


面试官:什么是 Next-Key Lock?作用是什么?
Next-Key Lock 是 InnoDB 存储引擎中非常基础也是非常重要的一个锁。今天来聊一聊 Next-Key Lock。
首先我们回顾一下 MySQL 的事务隔离级别。
- 串行化(Serializable):事务对数据读写都是串行的。
- 可重复读(Repeatable Read):事务执行过程中,多次读取同一行数据,读取结果一致。MySQL 默认隔离级别就是可重复读。
- 读已提交数据(Read Committed):事务执行过程中,如果有其他事务修改了数据并且提交事务,当前事务可以读取到最新提交的数据。
- 读未提交数据(Read Uncommitted):事务执行过程中,可以读取到其他事务未提交的数据。
可重复读隔离级别解决了幻读问题,而解决的方式就是通过 MVCC 和 Next-Key Lock。
幻读:同一事务内多次查询同一范围内的数据,因其他事务插入或删除符合条件的数据,导致事务在后面读取到的结果集不一样,像产生了幻觉。
介绍
Next-Key Lock 是间隙锁(gap lock)和行锁(index-record lock)的组合。
- 行锁: 锁定索引中的某一条具体记录。
- 间隙锁: 锁定索引记录之间的间隙,它锁定的是一个范围,这个范围内不存在数据。例如,如果锁定了 (10, 20) 这个范围,那其他事务就不能在这个范围内插入新记录。
一个 Next-Key Lock,也就是行锁加上该行之前的间隙锁,因此,它锁定的是一个前开后闭区间。
我们假设有一张表 t,包含(id,a,b)3 个字段,其中 id 是主键,字段 a 上面有普通索引,字段 b 没有索引。建表语句如下:
CREATE TABLE `t` (
`id` int(10) NOT NULL,
`a` int(10) DEFAULT NULL,
`b` int(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)) ENGINE=InnoDB;表中有 4 条记录,分别(5,5,5),(10,10,10),(15,15,15),(20,20,20),那如果执行下面语句:
select * from t where id = 7 for update;这样会对 id= 10 的记录加 Next-Key Lock,锁定的是 (5, 10] 这个区间,也就是说,除了锁住 id = 10 这条记录(行锁),同时间隙锁锁住了 5 和 10 之间的间隙(5,10)。
而如果执行下面这条 SQL,则会对整张表加 Next-Key Lock,因为字段 c 没有索引,新插入的数据都可能包含 c = 6。加锁后,形成 5 个范围:
select * from t where c = 6 for update;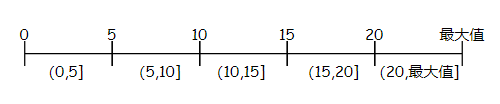 图片
图片
加上了 Next-Key Lock,可以阻止其他事务在被锁定的间隙中插入新的记录,从而保证了当前事务中多次执行相同查询时,不会有新的记录查出来,解决了幻读问题。
在可重复隔离级别下,执行下面几个 SQL 时,都可能会对扫描过程中访问到的记录加 Next-Key Lock:
SELECT * from t where id =xxx FOR UPDATE;//id 不存在
SELECT * from t where a =xxx FOR UPDATE;
SELECT * from t where b =xxx FOR UPDATE;
SELECT * from t where id BETWEEN 10 AND 20;
SELECT * from t where id =xxx LOCK IN SHAREMODE;
UPDATE t set b = xxx where id = yyy;
DELETE from t where id = yyy;非唯一索引和无索引的字段,都可能会匹配多条记录,所以会加 Next-Key Lock。
那如果查询的 id 存在,还会加 Next-Key Lock 吗? 比如上面的表,执行 SQL:
SELECT * from t where id = 10 for update;答案是不会加 Next-Key Lock,这个时候 Next-Key Lock 退化成了行锁。
查询语句符合下面三个条件时,Next-Key Lock 会退化成行锁:
- 查询使用的是唯一索引;
- SQL 条件是等值匹配(比如 WHERE unique_key = X);
- 扫描到的记录确定存在。
如果上面 3 个条件有一个不符合 ,都会加 Next-Key Lock。
另一点,虽然 Next-Key Lock 是前开后闭区间,如果索引上等值查询向右遍历到最后一个值不满足等值条件,则退化为间隙锁。比如执行下面 SQL:
SELECT * from t where id = 8 for update;Next-Key Lock 退化为间隙锁,加锁范围是(5,10)。id = 10 的这条记录不影响其他事务修改操作。
优缺点
优点:解决了 REPEATABLE READ 隔离级别下幻读问题,有效保证了数据一致性。
缺点: 增加了锁的粒度,一定情况下会降低并发性能,并增加死锁发生的概率。因为多个事务可能以不同的顺序请求对重叠的间隙加锁,很容易造成死锁。
下面是一个死锁的案例,事务 A 准备插入一条(8,8,8)的记录,事务 B 准备插入一条(9,9,9)的记录,其他他们相互不影响,但加了 Next-Key Lock,就容易造成死锁。
事务 A | 事务 B |
select * from t where id = 8 for update; | |
select * from t where id = 9 for update; | |
insert into t values(9,9,9); | |
insert into t values(8,8,8); |
这样两个事务都会加(5,10)这个间隙锁,最终相互等待,形成死锁。
为什么两个事务都可以加上间隙锁,因为间隙锁之间不会冲突。
总结
Next-Key Lock 是 InnoDB 引擎行锁加间隙锁的组合,它锁住的是一个前开后闭的区间,消除了 REPEATABLE READ 隔离级别下的幻读问题。理解 Next-Key Lock 要把握两点:
- 可重复隔离级别下才会生效;
- 锁住一个前开后闭的区间,但一定条件下可能退化成行锁或者间隙锁。









