


给你1亿的Redis key,如何高效统计?
前言
有些小伙伴在工作中,可能遇到过这样的场景:老板突然要求统计Redis中所有key的数量,你随手执行了KEYS *命令,下一秒监控告警疯狂闪烁——整个Redis集群彻底卡死,线上服务大面积瘫痪。
今天这篇文章就跟大家一起聊聊如果给你1亿个Redis key,如何高效统计这个话题,希望对你会有所帮助。
1.为什么不建议使用KEYS命令?
Redis的单线程模型是其高性能的核心,但也是最大的软肋。
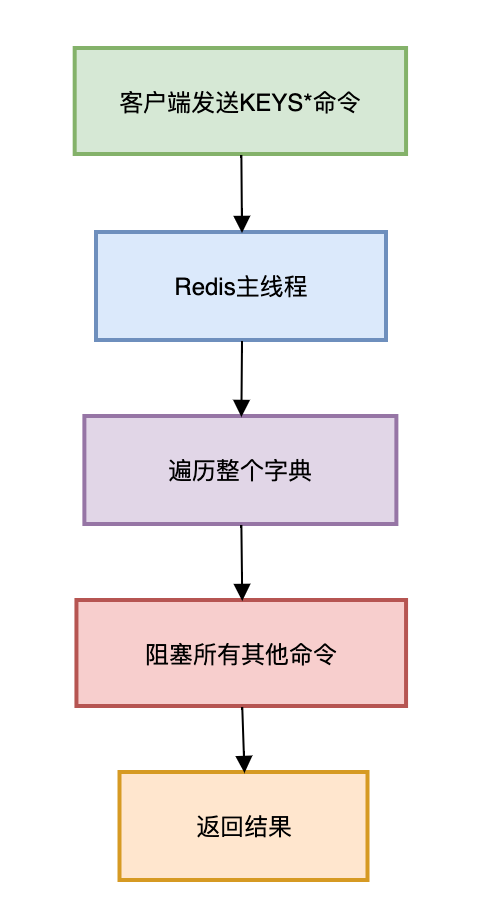
当Redis执行 KEYS * 命令时,内部的流程如下:
 图片
图片
Redis的单线程模型是其高性能的核心,但同时也带来一个关键限制:所有命令都是串行执行的。
当我们执行 KEYS * 命令时:
Redis必须遍历整个key空间(时间复杂度O(N))
在遍历完成前,无法处理其他任何命令
对于1亿个key,即使每个key查找只需0.1微秒,总耗时也高达10秒!
致命三连击:
- 时间复杂度:1亿key需要10秒+(实测单核CPU 0.1μs/key)
- 内存风暴:返回结果太多可能撑爆客户端内存
- 集群失效:在Cluster模式中只能查当前节点的数据。
如果Redis一次性返回的数据太多,可能会有OOM问题:
127.0.0.1:6379> KEYS *
(卡死10秒...)
(error) OOM command not allowed when used memory > 'maxmemory'超过了最大内存。
那么,Redis中有1亿key,我们要如何统计数据呢?
2.SCAN命令
SCAN命令通过游标分批遍历,每次只返回少量key,避免阻塞。
Java版基础SCAN的代码如下:
public long safeCount(Jedis jedis) {
long total = 0;
String cursor = "0";
ScanParams params = new ScanParams().count(500); // 每批500个
do {
ScanResult rs = jedis.scan(cursor, params);
cursor = rs.getCursor();
total += rs.getResult().size();
} while (!"0".equals(cursor)); // 游标0表示结束
return total;
} 使用游标查询Redis中的数据,一次扫描500条数据。
但问题来了:1亿key需要多久?
- 每次SCAN耗时≈3ms
- 每次返回500key
- 总次数=1亿/500=20万次
- 总耗时≈20万×3ms=600秒=10分钟!
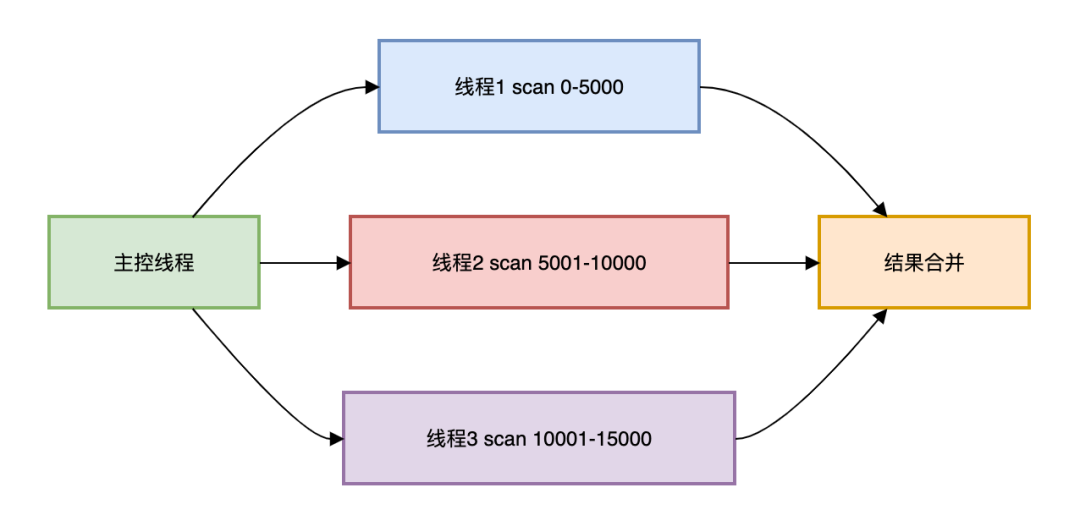
3.多线程并发SCAN方案
现代服务器都是多核CPU,单线程扫描是资源浪费。
看多线程优化方案如下:
 图片
图片
多线程并发SCAN代码如下:
public long parallelCount(JedisPool pool, int threads) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(threads);
AtomicLong total = new AtomicLong(0);
// 生成初始游标(实际需要更智能的分段)
List cursors = new ArrayList<>();
for (int i = 0; i < threads; i++) {
cursors.add(String.valueOf(i));
}
CountDownLatch latch = new CountDownLatch(threads);
for (String cursor : cursors) {
executor.execute(() -> {
try (Jedis jedis = pool.getResource()) {
String cur = cursor;
do {
ScanResult rs = jedis.scan(cur, new ScanParams().count(500));
cur = rs.getCursor();
total.addAndGet(rs.getResult().size());
} while (!"0".equals(cur));
latch.countDown();
}
});
}
latch.await();
executor.shutdown();
return total.get();
} 使用线程池、AtomicLong和CountDownLatch配合使用,实现了多线程扫描数据,最终将结果合并。
性能对比(32核CPU/1亿key):
方案 | 线程数 | 耗时 | 资源占用 |
单线程SCAN | 1 | 580s | CPU 5% |
多线程SCAN | 32 | 18s | CPU 800% |
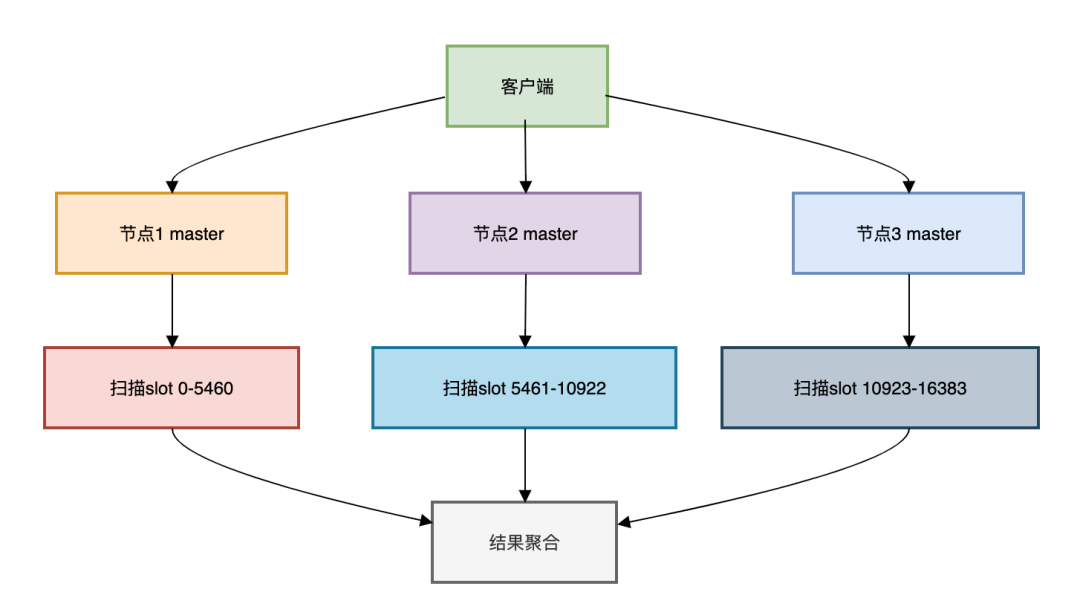
4.分布式环境的分治策略
如果你的系统重使用了Redis Cluster集群模式,该模式会将数据分散在16384个槽(slot)中,统计就需要节点协同。
流程图如下:
 图片
图片
每一个Redis Cluster集群中的master服务节点,都负责统计一定范围的槽(slot)中的数据,最后将数据聚合起来返回。
集群版并行统计代码如下:
public long clusterCount(JedisCluster cluster) {
Map nodes = cluster.getClusterNodes();
AtomicLong total = new AtomicLong(0);
nodes.values().parallelStream().forEach(pool -> {
try (Jedis jedis = pool.getResource()) {
// 跳过从节点
if (jedis.info("replication").contains("role:slave")) return;
String cursor = "0";
do {
ScanResult rs = jedis.scan(cursor, new ScanParams().count(500));
total.addAndGet(rs.getResult().size());
cursor = rs.getCursor();
} while (!"0".equals(cursor));
}
});
return total.get();
} 这里使用了parallelStream,会并发统计Redis不同的master节点中的数据。
5.毫秒统计方案
方案1:使用内置计数器
如果只想统计一个数量,可以使用Redis内置计数器,瞬时但非精确。
127.0.0.1:6379> info keyspace
# Keyspace
db0:keys=100000000,expires=20000,avg_ttl=3600优点:毫秒级返回。
缺点:包含已过期未删除的key,法按模式过滤数据。
方案2:实时增量统计
实时增量统计方案精准但复杂。
基于键空间通知的实时计数器,具体代码如下:
@Configuration
publicclass KeyCounterConfig {
@Bean
public RedisMessageListenerContainer container(RedisConnectionFactory factory) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(factory);
container.addMessageListener((message, pattern) -> {
String event = new String(message.getBody());
if(event.startsWith("__keyevent@0__:set")) {
redisTemplate.opsForValue().increment("total_keys", 1);
} elseif(event.startsWith("__keyevent@0__:del")) {
redisTemplate.opsForValue().decrement("total_keys", 1);
}
}, new PatternTopic("__keyevent@*"));
return container;
}
}使用监听器统计数量。
成本分析:
- 内存开销:额外存储计数器
- CPU开销:增加5%-10%处理通知
- 网络开销:集群模式下需跨节点同步
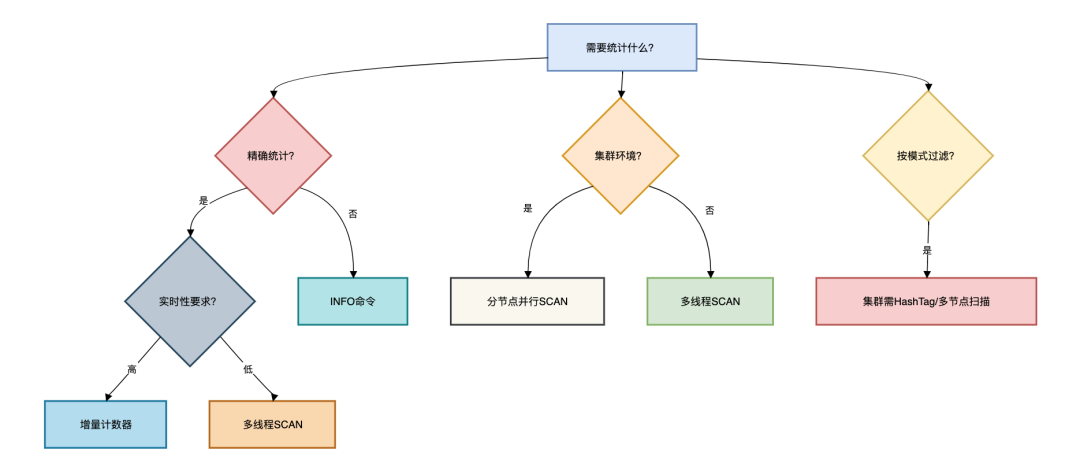
6.如何选择方案?
本文中列举出了多个统计Redis中key的方案,那么我们在实际工作中如何选择呢?
下面用一张图给大家列举了选择路线:
 图片
图片
各方案的时间和空间复杂度如下:
方案 | 时间复杂度 | 空间复杂度 | 精度 |
KEYS命令 | O(n) | O(n) | 精确 |
SCAN遍历 | O(n) | O(1) | 精确 |
内置计数器 | O(1) | O(1) | 不精确 |
增量统计 | O(1) | O(1) | 精确 |
硬件法则:
- CPU密集型:多线程数=CPU核心数×1.5
- IO密集型:线程数=CPU核心数×3
- 内存限制:控制批次大小(count参数)
常见的业务场景:
- 电商实时大屏:增量计数器+RedisTimeSeries
- 离线数据分析:SCAN导出到Spark
- 安全审计:多节点并行SCAN
终极箴言:✅ 精确统计用分治✅ 实时查询用增量✅ 趋势分析用采样❌ 暴力遍历是自杀
真正的高手不是能解决难题的人,而是能预见并规避难题的人。
在海量数据时代,选择比努力更重要——理解数据本质,才能驾驭数据洪流。









