


什么是写失效,如何解决写失效问题
写失效是指在Mysql数据页在写入磁盘的过程中由于系统宕机或其他原因导致数据页一部分部分写入成功,一部分写入失败,最终造成数据页损坏的情况。这种情况会导致数据丢失并且无法通过redo log恢复(redo log记录的是数据页的物理操作,而非完整数据页)。
1、为什么出现写失效问题
lnnoDB存储引擎中缓存页和操作系统的页大小不一致,lnnoDB页大小默认为16K(可以设置),操作系统页默认大小为4K,当InnoDB的页写入到磁盘时,一个页需要分4次写,如下图所示:
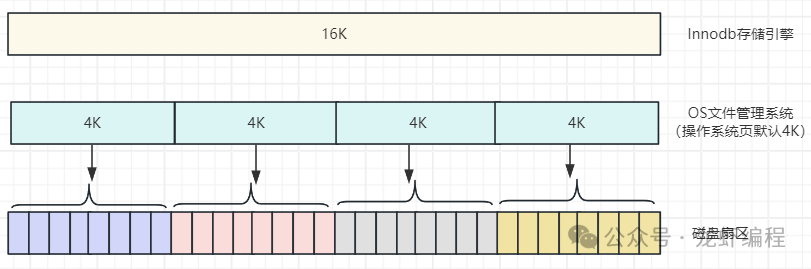 图片
图片
如果当存储引擎正在写入页的数据到磁盘时发生了宕机,可能出现页只写成功一部分的情况,如下图所示:
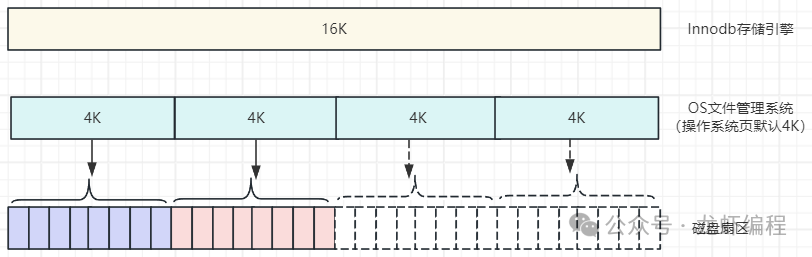 图片
图片
上图这种情况就做部分写失效,会导致数据丢失的问题。
2、Mysql如何解决写失效
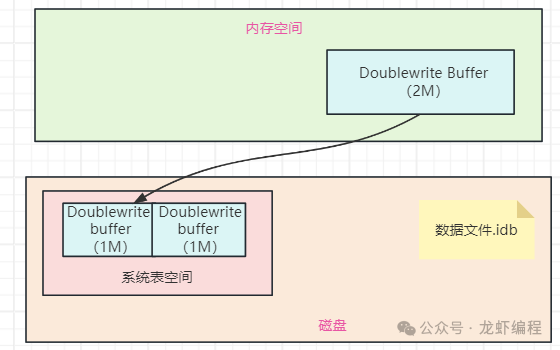
为了解决写失效问题,Mysql引入了双写缓冲区(Double Write Buffer,它是InnoDB存储引擎的一种机制,用于解决部分写失效的问题,提高数据完整性和可靠性),InnoDB存储引擎中,系统表空间的有双写缓冲区,如下图所示:
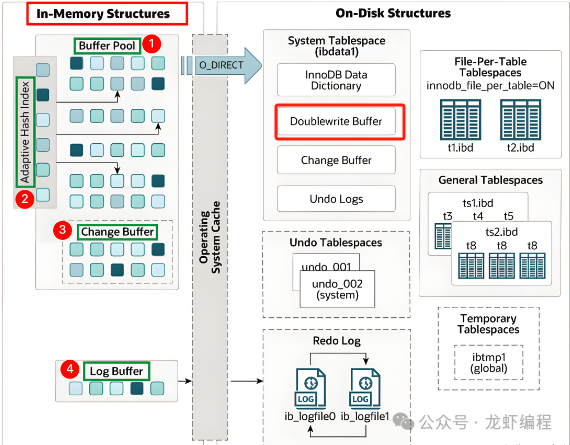 图片
图片
Doublewrite Buffer是内存+磁盘的结构,在内存结构中,Doublewrite Buffer由128个页构成,大小是2MB,这些页在内存中以Doublewrite Buffer的形式存在,如下图所示:
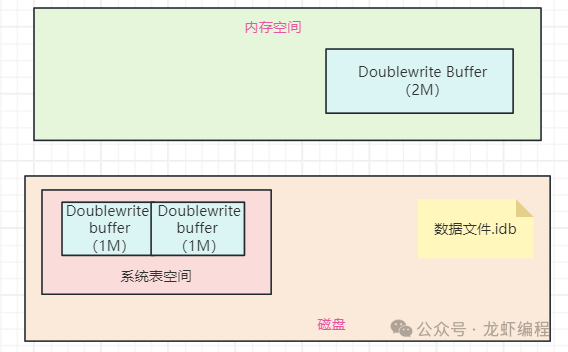 图片
图片
在磁盘结构中,Doublewrite Buffer在系统表空间上是128个页(2个区,每个大小是1M),总的大小是2M。
双写缓冲区的原理是双写缓冲区通过在数据页写入磁盘之前,先将数据页写入系统表空间中的Doublewrite buffer区域,确保即使在写入过程中发生宕机,也可以通过该临时区域恢复损坏的数据页,如下图所示:
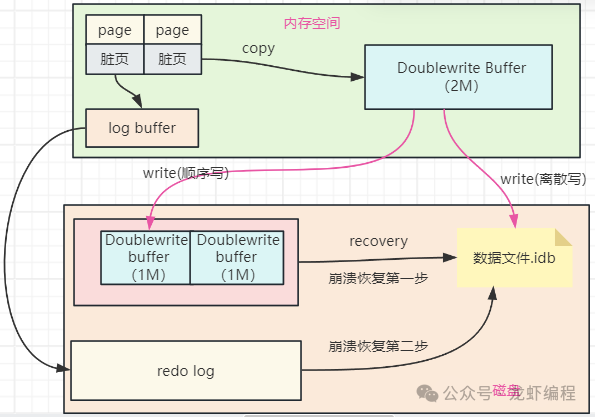 图片
图片
当有数据页(脏页)要被写入数据文件时,首先将页数据通过函数拷贝至内存中的Doublewrite buffer中,如下图所示:
 图片
图片
Doublewrite buffer每次写1MB数据到磁盘上的共享表空间上,在共享表空间中会单独开辟2M连续的空间专门给Doublewrite buffer刷脏页用,由于这个存储空间是连续的并且写入磁盘还是顺序写,所以数据页同步到系统表空间的性能很高,执行的速度也很快。
完成同步系统表空间后,Doublewrite buffer再将脏页写入实际的各个表空间文件中,这时写入就是离散的了,如下图所示:
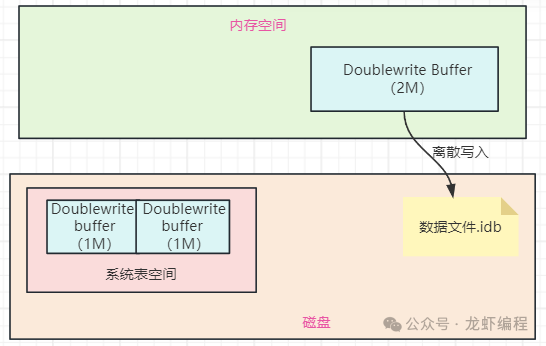 图片
图片
这个上述的过程中,第一次写入到系统表空间上,第二次写入实际的表空间中,这个过程涉及到两次写入,这过程我们称之为双写,完成的过程如下图所示:
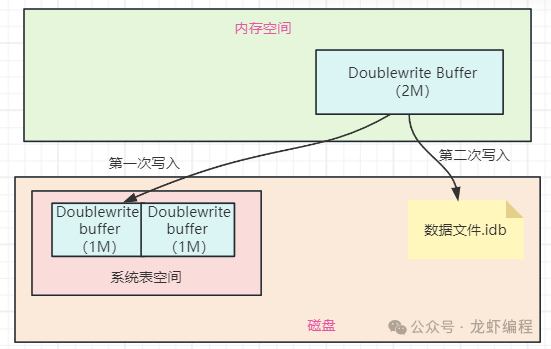 图片
图片
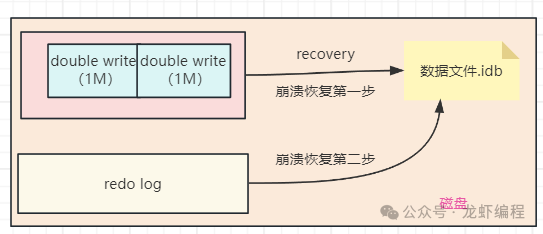
当Mysql刷脏页到磁盘上出现崩溃时,在系统崩溃恢复过程中,双写缓冲区的作用就出来了,如下图所示:
 图片
图片
如果数据页在写入过程中发生损坏,InnoDB存储引擎会从系统表空间中的双写缓冲区中查找该页的完整副本,并将其恢复到数据文件中,然后再结合redo log完成崩溃恢复的工作。
总结:
(1)写失效是指在数据页写入磁盘的过程中,由于系统宕机或其他原因导致数据页部分写入成功,部分写入失败,从而造成数据页损坏的情况。
(2)双写缓冲区通过在数据页写入磁盘之前,先将数据页写入系统表空间中,确保即使在写入过程中发生宕机,也可以通过系统表空间中的数据页副本恢复损坏的数据页。
(3)双写缓冲区的大小为2MB,由128个页组成,分为内存部分和磁盘部分。
(4)双写缓冲区会引入一定的性能开销,但在大多数情况下,这种开销完全值得,因为它提供了更高的安全性和可靠性。
(5)在Mysql的Innodb存储引擎中,redo log和Doublewrite buffer是配合工作的,目的是确保数据的持久性和恢复能力。在恢复过程中,如果存在损坏的数据页,Innodb首先会去双写缓冲区文件中找数据页副本,用副本尝试恢复损坏的数据页,然后再应用redo log完成数据的同步。









