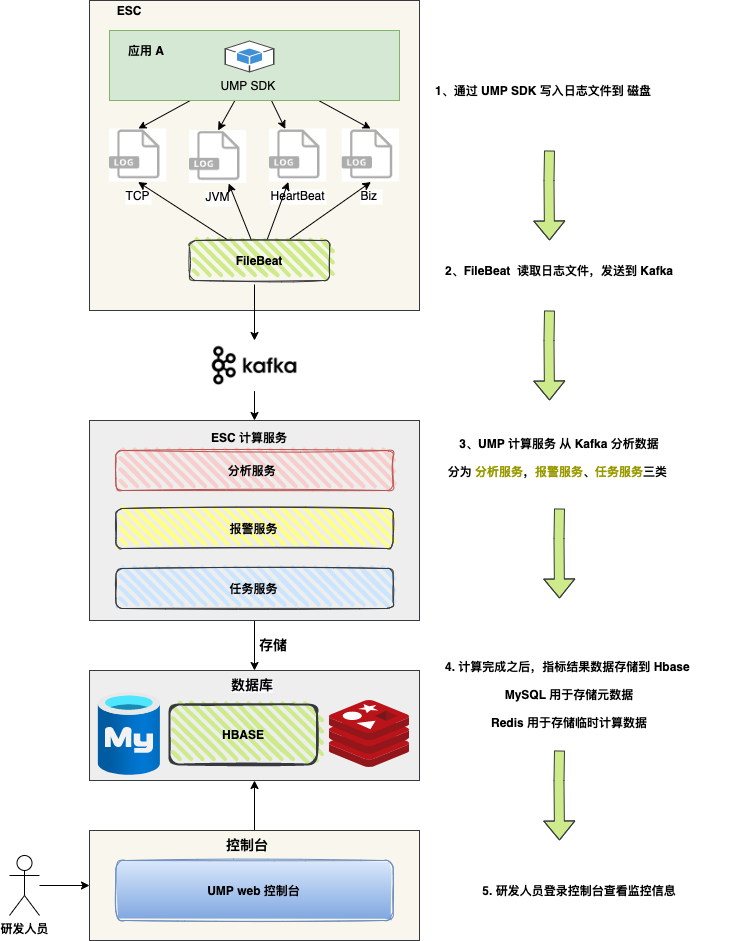
下图是UMP 监控平台的设计思路:
 图片
图片
流程如下:
- 业务系统引入通 UMP SDK ,当业务系统运行时,SDK 会将日志文件(JVM、TP 、HeatBeat)写到磁盘 ;
- FileBeat 读取日志文件,发送到 Kafka ;
- UMP 计算服务 从 Kafka 中获取消息,根据消息类型,执行分析逻辑(JVM、TP 、HeatBeat );
- 计算完成之后,指标结果数据存储到 Hbase,MySQL 用于存储元数据,Redis 用于存储临时计算数据 ;
- 研发人员登录控制台查看监控信息 ,核心的监控数据存储在 Hbase 中,通过 HighChart 组件渲染。
UMP 可以对应用端的 Redis 操作实现全面的监控,包括命令超时、Key大小、使用频率等关键指标。
五、如何解决大 key 问题
1.清理无效的数据
主要针对 list 和 set 这种类型,在使用的过程中,list 和 set 中对应的内容不断增加,需要定时的对 list 和 set 进行清理。
2.压缩对应的大 Key 的 Value
通过序列化或者压缩的方法对 value 进行压缩,使其变为较小的 value,但是如果压缩之后如果对应的 value 还是特别大的话,就需要使用拆分的方法进行解决。
3.针对大 Key 进行拆分
通过将 BigKey 拆分成多个小 Key 的键值对,并且拆分后的对应的 value 大小和拆分成的成员数量比较合理,然后进行存储即可,在获取的时候通过 get 不同的 key 或是用 mget 批量获取存储的键值对。
4.实时监控 Redis 内存、带宽及 Key 增长变化趋势
通过监控系统,监控 Redis 中的内存占用大小和网络带宽的占用大小,以及固定时间内的内存占用增长率,当超过设定的阈值的时候,进行报警通知处理。









