


大模型向量去重的N种解决方案!

简单来说,“向量”Vector 是大模型(LLM)在搜索时使用的一种“技术手段”,通过向量比对,大模型能找出问题的相关答案,并且进行智能回答。
向量简介
Vector 是向量或矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者描述的是同一件事。
“
定义:向量是用于表示具有大小和方向的量。
向量可以在不同的维度空间中定义,最常见的是二维和三维空间中的向量,但理论上也可以有更高维的向量。例如,在二维平面上的一个向量可以写作 (x,y),这里 x 和 y 分别表示该向量沿两个坐标轴方向上的分量;而在三维空间里,则会有一个额外的 z 坐标,即 (x,y,z)。
例如,有以下 4 种狗,我们要在大模型中如何表示它们呢:

我们就可以使用向量来表示,如下图所示:
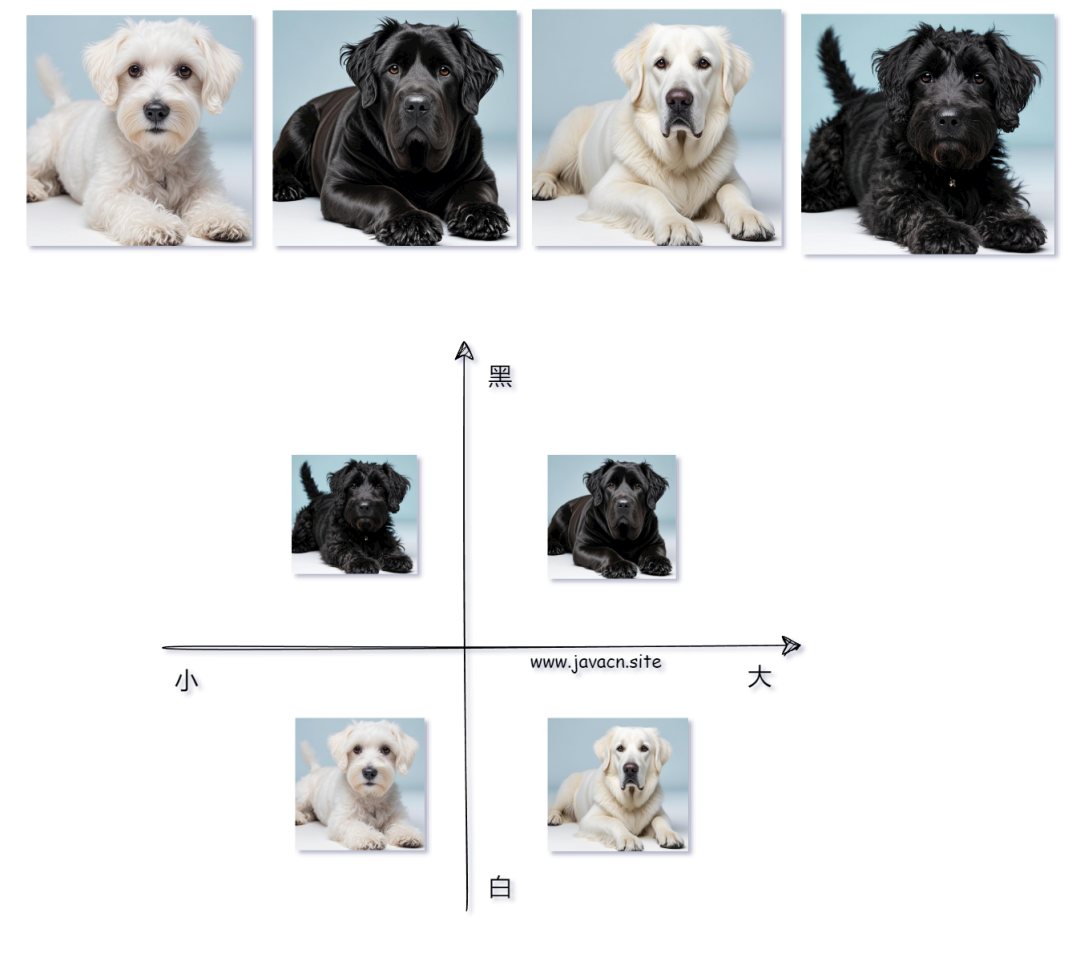
向量关系图:
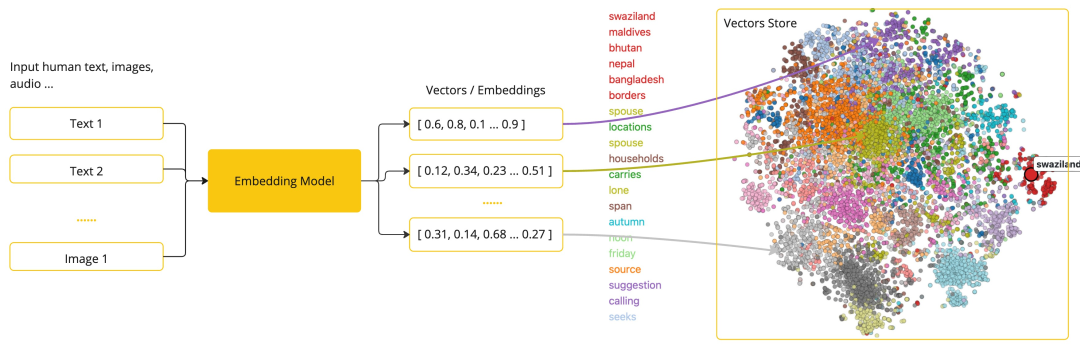
向量数据库
定义:向量数据库是一种专门用于存储、管理和检索向量数据(即高维数值数组)的数据库系统。其核心功能是通过高效的索引结构和相似性计算算法,支持大规模向量数据的快速查询与分析。
向量数据库以向量为基本存储单元,这些向量通常由文本、图像、音频等非结构化数据通过深度学习模型(如 Embedding 技术)转换而来,每个向量代表对象在多维空间中的特征。例如,一段文本可转化为 512 维的浮点数向量,用于表示其语义信息。
“
向量数据库维度越高,查询精准度也越高,查询效果也越好。
常用向量数据库
Java 领域常用的向量数据库有:
- Redis Stack:原有 Redis 服务升级之后就可以用来存储向量数据。
- Elastic Search
- Milvus:一款开源的高性能向量数据库,专为存储、索引和检索大规模向量数据而设计。它可以实现万亿级向量的毫秒级相似性搜索。
向量数据去重
向量数据库去重通常是在添加时进行判断,它主要实现方式有以下几种:
- 基于向量相似度去重。
- 基于 Redis 唯一键去重。
- 使用 Redis SetNX 去重。
- 基于 Redis Set 数据结构去重。
具体实现如下。
1.基于向量相似度去重
原理:在插入前计算新向量与已有向量的余弦相似度,若超过阈值(如 0.95)则视为重复。
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(newEmbedding)
.maxResults(1)
.minScore(0.95) // 相似度阈值
.build();
List> matches = embeddingStore.search(request);
if (matches.isEmpty()) {
embeddingStore.add(newEmbedding, textSegment);
} 优点:语义级去重,适合文本内容相似但表述不同的场景。
缺点:存在线程安全问题,多任务同时执行,可能导致插入重复数据。
2.基于 Redis 唯一键去重
原理:使用文本内容的哈希值(如 MD5)作为 Redis Key 的一部分,确保唯一性。
String textHash = DigestUtils.md5Hex(textSegment.text());
String redisKey = "embedding:" + textHash;
if (!redisTemplate.hasKey(redisKey)) {
embeddingStore.add(newEmbedding, textSegment);
redisTemplate.opsForValue().set(redisKey, "1");
}优点:性能高,适合完全相同的文本内容。
缺点:存在线程安全问题,多任务同时执行,可能导致插入重复数据。
3.使用 Redis SetNX 去重
原理:使用 Redis 的 SETNX(set if not exists)命令,避免非原子性问题,它是先判断才插入,如果已经存在就不再插入了。
具体实现代码如下:
// 生成文本的唯一哈希(如 MD5)
String textHash = DigestUtils.md5Hex(textSegment.text());
String redisKey = "vector:" + textHash;
// 判断是否存在
Boolean isSet = redisTemplate.opsForValue()
.setIfAbsent(redisKey, "1");
if (Boolean.TRUE.equals(isSet)) {
// 键不存在,保存向量数据
embeddingStore.add(embedding, textSegment);
} else {
// 键已存在,跳过或报错
throw new RuntimeException("重复数据");
}优点:性能高,不存在线程安全问题。
4.基于 Redis Set 数据结构去重
原理:Set 去重,将向量 ID 或文本哈希存入 Redis Set,插入前检查是否存在。
// 生成文本的唯一哈希(如 MD5)
String textHash = DigestUtils.md5Hex(textSegment.text());
if (redisTemplate.opsForSet().add("unique_embeddings", textHash) == 1) {
embeddingStore.add(newEmbedding, textSegment);
}优点:简单高效,不存在线程安全问题。
缺点:需维护额外的 Set 数据结构。
小结
向量数据库去重一定是生产环境要做的事,它的解决方案也有很多,通常我们会选择一种高效、且没有线程安全的解决方案,例如 Redis SetNX 或 Set 数据结构来解决。









