


图解 MySQL 日志体系:让你明明白白记住各种 Log
面试官:MySQL的日志系统了解吗?
我:MySQL有binlog、redo log...
面试官:那它们分别解决什么问题?为什么需要这么多种日志?
我:这个...(尴尬)
相信这样的对话很多同学都经历过。大家都知道MySQL有各种日志,但要说清楚它们的作用和关系,往往就不那么容易了。
作为一名有着7年MySQL开发经验的老兵,今天我用最通俗的语言,帮你彻底理解MySQL日志体系。

一、为什么MySQL需要日志系统?
让我们从一个最基础的数据库操作说起:
// 用户消费100元
UPDATE account SET balance = balance - 100 WHERE id = 1;这条简单的SQL语句,实际上给数据库带来了三大挑战:
- 可靠性问题:如果数据库突然宕机,这笔交易记录会不会丢失?
- 一致性问题:如果用户要求退款,如何安全地回滚这笔交易?
- 同步问题:如何确保其他数据库节点也正确记录了这笔交易?
为解决这些问题,MySQL设计了三种核心日志:
数据库操作 ──────────────────┐
↓
┌─── Redo Log(临时记事本)
│ 记录:"账户1减少100元"
│ 作用:确保交易记录不丢失
│
├─── Undo Log(原始凭证)
│ 记录:"账户1原有500元"
│ 作用:随时可以撤销交易
│
└─── Binlog(总账本)
记录:"完整交易记录"
作用:用于数据同步和备份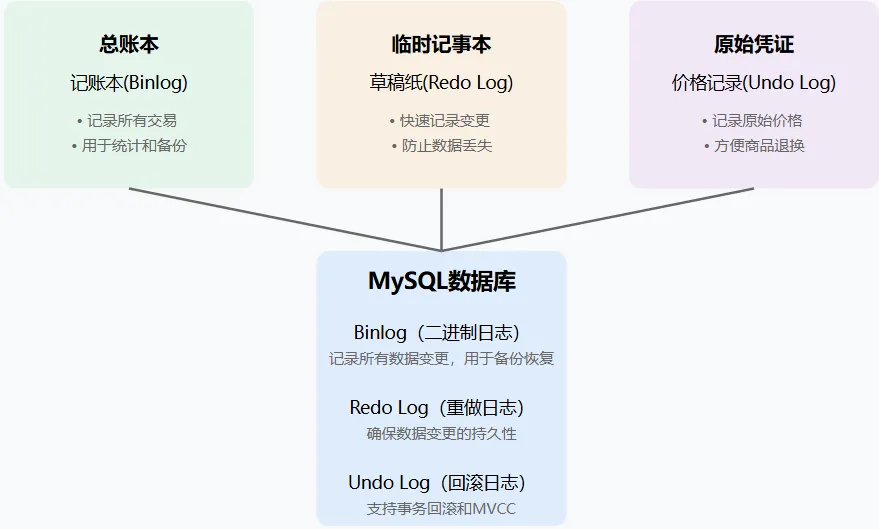
二、重做日志(Redo Log):数据库的"草稿纸"
1. 场景:会计小徐的烦恼
超市收银员小徐要记录1000笔交易。
传统方式(没有Redo Log):
-- 每笔交易都要立即写入硬盘
UPDATE accounts SET balance = balance + 100;
UPDATE products SET stock = stock - 1;
结果:
┌─────────────────────┐
│ ❌ 频繁随机写入硬盘 │
│ ❌ I/O效率极低 │
│ ❌ 系统性能下降 │
└─────────────────────┘Redo Log的解决方案:
1. 先写入速记本(Redo Log)
┌────────────────────┐
│ 交易1: +100元,-1件 │
│ 交易2: +200元,-2件 │ ➜ 顺序写入,速度快
│ ... │
└────────────────────┘
2. 数据先放内存
┌────────────────┐
│ 内存中快速汇总 │ ➜ 响应迅速
└────────────────┘
3. 定期整理同步
┌────────────────┐
│ 批量写入硬盘 │ ➜ 提高效率
└────────────────┘2. Redo Log工作原理详解
以顾客购买2箱牛奶为例:
// 顾客买了2箱牛奶(每箱100元)
UPDATE accounts SET balance = balance + 200;
UPDATE stock SET quantity = quantity - 2;步骤1:速记本记录(Redo Log)
在Redo Log中记录交易信息:
交易编号 | 时间 | 操作类型 | 表名 | 修改内容 | 状态 |
001 | 09:01:01 | UPDATE | accounts | 账户余额+200 | 已记录 |
002 | 09:01:01 | UPDATE | stock | 牛奶库存-2 | 已记录 |
特点:
- 顺序写入:像流水账,效率高
- 记录简单:快速记录交易信息
步骤2:临时汇总(内存)
在内存中快速更新数据:
账户 | 余额 |
现金 | 1200 |
商品 | 库存数量 |
牛奶 | 98 |
特点:
- 快速更新:客户立即看到结果
- 数据在内存中:但断电会丢失
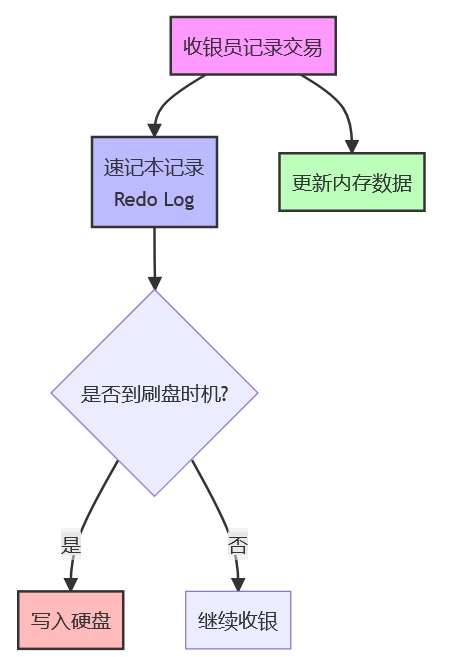
步骤3:持久化阶段,定期刷盘
在以下时机将数据写入硬盘:
- 营业员交接班时
- 系统空闲时
- 速记本快写满时
- 固定时间间隔
Redo Log 工作流程图:
三、回滚日志(Undo Log):数据库的"后悔药"
1. 场景:超市的退货处理
传统退货方式(没有Undo Log):
顾客:我要退刚买的牛奶
小徐:抱歉,我们没记录原价,不知道该退多少钱...
现代方式(使用Undo Log)
顾客:我要退刚买的牛奶
小徐:好的,让我查看下交易记录
- 找到原始购买记录
- 确认购买价格是100元
- 确认库存状态
- 可以安全退货
2. Undo Log 工作原理详解
场景:用户下单扣款
// 顾客购买2箱牛奶
UPDATE accounts SET balance = balance + 200; // 收款200元
UPDATE stock SET quantity = quantity - 2; // 库存减2交易记录阶段(Undo Log记录)
编号 | 时间 | 表名 | 修改前数据 | 修改后数据 | 回滚指针 |
T001 | 09:01:01 | accounts | balance=1000 | balance=1200 | -> T000 |
T002 | 09:01:01 | stock | quantity=100 | quantity=98 | -> T001 |
T003 | 09:05:30 | accounts | balance=1200 | balance=1000 | -> T002 |
T004 | 09:05:30 | stock | quantity=98 | quantity=100 | -> T003 |
数据版本链(MVCC实现):
牛奶库存记录的版本链:
+-------------------------+
| 当前版本:98箱 |
| 交易号:T002 |
+-------------------------+
↓
+-------------------------+
| 上一版本:100箱 |
| 交易号:T001 |
+-------------------------+
↓
+-------------------------+
| 初始版本:100箱 |
| 交易号:T000 |
+-------------------------+Undo Log 工作流程图:
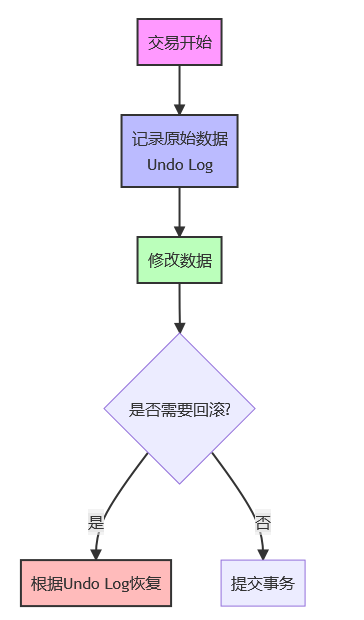
3. Undo Log的两大作用
(1) 支持事务回滚
- 记录数据修改前的状态
- 支持出错时回滚
- 保证事务原子性
(2) 实现MVCC(多版本并发控制)
- 不同事务看到不同版本的数据
- 提高并发性能
- 避免加锁带来的性能问题
四、二进制日志(binlog):数据库的"保险箱"
1. 场景:连锁超市的账务管理
小徐是连锁超市的总经理,每天要处理这些数据管理问题:
场景一:商品管理
总店:上架100种新商品
┌─────────────────┐
│ 商品1: 牛奶 │
│ 商品2: 面包 │ ➜ 分店:一个个手动添加?
│ ...100条记录... │
└─────────────────┘
场景二:数据安全
┌─────────────────┐
│ 昨日销售数据 │ ➜ 系统崩溃,数据丢失!
└─────────────────┘
场景三:变更追踪
老板:这个商品谁改的价格?
小徐:¯_(ツ)_/¯ 不知道...而有了Binlog(二进制日志)后:
MySQL Binlog
├── 自动同步
│ 总店改价格 ──➜ 所有分店秒级更新
│
├── 数据保护
│ 系统崩溃 ──➜ 从日志恢复数据
│
└── 操作追踪
谁改了价格?──➜ 查看变更历史2. Binlog的记录格式:如何记录数据变更?
让我们看看Binlog是如何记录数据变更的:
-- 一笔简单的商品价格调整
UPDATE products SET price = 98 WHERE name = '牛奶';这条SQL语句在Binlog中有三种不同的记录方式:
(1) STATEMENT格式:记录SQL语句
# 直接记录SQL
UPDATE products SET price = price * 0.9
WHERE category = '饮品';
优势:日志量小
风险:可能导致主从不一致(比如NOW()函数)(2) ROW格式:记录数据变化
{
"before": {"id": 1, "name": "牛奶", "price": 100},
"after": {"id": 1, "name": "牛奶", "price": 90}
}
优势:数据准确
特点:日志量较大(3) MIXED格式:智能选择
# 根据SQL类型自动选择格式
简单UPDATE:使用STATEMENT
复杂函数:使用ROW五、三大日志协同工作机制
以顾客购买2箱牛奶为例,操作内容如下:
- 更新库存(-2箱)
- 更新账户(+200元)
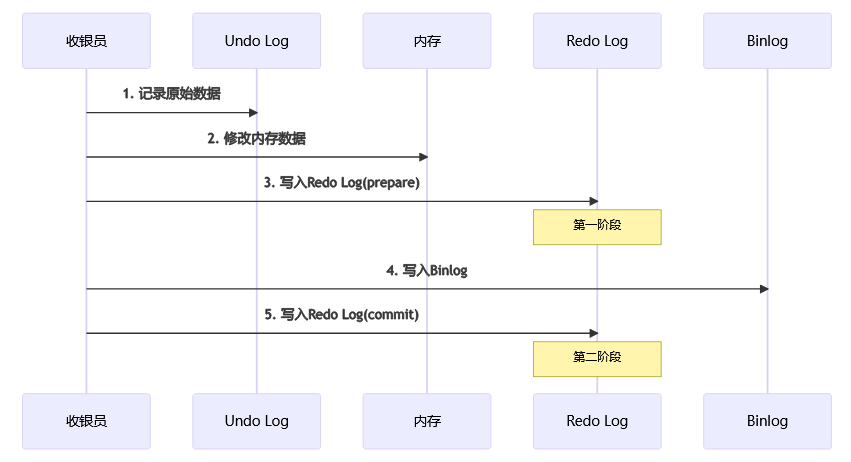
1. 两阶段提交工作流程
(1) 第一阶段(Prepare):
记录原始数据(Undo Log):
- 库存:100箱
- 账户:1000元
更新内存数据:
- 库存:98箱
- 账户:1200元
记录操作状态(Redo Log):
- 状态:准备中
- 内容:库存-2,账户+200
(2) 第二阶段(Commit):
记录交易信息(Binlog):
- 时间:2025-04-14 09:00:00
- 操作:售出牛奶2箱,收款200元
标记操作完成(Redo Log):
- 状态:已完成
详细的执行流程表:
步骤 | 操作 | 日志类型 | 内容 | 状态 |
1 | 记录原数据 | Undo Log | 库存=100,余额=1000 | 已记录 |
2 | 更新内存 | Buffer Pool | 库存=98,余额=1200 | 已更新 |
3 | 预提交 | Redo Log | 更新操作记录 | prepare |
4 | 记录变更 | Binlog | 交易详细信息 | 已写入 |
5 | 最终提交 | Redo Log | 更新操作记录 | commit |
两阶段提交流程图:
六、总结
通过本文,我们深入了解了MySQL日志系统的核心内容:
三大日志的作用与原理:
- Redo Log:确保数据持久性,像草稿纸,记录每一步操作。
- Undo Log:支持事务回滚,类似价格标签,随时可以撤销错误。
- Binlog:用于数据复制和恢复,犹如记账本,记录所有交易历史。
在数据库的世界里,日志不仅是记录,更是保障数据安全与一致性的基石。希望这些内容能帮助你更深入地理解MySQL日志系统的关键作用!









