


自研为基,AI为矛,破局国产数据库困局
日前,一篇科技圈的重磅新闻引起业内的广泛关注,Oracle 与 OpenAI 签下了一份每年300亿美元的云计算合同,并将为其“星际之门”计划额外提供4.5千兆瓦的算力容量。表面看来这是一次算力交易,但深层次是对基础数据管理能力的重塑。
这一消息,整个科技界为之震动。这不仅是商业合作,更是AI时代下数据竞争格局的宣言——谁能掌握并持续输出数据管理能力,谁就扼住了未来智能世界的命脉。
这场豪赌的背后,是全球巨头对AI底层架构话语权的激烈角逐。AI尚未实现大规模盈利,但资本已如脱缰野马,驱动着数据军备竞赛驶向未知深空。有人惊呼这是“互联网泡沫2.0”,更多人则将AI喻为“新时代的石油”。
然而,值得深思的是,当国际巨头在AI基础数据能力上高歌猛进之时,国产数据库的境遇却呈现出令人深思的对比。
国产数据库困局:繁荣表象下的结构性危机
据国内第三方机构的最新统计,中国数据库企业数量相较去年锐减60余家。这个冰冷的数字背后,折射出残酷现实:在AI驱动的数据革命浪潮中,许多国产玩家正逐渐掉队。
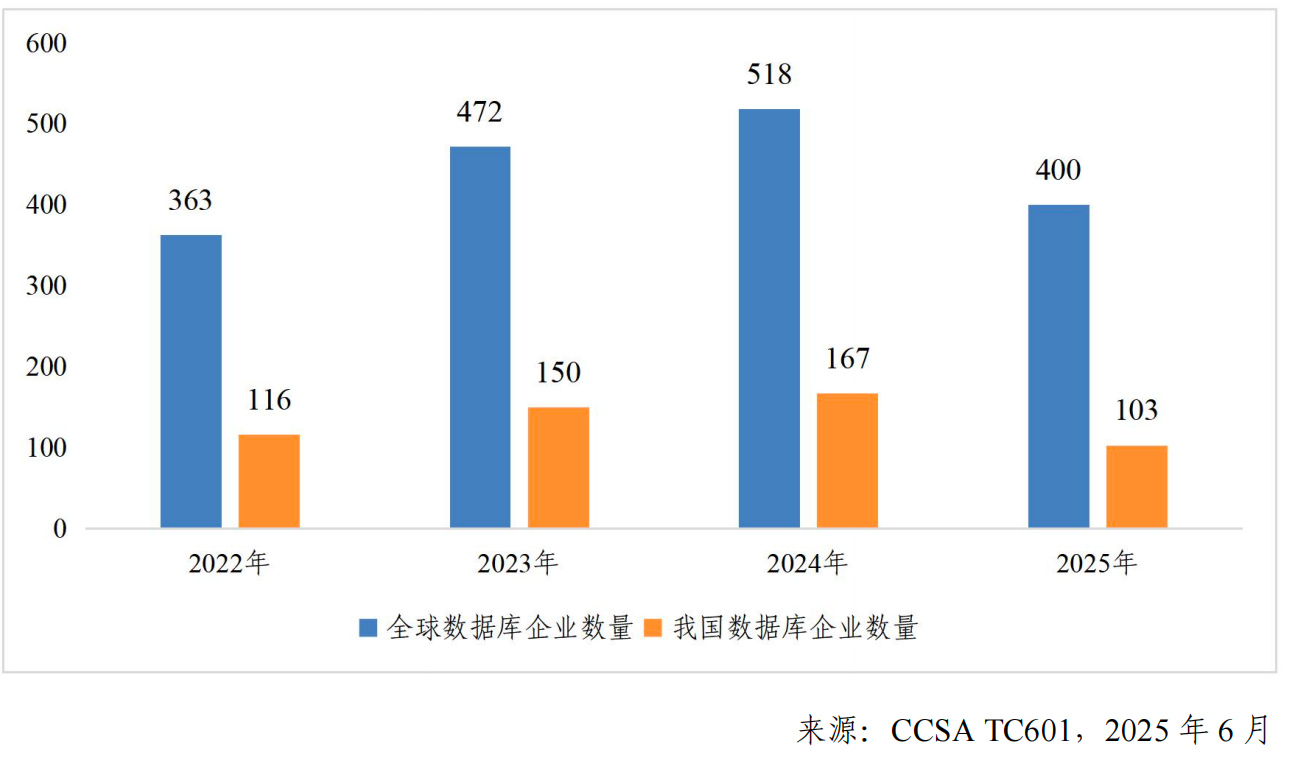
当前国产数据库生态看似百花齐放,实则暗藏隐忧。
其一是技术路线分化割裂,包括自研内核、魔改开源、买断改造,三大阵营各自为战;
其二是重复造轮消耗内力,大量资源耗费在基础功能重复实现,而非核心技术创新突破;
其三是生态孤岛难以破壁,标准不统一、接口碎片化、工具链薄弱,用户陷入“选型即锁定”的困境;
其四是商业能力捉襟见肘,部分产品宣传声势浩大,实则难以稳定支撑企业级关键负载。
这种“内卷式”发展,导致国产数据库在AI爆发前夕的关键节点,于底层数据能力支撑、数据库引擎效能、数据治理体系等核心基础设施层面,陷入低层次内卷的尴尬境地。当Oracle正构建支撑千亿级AI模型的“星际之门”时,国内却在基础轮子上反复消耗,方向性的偏差远比技术短板更加致命。
用户数据之痛:呼唤“真正能用敢用”之选
当企业的CIO们翻开国产数据库选型清单时,眼前展开的是一幅令人眼花缭乱的图景:超过二百余家厂商的产品名录,覆盖关系型、时序型、图数据库等十余个品类,在架构上分布式、集中式等不一而足。
然而这份“繁荣”背后,却隐藏着令人窒息的现实困境。
一方面国产数据库生态呈现碎片化,虽然各家都在强调兼容能力,但在实际应用上存在诸多不同;另一方面选择国产数据库不得不面临迁移、适配、改造等巨额成本投入,而最终使用效果却不尽如人意。然而,比上述更为致命的问题是当系统上线后面临内核异常、性能瓶颈、安全漏洞时,却发现数据库厂商无法解决。
这无疑揭开了行业伤疤,很多号称“完全自主”的数据库,溯源之后多是来自开源项目内核,这种“伪自研”的做法正带来全行业的系统性风险。更不用提在这一基础上去构造面向AI时代的下一个数据基础设施,正所谓“基础不牢,再好的AI应用都成空中楼阁”。
破局之道:以全栈自研筑基,拥抱AI与信创大时代
正是这些切肤之痛,让市场呼唤真正具备基因级创新的国产数据库。企业需要的不仅是“能用”,更是满足三大核心诉求的终极方案:一是坚固如磐石的底座:内核全自研确保无“断供”风险,金融级高可用支撑核心业务;二是面向未来的架构:原生支持向量数据、异构数据融合查询等AI时代刚需;三是平滑进化的生态:不仅要兼容现有体系,还能为智能化升级预留接口。
正是在国产数据库面临收缩与挑战的大背景下,国产数据库只有以坚定全栈自研决心和前瞻性的技术投入与战略布局,才能成为最终破局的关键力量。
其一是硬核自研,铸就“能用敢用”的基石:数据库产品在发展之初就应摒弃魔改开源或买断改造的捷径,坚持从存储引擎、查询优化器、事务管理模块等基础组件着手,100%独立研发。这确保了技术路线的完全自主可控,无“断供”风险,无授权纠纷,为在关键行业特别是信创领域的深度应用打下坚实基础;以攻克高端领域技术制高点为目标,例如共享集群技术已成为国产替代“深水区”的首选技术方案,其天生具备处理核心场景的高可用、高性能、高并发及混合负载(HTAP)等关键能力。
其二是信创锤炼,打磨“能用好用”的利器: 信创之于国产数据库而言,绝非短暂的政策风口,而是其锤炼产品、构建生态的核心战场。只有深度参与金融、能源、政务等关键行业信创实践,完成与主流国产芯片、操作系统、中间件的全栈适配与性能调优,并在实践中不断完善,才能最终赢得“敢用、会用、好用”的用户口碑。
其三是AI赋能,开启“智能协同”的新篇:趋势来看要将AI视为数据库进化的必然方向,以跨模融合查询、智能优化器、向量引擎为突破口,着力构建多架构、多负载、多模型的智能数据底座。不断的信创实践,是打磨产品、验证能力的熔炉;而其对AI的前瞻投入,则是引领国产数据库迈向智能化、服务化未来的战略升级。信创是立足当下的根基,AI是决胜未来的引擎。
总结篇:生态聚合与价值回归
Oracle的300亿大单,是其数十年构建的强大生态聚合能力的集中爆发。它给我们启示是国产数据库的竞争,已从单一产品的较量,跃升为生态体系成熟度与可持续性发展的全面比拼。
国产数据库的破局之路清晰而坚定:一是以全栈自研铸就“硬核”可控基座,这是应对信创要求与规避技术风险的唯一正解;二是以AI原生能力重塑数据库价值,让数据平台不仅是存储仓库,更是智能业务的内生引擎;三是以开放生态打破孤岛困境,连接算力、模型与应用,让数据价值在企业血脉中真正流动。在众多国产数据库中,崖山YashanDB产品正践行了这一发展理念,以核心自研为根本,以信创替换为基础,面向未来布局AI时代的数据底座。
数据库本身从来不是终极目的,当销售数据能实时驱动生产排程,当仓库信息可自动触发供应链优化,当海量日志能瞬时洞察安全威胁,当向量搜索让个性化推荐精准直达——让数据智能真正驱动业务创新与增长。
当前正处于AI定义未来的临界点上,国产数据库只有选择以扎实的自研穿越信创熔炉,以开放的姿态拥抱智能革命。当潮水退去,唯有掌握核心技术与生态聚合能力的真正强者,方能屹立潮头,开启属于中国数据库的“星际之门”。









