


浅谈分布式、伪分布式与集中式之选
近期跟多家用户交流,发现用户在选型数据库时正有了一些新的变化,这也是近些年通过不断实践,用户总结的最佳实践方法。例如,有的用户不盲目追求分布式,而是通过业务单元化后,底层通过集中式数据库解决;有的用户选择分布式数据库,但在应用上通常是按照“单机”模式去使用,即不做数据分片;有的用户利用分布式数据库提供的租户特性,做单机数据库的整合;也有的用户回归“传统”的集中式共享存储架构来解决问题。上面谈到的租户及单机模式的使用方法,可以说是一种“伪分布式”。那么在面临这些“新架构、新用法”,用户又该如何选择呢?本文选择了分布式和集中式的多种主流用法,尝试从多种角度来对比分析下。
1. 多角度对比数据库主流用法
1).谈谈“伪分布式”
在正式对比之前,这里先谈下伪分布式的两种用法。第一种“单机”模式,其实是一种对分布式的妥协,放弃了分布式能力,选择单机式的使用方法。这种通常发生在用户已经选择使用分布式数据库,但其更多业务是不需要采用分布式使用方式,但选择另一款集中式数据库又需要引入新的技术栈,因而采用这种方式。这种方式优点在于一方面简化统一技术栈、第二则利用平台能力(如高可用、易管理等)做到比直接使用单机库更好的效果。这种方式多见于分库分表类型的分布式数据库,因其底层是依托于独立的单机数据库引擎构建,因而相对容易。另一种方式“租户”模式,则多见于资源整合类需求,用户将原来直接使用大量单机数据库,转而通过分布式数据库提供的租户来承载。其业务可采用分片、也可采用单机。这种方式优点在于同样一方面可以简化统一技术栈,第二则更多是为了更好的利用资源,通过租户的形式来整合底层资源。当然上述两种能力,也存在一定的弊端,主要表现在资源有效利用率(分布式架构多少存在一些冗余)、管理灵活性(统一方式管理所带来的)、可靠性(集群内的单点故障蔓延)、可用性(受限于平台整体可用性)、扩展性(是否能做到真正的一体化)等等。
2).多角度架构对比
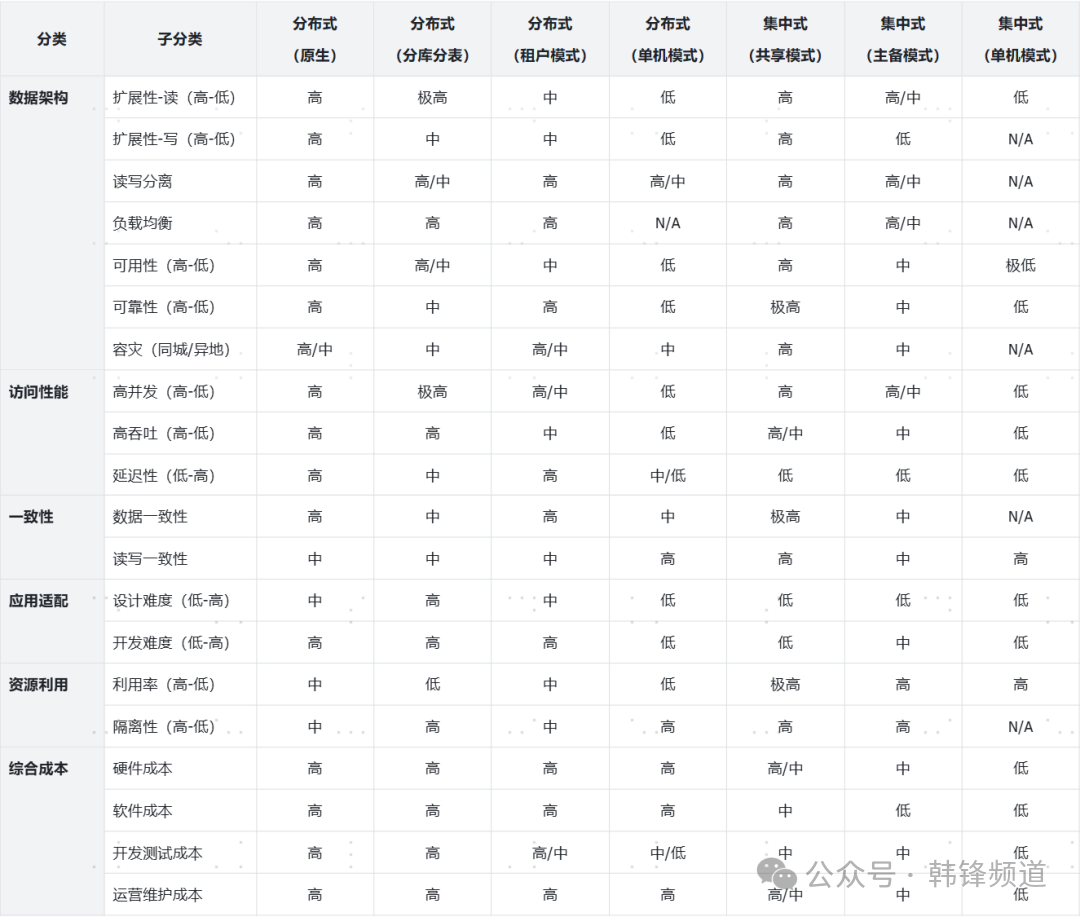
下文将从多角度对比各种数据库主流架构。这其中选择原生分布式、分库分表类型的分布式,默认这两者都采用数据分片的通常用法;另外选择分布式的两种新用法,租户模式和单机模式。集中式方面,选择了典型的三种架构,共享存储模式(类似Oracle RAC)、主备模式(类似Oracle DG)和单机模式。
 1.png
1.png
架构层面
在架构层面,分布式在扩展性天然具备一定优势,当然针对绝大多数企业及场景来看,集中式共享模式提供的Scale Up能力,已经是可以满足的了。之前国内这种方案较少,大多还是主备,近两年部分厂商开始发力。在可用性、可靠性、容灾等方面,分布式具备的计算层无状态、存储层多副本架构等技术特点,成为可靠的保障。从我的观察来看,很多国内用户选择分布式数据库,很多往往不是因为计算、存储的规模问题,而是考虑了可用性问题。出于对国产数据库的各种不放心,天然会考虑通过分布式能解决一定问题。这有一定道理,但是这其实也是一柄双刃剑,分布式架构的复杂度也带来对可用性的挑战。其实经典的 IOE 架构,是之前企业的普遍选择,大部分核心业务系统是构建于此,只不过国产数据库此类架构发展较晚,大家还处于观望状态。
性能层面
在性能层面,分布式同样具备一定的优势,可通过水平扩展计算节点来解决高并发、高吞吐的问题。这一点集中式之前方案不多,虽然单节点的处理能力已经达到上百万的TPMC,但是在极端场景下还是有所欠缺。共享存储的架构是另一种思路,可在一定程度上解决传统集中式架构的性能短板。之前有一点容易被忽略的是关于时延问题,分布式架构在这点上往往表现不佳,这主要是因为其层次多、路径长所导致的,这一点集中式架构是有一定优势的。
一致性层面
在一致性方面分两点,一是数据一致性,即多个数据副本是否保障的实时一致性;一是读写一致性,可理解为读取的是否为最新版本的数据。这方面主要是数据副本的复制机制、复制粒度有关,强一致会带来不错的一致性表现,但对性能的影响也是巨大的。其实最好的一致性是数据不复制,对单一副本进行读写,集中式的共享存储模式就是这种,严格意义来讲也不是数据不复制,只不过数据副本的构建是在更低层次(存储)上解决了。
应用适配性
在应用适配难度上,分布式的劣势就很明显了,其在架构设计、语句开发等方面不可避免地需要考虑分布式的特点。当然很多分布式厂商也都在解决这一问题,希望通过类似“透明分布式”的做法来屏蔽这一难点。但目前看来只能说在一定程度上可以解决,尚无法达到同集中式同等的设计、开发适配能力,毕竟过去几十年来研发人员已经习惯在集中式数据库上的设计开发了。此外,针对库内计算的问题则差异更大,这也是大家这些年都纷纷采用降低数据库计算要求,这其实也是无奈之举,但同时其背后的压力与成本付出则是更多人看不到的。
资源利用
在资源利用方面,分布式所需组件多、资源消耗大,是很多人所诟病的,这是其架构决定的。约一体化的架构对资源的使用效率越高,这一点集中式有一定优势。在隔离性方面,同样如此,较为清晰的资源调用路径有利于提升隔离性,避免因资源消耗过大导致的异常蔓延问题。
综合成本
最后的成本问题则来自多个方面,这包括了硬件、软件采购及与之相配套的开发测试与运营维护成本。这一点分布式具有的新架构、节点组件多、资源需求多、开发适配投入大、管理维护复杂等问题是存在的,这也在一定程度造成分布式推广难点,因而可见近年来很多分布式企业提供的单机一体化能力,就是为了在一定程度上减低部分成本。很多用户可能会有感觉,上了分布式后,比之前集中式的 IOE 架构还要贵,这点也为国产集中式架构产品带来一定启发,做出更具性价比的产品。
2. 典型业务场景分析
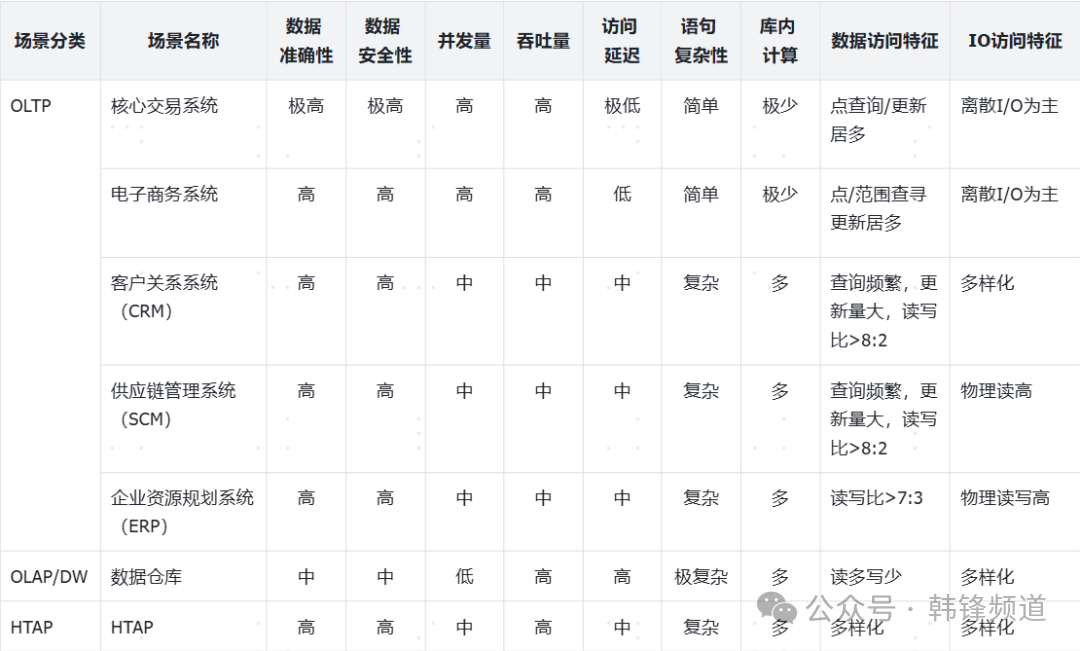
上面谈到了数据库主流用法,那么用户又该如何去选呢?一方面可以参考表格内容做好自有业务分析,一方面也可以参考行业一些通用做法。这里引用来自白鳝老师近期发表的一篇文章,其中对主流业务场景做了抽象。这里将下面场景逐一分析,看用什么架构适配会更为合适。
1).典型业务场景回顾
 2.png
2.png
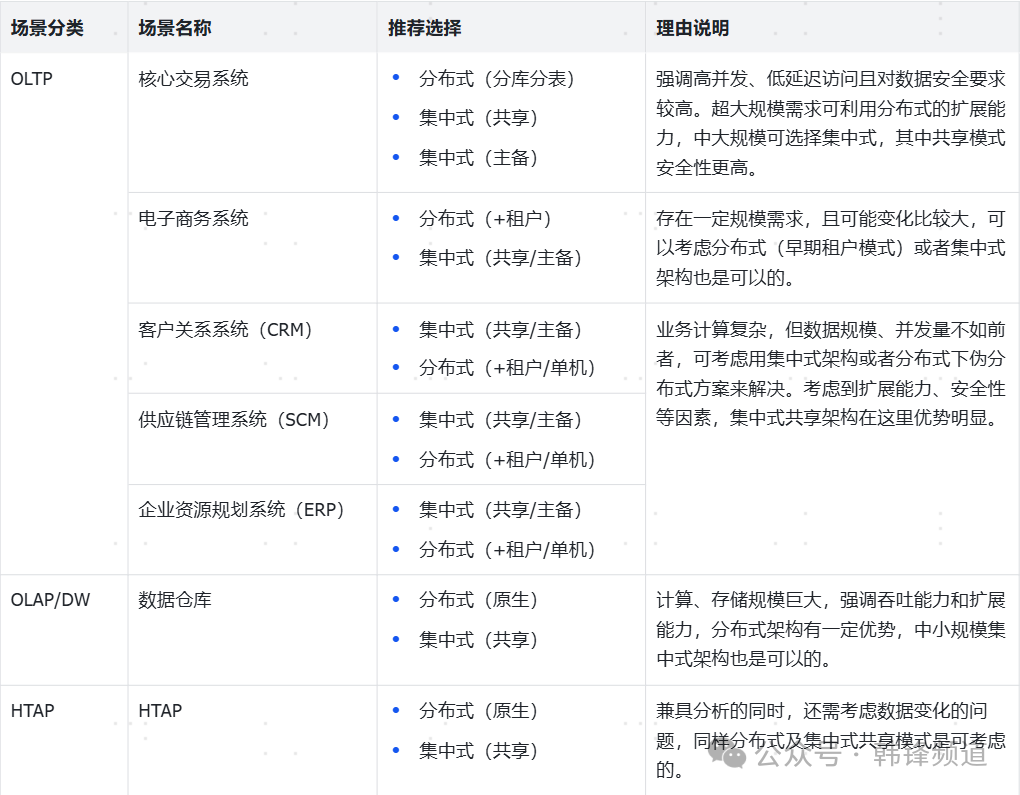
2).可适配的最佳架构
下面从不同架构特点及场景需求出发,做两两匹配,看何种架构会更为合适些。
 3.png
3.png









