


MySQL内幕揭秘:探索MySQL调优指南,解锁MySQL的强大功能
1、MySQL大事记
 图片
图片
1994年:Michael Widenius和David Axmark创建了MySQL AB。1995年:MySQL从最初的beta版本发布,成为一款开源软件。1997年:MySQL发行版本3.21,并成为了第一个支持多个存储引擎的数据库管理系统。2000年:MySQL AB成立了美国分部,开始在美国市场推广MySQL。2003年:MySQL AB发行了版本4.0,包括一些新功能,如子查询、视图和存储过程等。2005年:Sun Microsystems收购了MySQL AB,MySQL开始进入商业化阶段。2008年:MySQL 5.1发布,引入了一些新的特性,如事件调度器和复制增量流等。2010年:Oracle收购Sun Microsystems,也就接管了MySQL。2012年:MySQL 5.6发布,带来了全文搜索、NoSQL接口和多线程复制等新特性。2013年:MySQL 5.7发布,加入了JSON数据类型、有效地调整排序缓存和更好的性能优化等。2018年:MySQL 8.0发布,提供窗口函数、变量范围和原生支持多种数据类型等新特性。
2、MySQL使用在哪些大平台或企业
1)谷歌:谷歌广泛使用MySQL作为其后端数据库,支持数百万个查询请求。
2)Facebook:Facebook在早期就采用了MySQL,并开发了InnoDB存储引擎,使MySQL能够处理更高级别的负载。
3)Twitter:Twitter在其基础架构中使用MySQL,以存储和处理海量的社交数据。
4)美团:美团是一个中国本土的O2O平台,使用MySQL来管理其订单、餐厅、优惠券等数据。
5)阿里巴巴:阿里巴巴也是MySQL的重要用户之一,它将MySQL用于淘宝、支付宝和阿里云等核心业务。
6)百度:百度广泛使用MySQL来管理其各种应用程序和服务,如搜索、地图、音乐等。
3、MySql调优
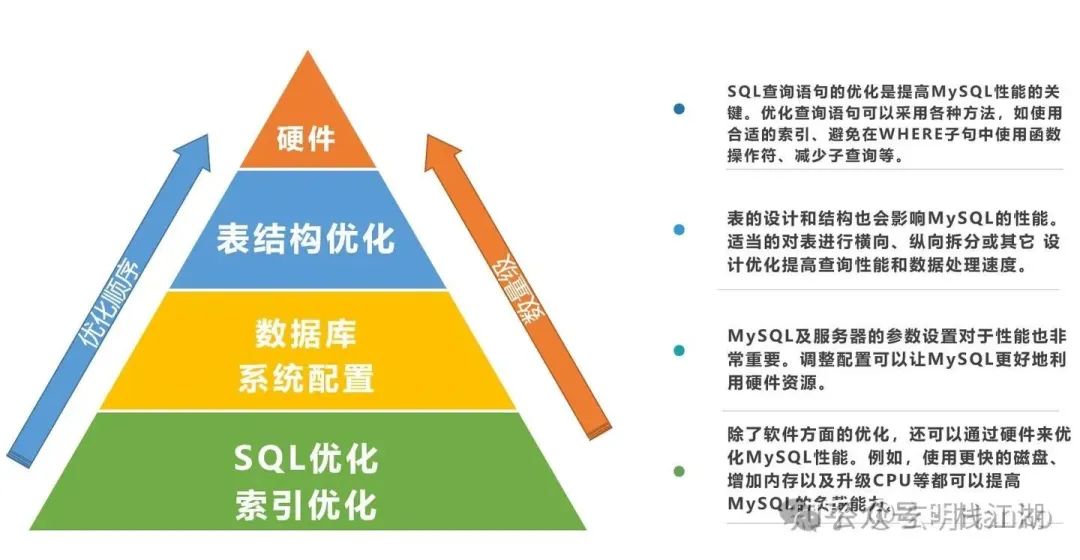
3.1、MySQL调优维度
 图片
图片
1)SQL及索引优化:SQL查询语句的优化是提高MySQL性能的关键。优化查询语句可以采用各种方法,如使用合适的索引、避免在WHERE子句中使用函数操作符、减少子查询等。
2)表结构优化:表的设计和结构也会影响MySQL的性能。适当的表设计可以提高查询性能和数据处理速度。例如,使用分区表可以加速查询,而垂直拆分表可以降低数据库的负载。
3)系统配置优化:MySQL及服务器的参数设置对于性能也非常重要。调整配置可以让MySQL更好地利用硬件资源。例如,增加缓存区大小、调整连接超时时间或者优化排序缓存等都可以提高系统性能。
4)硬件优化:除了软件方面的优化,还可以通过硬件来优化MySQL性能。例如,使用更快的磁盘、增加内存以及升级CPU等都可以提高MySQL的负载能力。
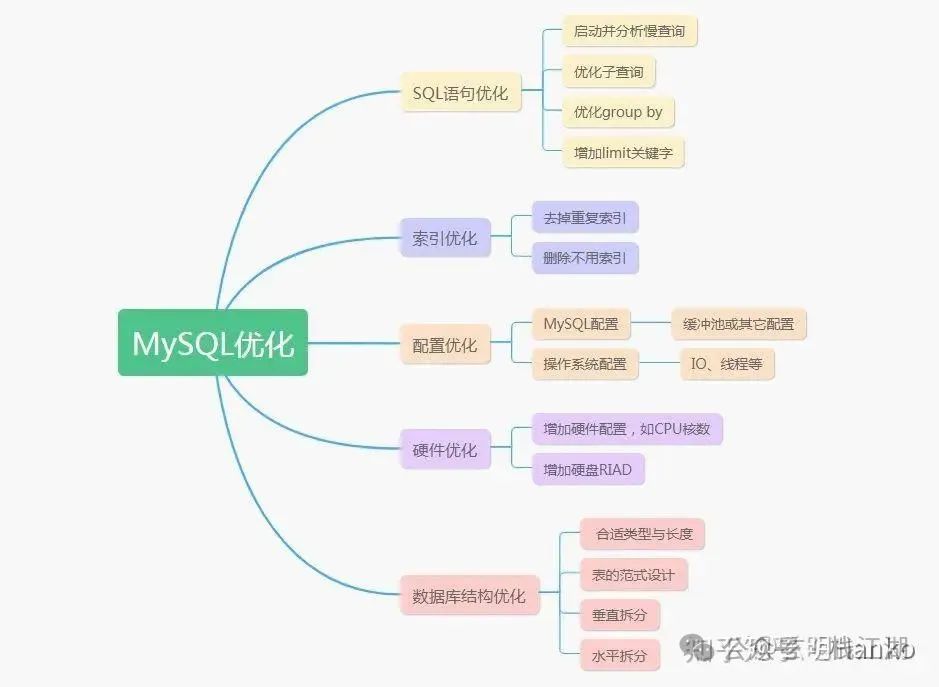
3.2、MySQL调优分解
 图片
图片
4、具体说明
4.1、SQL语句优化
- 开启慢查询功能
vim/etc/my.cnf
[mysqld]
slow-query-log=on# 开启慢查询功能
slow_query_log_file=/data/slow-query.log# 慢查询日志存放路径与名称
long_query_time=5# 查询时间超过5s的查询语句
log-queries-not-using-indexes=on# 列出没有使用索引的查询语句1)查看所有日志状态: show variables like '%quer%';
2)查看慢查询状态:show variables like 'show%'
- 分析SQL语句
MySql内部函数explain(查询sql的执行计划),explain返回各列的含义
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。
从最好到最差的连接类型为const、eq_reg、ref、range、index 和ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。
key:实际使用的索引。如果为NULL,则没有使用索引。
keyjen:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows: MySQL估算需要读取的行数rows: MySQL估算需要读取的行数
- 子查询优化
子查询尽量不用或改成join
- group by 优化
group by 尽量使用索引字段
- limit 优化
给查询语句增加limit
4.2、索引优化
- 重复索引
- 冗余索引
- 检查重复及冗余索引的工具
- 删除不用的索引
4.3、数据库结构优化
- 选择合适的数据类型
- 表的范式化
- 表的反范式化的使用
- 表的垂直拆分(列拆分)
- 表的水行拆分(行拆分)
4.4、配置优化
- 操作系统配置
1)缓存池大小
2)打开文件限制
- MySQL配置
1)innodb缓冲池内存占用大小
2)innodb_buffer_pool_instances 缓冲池个数
3)innodb_log_buffer_size 缓冲的大小
4)innodb IO配置
4.5、服务器硬件优化
- CPU 多核
- 硬盘 raid0 raid1 raid5增加硬盘IO速度
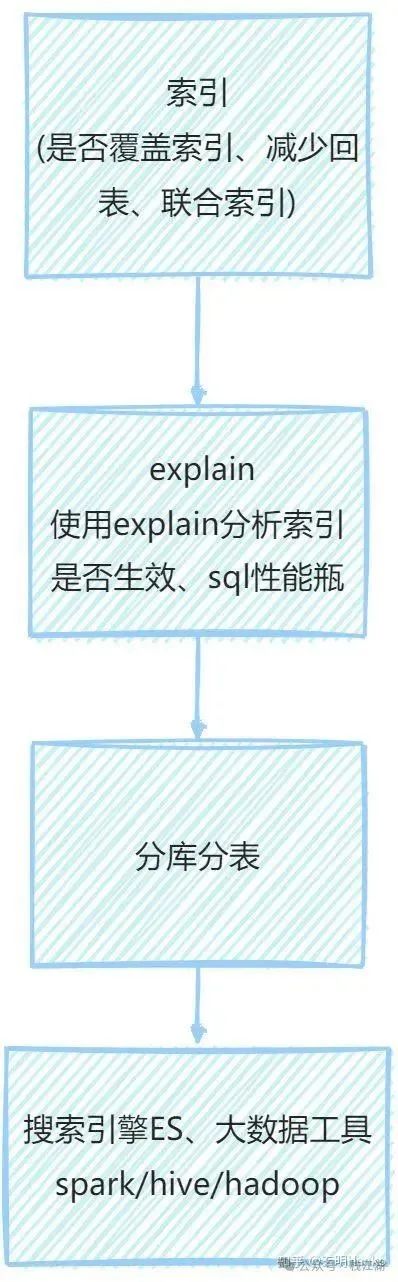
5、数据库调优步骤
 图片
图片
6、MySql相关问题
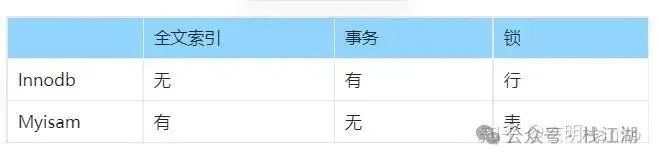
1)InnoDB myisam区别
- innodb支持事务、myisam不支持事务
- innodb不支持全文索引、myisam支持全文索引,查询性能较快
- innodb行级锁、myisam表级锁
2)怎么处理MySQL的慢查询?
开启慢查询->explain分析SQL->横纵向分表
3)Myisam和Innodb的区别?
 图片
图片
4)Mysql中索引类型有哪些?
- 普通索引:允许被索引的数据列包含重复的值
- 唯一索引:可以保证数据记录的唯一性
- 主键索引:是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯一标识一条记录,使用关键字primary key来创建
- 全文索引:通过建立倒排索引,可以极大的提升检索效率,解决判断字段是否包含的问题,是目前搜索引擎使用的一种关键技术索引可以极大地提高数据的查询速度
5)为什么用自增主键
数据库使用的是B+Tree,非自增会出现要插入到节点与节点中间,会发生节点分裂。
6)为什么用联合索引
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。









