


亿级流量,如何保证Redis与MySQL的一致性?失败如何设计补偿?
说在前面
只要使用到缓存,无论是本地缓存还是使用Redis做缓存,那么就会存在数据同步不一致的问题。
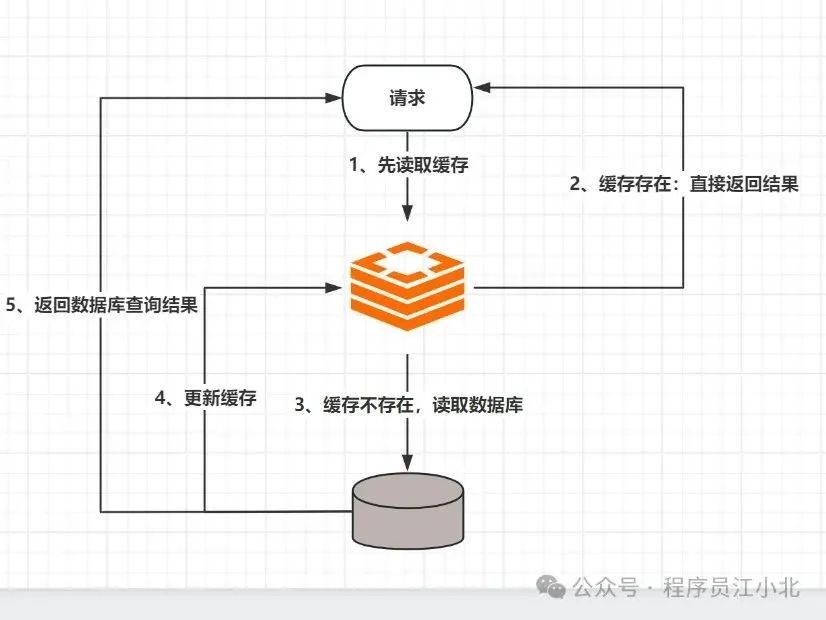
1、 先读取缓存,缓存数据有,则立即返回结果;
2、 如果缓存中没有数据,则从数据库中读取数据;
3、 把读取到的数据同步到缓存中,提供下次读请求返回数据;
这样的作法是大多数人使用缓存的方式,这样能有效减轻数据库压力,但是如果修改删除数据,因为缓存无法感知到数据在数据库中的修改。
这样就会造成数据库中的数据与缓存中数据不一致。
那么该如何解决呢?
有下面4种解决方案:
1、 先更新缓存,再更新数据库;
2、 先更新数据库,再更新缓存;
3、 先删除缓存,后更新数据库;
4、 先更新数据库,后删除缓存;
下面我们一一来看下每个方案的可行性:
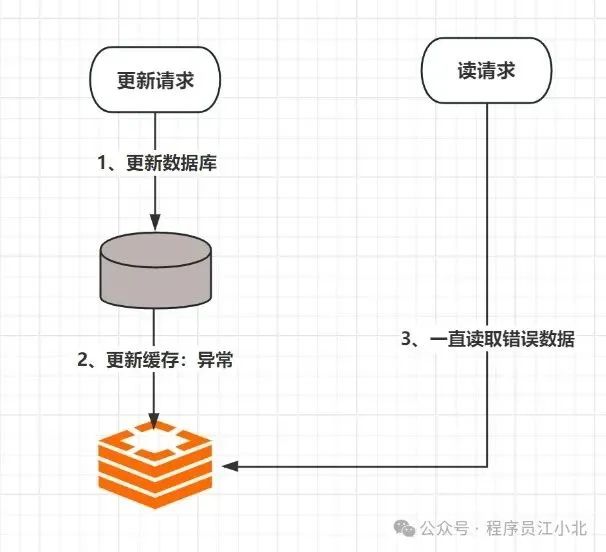
一、先更新缓存,再更新数据库
这个方案我们一般不考虑。原因是更新缓存成功,但是更新数据库出现异常了。
会导致缓存数据与数据库数据完全不一致,而且很难察觉,因为缓存中的数据一直都存在。
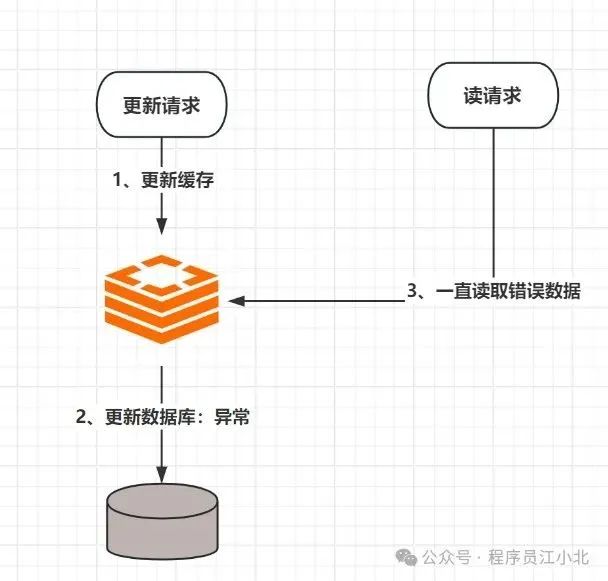
二、先更新DB,再更新缓存
这个方案我们一般也是不考虑,原因跟方案1一样,数据库更新成功了,缓存更新失败,同样会出现数据不一致问题,且不容易被发现,因为缓存中一直存在数据。
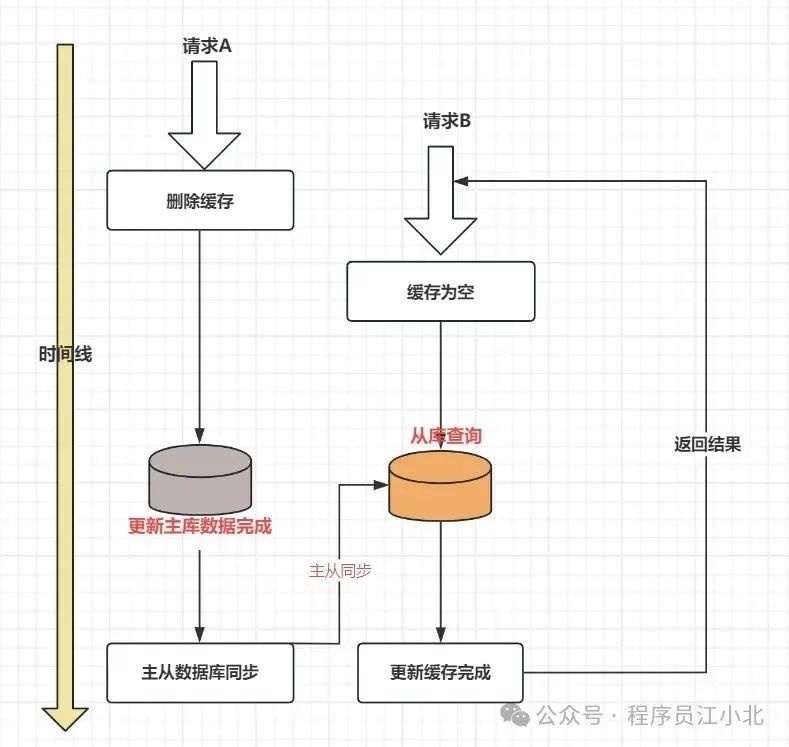
三、先删除缓存,后更新DB
这个方案再并发场景下也会出问题,具体出现的原因如下:
两个并发请求:请求A(更新操作)和请求B(读取操作)
1、 请求A会先删除Redis中的数据,然后去更新数据库;
2、 此时请求B看到Redis中的数据是空的,回去数据库中查询该值,补充到Redis缓存中;
3、 此时请求A并没有更新成功,或者是事务还未提交(MySQL的事务隔离级别,会导致未提交的事务数据不会被另一个线程看到),请求B去数据库查询得到旧值.;
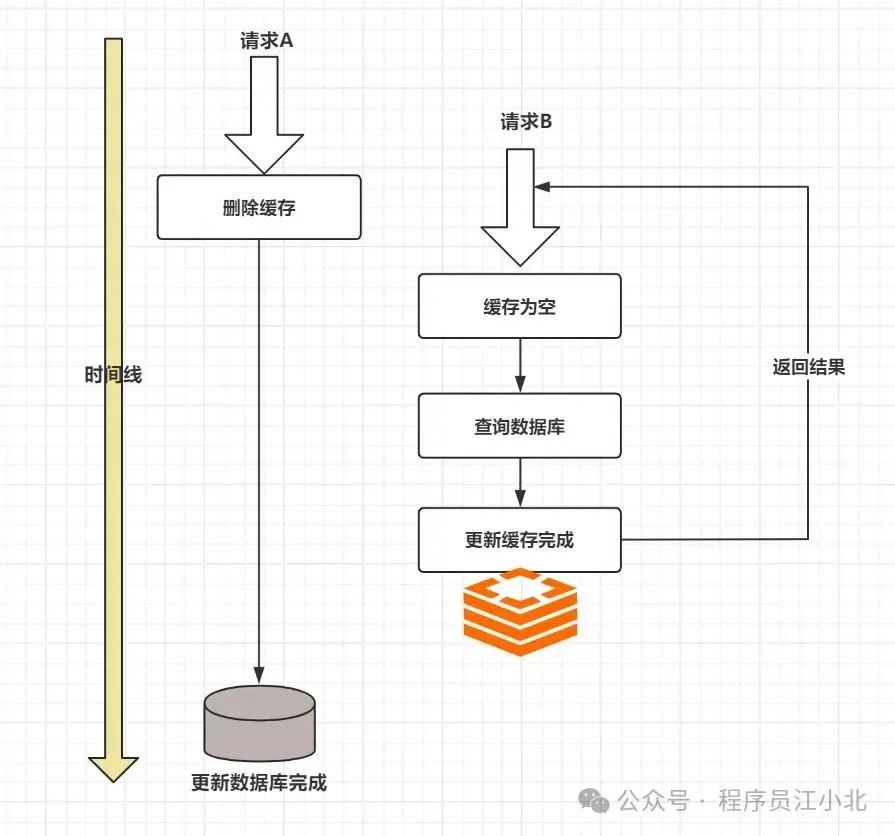
这时候就会产生数据库和Redis数据不一致的问题。
因此一般也不建议这种方式
虽然不建议,但是如果你是采用了这种方式,该如何解决数据不一致的问题呢?
其实最简单的办法就是延时双删的策略:
1、 先淘汰缓存;
2、 再写数据库;
3、 休眠1s,再次淘汰缓存;
这样做,可以将1s内所造成的缓存脏数据,再次删除。
但是,但是,这个1s怎么确定的,具体该休眠多久呢?
1、 自行评估自己的项目的读数据业务逻辑的耗时(这个我们可以利用SkyWalking等监控工具评估耗时);
2、 评估写数据的休眠时间(在读数据业务耗时的基础上,加几百ms即可);
这样做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
延时双删就能彻底解决不一致吗?如果面试官这样问你,你千万不能回答是的。
第一,我们评估的延时时间(读请求耗时+几百毫秒),并不能完全代表实际运行过程中的耗时,运行过程如果因为系统压力过大,我们评估的耗时就是不准确,仍然会导致数据不一致的出现
第二,延时双删虽然在保证事务提交完以后再进行删除缓存,但是如果你使用的是MySQL的读写分离的机构,主从同步之间其实也会有时间差。
此时该如何解决呢?
解决办法有两个:
1、 还是使用延时双删策略,只是睡眠时间改为在主从同步的延时时间基础上,加几百毫秒(读接口耗时+主从延迟时间+几百毫秒);
2、 对Redis进行填充数据查询(更新缓存时查询数据库),强制走主库查询,那么我们延时双删就没必要增加主从延时时间了(增加个主从延时时间也会增加更大的不确定性,因为主从延时时间也是不稳定的);
如果面试官继续深入的问你,采用这种同步延时双删的淘汰策略,接口的吞吐量降低怎么办?(数据变更时,更新接口都要多休眠一个延时时间)
既然同步会降低吞吐量,那就同步改异步(性能优化的常用手段)。
将第二次删除的操作,异步起一个线程,异步删除,这样写的请求就不用沉睡一段时间后才能返回了。
总的来说,先删除缓存,再更新数据库的方式,还是瑕疵较多,发生数据一致性的问题和性能问题的概率更大。比如:
1、 先删除缓存可能导致读请求因缓存缺失而大量访问数据库(尤其是高并发场景的电商,可能一瞬间就把数据库打挂了);
2、 读请求接口的耗时和写缓存的时间,估算不够准确,会导致延迟双删中的sleep时间不好设置;
下面我们来看最后一种解决方案,这个解决方式是4个方案中发生数据不一致性的概率最低的。
四、先更新DB,后删除缓存
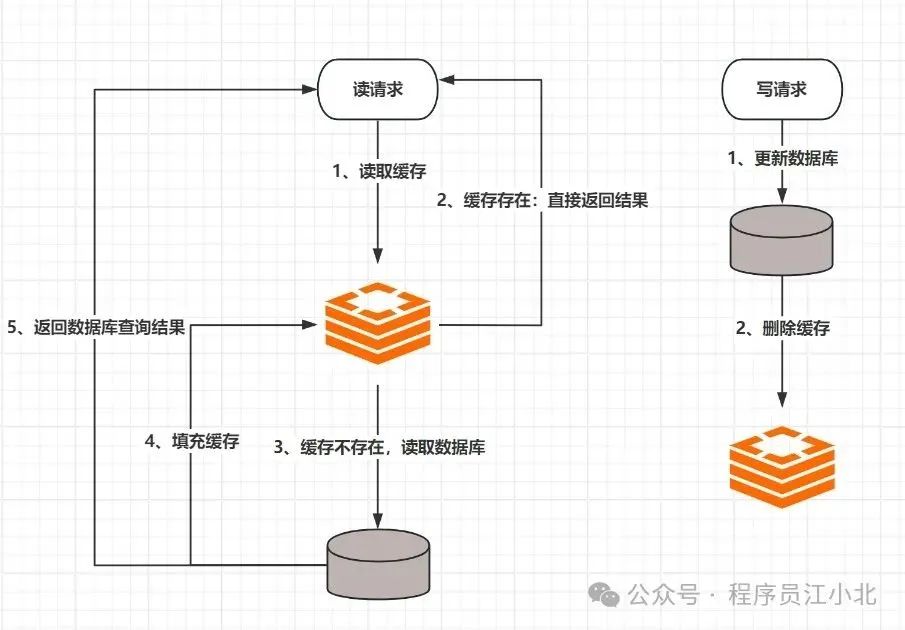
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓
存,同时返回响应。更新的时候,先更新数据库,然后再删除缓存。
这种方案下就不存在数据不一致性的问题了么?
其实是依然存在的,尤其是在大型互联网电商,高并发系统中,并发问题导致的数据一致性的数据量非常大。
假设两个请求,请求A和请求B,请求A做查询操作(读请求),请求B做更新操作(写请求)
当高并发场景下,会有如下情形出现:
1、 缓存刚好失效;
2、 请求A查询数据库,得到一个旧值;
3、 请求B将新值写入数据库;
4、 请求B删除缓存;
5、 请求A将查到的旧值写入缓存;
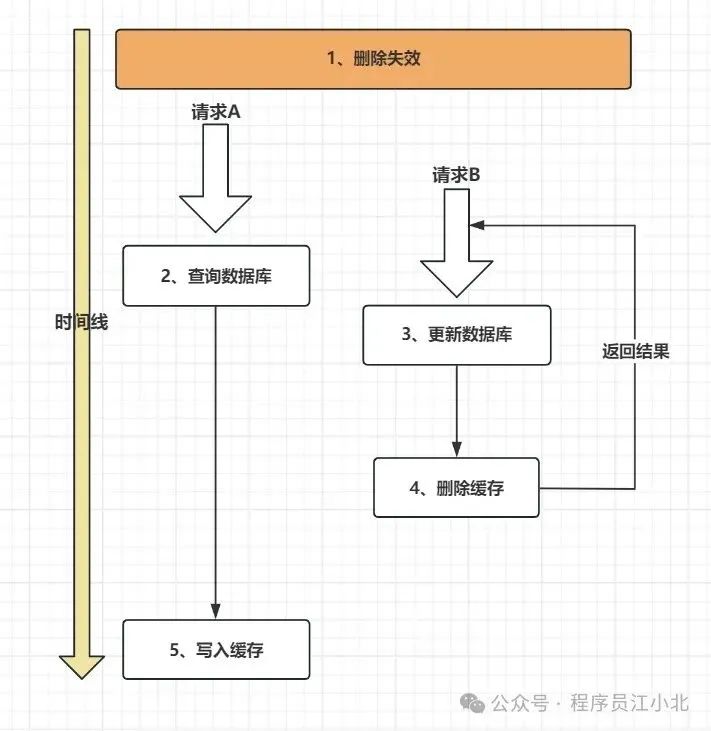
高并发场景下,确实有可能会发生上述的情况,产生脏数据。
然而,发生这种的概率又有多少呢?
❝
发生上述情况的一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。
可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少)。
因此步骤(3)耗时比步骤(2) 更短,这一情形很难出现。
但是,如果面试官问你:如果我的业务属性要求一定要解决怎么办?那么如何解决上述并发问题?
首先,给缓存设置过期时间是一种有效的方案。
如果你的业务数据对实时性要求不是很高,可以接受数据的短时间数据不一致的场景,我们此种方案就可以解决了(比如商品详情中的描述、属性等)
其次,仍可以采用异步延时删除的策略。
参考方案3中的异步延时删除策略方案,删除的方案其实还有问题,这个我们放在后面说
一般采用这些手段几乎就已经把Redis缓存和数据库数据不一致的概率降到了极低。
如果非要强一致性,极低的数据不一致的概率都不能接受,那么该如何解决呢?
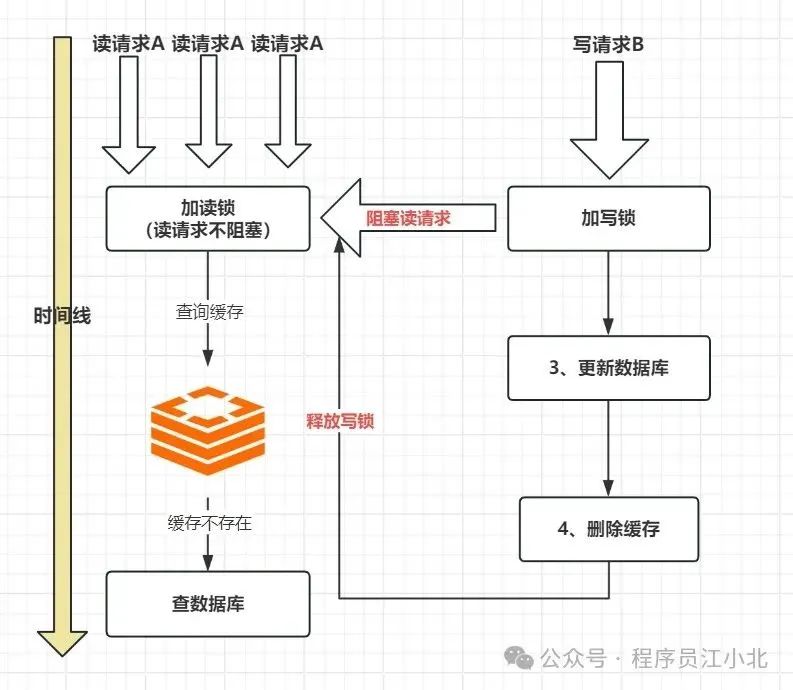
其实也有解决方案:那就是加锁,在读请求加一个读锁,所有的读请求不阻塞,在写请求加一个写锁,一旦有写请求,则暂时阻塞读,等写请求处理完,删除完缓存再放开读。
如果你的业务并发要求不高,读多写少,且对数据一致性有很高的要求,可以采用这种方案,但是保证强一致性的同时,就会损失一些性能,所以该不该用这种方案,大家可以根据自己业务的属性做好权衡。
方案补充(重要)
3、 4都属于删除缓存类,其实删除缓存类都会有一个共同的问题,那就是在删除缓存的阶段出错了怎么办?此时再读取缓存的时候每次都是错误的数据了;
此时解决方案有两个:
一、利用消息队列进行删除失败的补偿
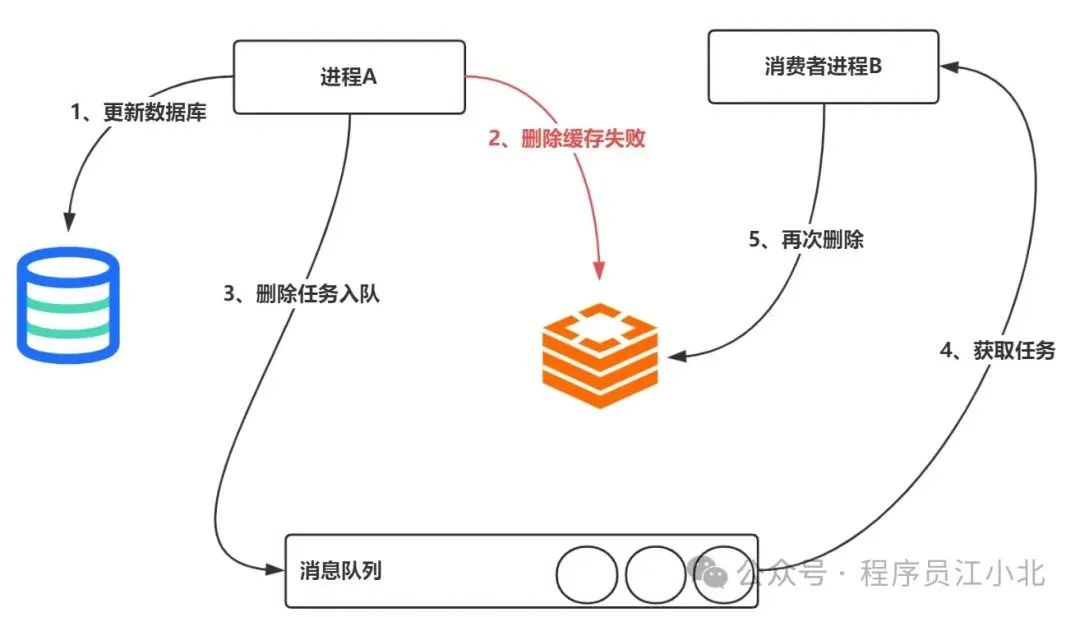
具体的业务逻辑如下:
1、 请求A先对数据库进行更新操作;
2、 在对Redis进行删除操作的时候发现报错,删除失败;
3、 此时将Redis的key作为消息体发送到消息队列中;
4、 系统接收到消息队列发送的消息后;
5、 再次对Redis进行删除操作;
但是这个方案会有一个缺点,就是会对业务代码造成大量的侵入,深深的耦合在一起。
所以还有一个优化的方案
二、订阅MySQL的binlog日志,异步删除
我们知道对 Mysql 数据库更新操作后 ,在 binlog日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql数据库 的 binlog日志对缓存进行操作,这样就达到了一个解耦的目的了。
业务代码流程如下:
1、 更新数据库,更新完成后,触发binlog消息;
2、 经常B(消费者)订阅binlog消息,执行缓存删除操作;
3、 缓存删除失败,将删除任务丢到消息队列中;
4、 进程B获取删除失败任务;
5、 执行二次删除redis缓存;
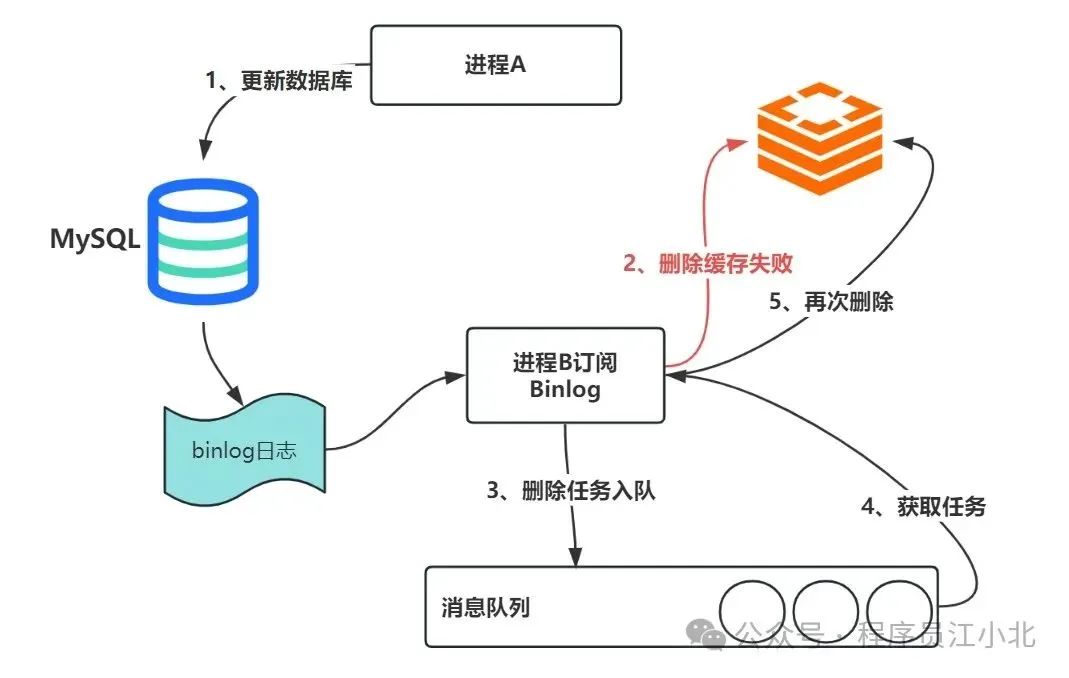
说到底就是通过数据库的 binlog 来异步淘汰 key,利用工具(canal)将 binlog
日志采集发送到 MQ 中,然后通过 ACK 机制确认处理删除缓存。
先更新DB,后删除缓存,这种方式,被称为 Cache Aside Pattern,属于缓存更新的经典设计模式之一。
所以如果大家做缓存与数据库的同步,推荐大家选择这一种方式。
总结
至此,亿级电商流量,高并发下Redis与MySQL的数据一致性如何保证的方案,非常圆满了。以上的内容,如果大家能烂熟于心、对答如流、如数家珍,基本上 面试官会被你 震惊到、吸引到。









