


面试官:count(*)、count1(1)、count(主键)、count(字段) 哪个更快?
大家好,我是君哥。
使用 SQL 时,统计表数据量是经常遇到的需求,比如在商品页面展示商品库存量。
统计表数据量的方法有 count(*)、count1(1)、count(主键 id)、count(字段)。那这些统计方式哪个执行最快呢?以 MySQL 数据库为参考,今天来聊一聊这个话题。
count(*)
首先 ,count(*) 返回的是检索到的行数,无论数据行里是否包含空值。
如果使用的是 MyISAM 存储引擎,MyISAM 会把表的数据行数保存下来存到磁盘,因此执行 count(*) 的时候不用统计,而是直接把保存的结果查出来,效率最高。但这有几个前提条件:
- 不能带 where 条件;
- 只能从单表查询;
- 查询 SQL 不能有额外的字段;
- MyISAM 不支持事务,可能会有数据不一致的情况。
如果使用的是 InnoDB 存储引擎,count 就是一个聚合函数,对返回的结果集逐行进行判断,只要不是 NULL 就加 1,效率不如 MyISAM。当然,MySQL 对 count(*) 做了优化,会选择数据量最小的二级索引进行扫描,以提高执行效率。
count(1)
对于 count(1) 来说,InnoDB 引擎遍历整张表,server 层对于返回的每一行,不用取值,直接放一个数值 1 进去,然后计数值加 1。
count(主键 id)
对于 count(主键 id) ,InnoDB 引擎会遍历整张表,把每一行的 id 值取出来,返回给 server 层。server 层拿到 id 后,判断主键 id 不可能为空,计数值加 1。
count(字段)
对于 count(字段) 来说:如果字段定义成 not null,server 层逐行判断,只要引擎层返回的记录不为空,计数值加 1;如果这个字段定义成 null,那server 层拿到记录后,还需要取出值判断是不是 null,如果值不是 null,计数值加 1。
小结
对于 InnoDB 引擎来说,使用 count(*) 和 count(1) 是一样的,没有性能区别。下面是官网解释。
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
count(*) 比 count(主键 id) 快,因为执行 count(主键 id) 的时候,引擎层需要解析主键 id 的值返回给 server 层。
count(字段) 性能最差,因为引擎层解析字段值返回给 server 层后,server 层需要从行记录取出值进行判断是否为 NULL。
缓存
那有更快的方案查询表数据量吗?有。可以考虑使用 redis 缓存来。在 redis 中建 一个 key 来保存数据量,当表插入新数据时,缓存数据量 + 1。
但使用缓存可能会有两个问题:
- 会有数据不一致得情况,不适用于精确统计的场景;
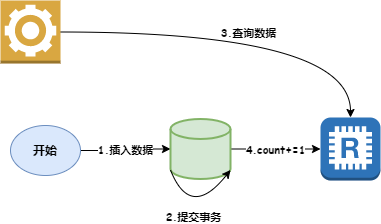
比如上图,插入数据后,还没有来得及更新缓存,已经有应用查询了缓存的 count 值。
可以考虑把缓存的 count 值写入 MySQL 数据库,使用 InnoDB 引擎的事务来保证一致性。
2. redis 服务宕机后,会丢失数据。这个可以在 redis 重启后重新从数据库查询最新 count 数来写入缓存。
总结
- 如果数据量不大,比如不到百万级别,或者对 count 值精确度要求很高,可以直接使用 count(*) 获取行数。
- 如果数据量非常大,查询频率也很高,可以考虑缓存 count 值;
- 如果考虑使用缓存,但业务又要求 count 值精确,那就把 count 值缓存在数据库中;
- 如果对 count 精确度要求不高,可以考虑把 count 值缓存在 redis;
- 如果要统计某一个字段非空的行数,则使用 count(字段);
- 如果是分库分表的场景,则采用并行统计来提高效率。
本文地址:https://www.yitenyun.com/333.html









