


MySQL默认数据库隔离级别为什么是RR?而互联网大厂为什么把它修改为RC?
前言
大家好,我是田螺。
大家都知道mysql的默认数据库隔离级别嘛? 是的,就是RR,但是呢,为什么阿里这些互联网大厂,把mysql的数据隔离级别设置为RC呢?
本文田螺哥,按自己的回答思路,跟大家聊聊~
- RR和RC的区别
- mysql的主从复制
- binlog 日志的三种格式
- mysql的默认数据库隔离级别为什么是RR
- 互联网大厂为什么把隔离级别设置为RC
1. RR和RC的区别
大家应该都记得mysql数据库的四种隔离级别吧。
- RC,也就是读已提交,当前事务只能读取到其他事务提交的数据,所以这种事务的隔离级别解决了脏读问题,但还是会存在重复读、幻读问题。
- RR,可重复读隔离级别,在一个事务执行期间,无论其他事务如何修改数据,只要本事务未结束,多次读取同一数据集都会获得与事务开始时一致的结果。它解决了不可重复读的问题,但是还是可能存在幻读~~
RR隔离级别,会设置了间隙锁(Gap Lock和 Next-Key Lock),为了尽可能减少幻读。但是特殊场景还是会存在幻读的。
我归纳了它们的主要区别:
RC | RR | |
数据可见性 | 可能出现不可重复读 | 解决了不可重复读问题 |
锁机制 | 仅加行锁,无间隙锁,临键锁退化为行锁 | 过行锁 + 间隙锁 + 临键锁组合控制 |
是否存在幻读 | 存在 | 尽可能解决,特殊情况也存在 |
性能 | 并发性能更高,锁冲突少 | 一致性更强但锁开销大 |
适合场景 | 如电商秒杀 | 适合金融、库存等核心业务 |
2. mysql的主从复制
在这里先跟大家一起复习一下mysql的主从复制。因为mysql的默认数据库隔离级别,跟主从复制有关系的
主从复制原理,简言之,分三步曲进行:
- 主数据库有个binlog二进制文件,记录了所有增删改SQL语句。(binlog线程)
- 从数据库把主数据库的binlog文件的SQL 语句复制到自己的中继日志 relay log(io线程)
- 从数据库的relay log重做日志文件,再执行一次这些sql语句。(Sql执行线程)
详细的主从复制过程如图:
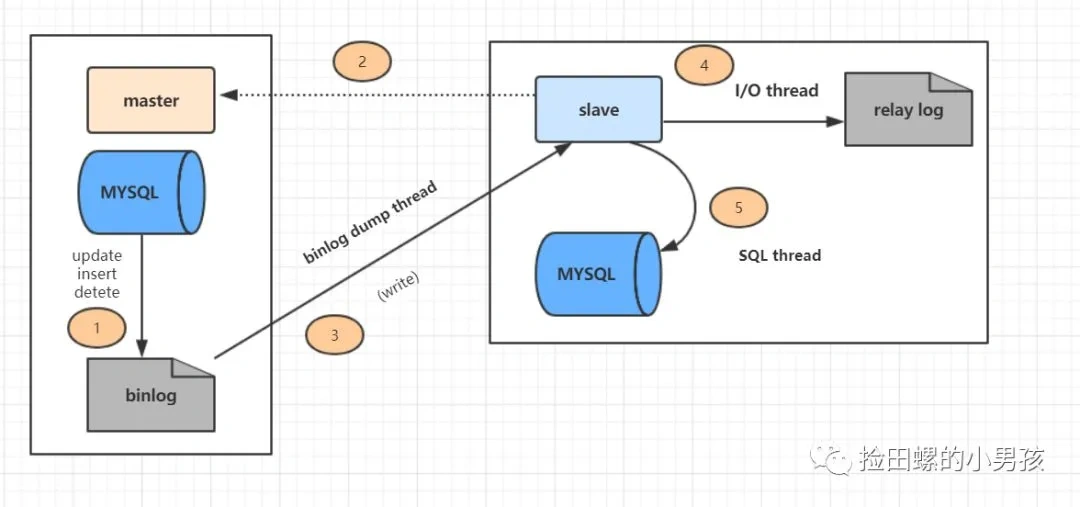 图片
图片
上图主从复制过程分了五个步骤进行:
- 主库的更新SQL(update、insert、delete)被写到binlog
- 从库发起连接,连接到主库。
- 此时主库创建一个binlog dump thread,把bin log的内容发送到从库。
- 从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
- 从库还会创建一个SQL线程,从relay log里面读取内容,从ExecMasterLog_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
3. binlog日志三种格式
我们再来复习一下binlog日志的三种格式
- Statement:基于SQL语句的复制((statement-based replication,SBR))
- Row:基于行的复制。(row-based replication,RBR)
- Mixed:混合模式复制。(mixed-based replication,MBR)
3.1 Statement格式
每一条会修改数据的sql都会记录在binlog中
- 优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。
- 缺点:由于记录的只是执行语句,为了这些语句能在备库上正确运行,还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在备库得到和在主库端执行时候相同的结果。
3.2 Row格式
不记录sql语句上下文相关信息,仅保存哪条记录被修改。
- 优点:binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。
- 缺点:可能会产生大量的日志内容。
3.3 Mixed格式
实际上就是Statement与Row的结合。一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式
4. mysql的默认数据库隔离级别为什么是RR?
MySQL早期,只有statement这种binlog格式。如果mysql的数据库隔离级别设置为RC,在某些场景下,可能数据不一致。
比如,假设有表结构:
-- 创建测试表
CREATE TABLE accounts (
id INT PRIMARY KEY,
balance INT
);
-- 插入初始数据
INSERT INTO accounts (id, balance) VALUES
(1, 20),
(2, 10);然后在RC的隔离级别下,并发执行这两个事务:
时序 | 事务A | 事务B |
1 | begin; | |
2 | UPDATE accounts SET id=3 WHERE balance = 20; | |
3 | begin | |
4 | UPDATE accounts SET balance = 20 WHERE balance = 10; | |
5 | commit; | |
6 | commit; |
对于主数据库:
以上这个并发事务,执行完后,数据库记录会变为:(3,20)和(2,20)。
如果是对于从库: 因为有statement格式的binlog 日志,记录的是SQL原文,然后事务2的先提交,再执行事务1的。
于是事务2执行完,变为(1,20)和(2,20)。然后事务1执行后,变为(3,20)和(3,20)
其实这就导致数据库的主库和备库数据不一致啦~
因此,MySQL就把数据库的默认隔离级别设置成了Repetable Read(RR)。RR隔离级别下,是如何解决这个问题的呢,其实就是加了GAP锁(间隙锁)。
我们刚那个例子,在事务2执行的时候,因为事务1增加了GAP锁,就会导致事务执行被卡住,需要等事务1提交或者回滚后才能继续执行。
5. 阿里为什么把隔离级别设置为RC
其实,不仅是阿里,现在我们公司,数据库隔离级别吗,也是设置为RC,为什么互联网公司的数据库隔离级别都改为RC呢?
5.1 提升并发
其实就是为了提升访问速度。换几句话说,其实是,并发高的时候,因为
- RC隔离级别中,不需要Gap锁和Next-Key锁,只是对需要修改的记录加行锁。
- 而RR隔离级别中,是可能加Gap锁和Next-Key锁的,为了解决幻读问题。
正是因为这个间隙锁的存在,所以RR隔离级别增加了死锁的可能性,如果并发高,耗时就增加了。RR的隔离级别修改为RC隔离级别,并发上来时,整体的耗时是相对更少的。
5.2 修改为RC隔离级别,需要注意哪些问题?
如果修改为RC隔离级别,首先,就需要直面幻读问题啦。
其实也还好,因为很多时候的幻读问题,问题不大的,甚至可以忽略的。或者有时候,可以通过其他手段解决。
其次,设置为RC时,binlog的日志格式,不能设置为statement哈。其实吧,从MySQL是在5.1+版本开始,陆续支持row和mixed的格式啦~~
本文地址:https://www.yitenyun.com/335.html









