


数据库与缓存不一致,你会怎么办?
今天聊聊数据库yu缓存的一致性问题。
数据库主从,为什么会不一致?
先回顾下,无缓存时,数据库主从不一致问题。
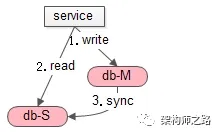
如上图,发生的场景是,写后立刻读:
- 主库一个写请求(主从没同步完成);
- 从库接着一个读请求,读到了旧数据;
- 最后,主从同步完成;
导致的结果是:主动同步完成之前,会读取到旧数据。
可以看到,主从不一致的影响时间很短,在主从同步完成后,就会读到新数据。
缓存与数据库,什么时候会不一致?
再看,引入缓存后,缓存和数据库不一致问题。
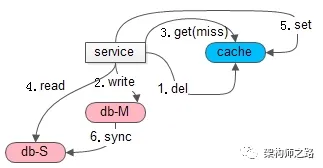
如上图,发生的场景也是,写后立刻读:
- (1+2)先一个写请求,淘汰缓存,写数据库;
- (3+4+5)接着立刻一个读请求,读缓存,cache miss,读从库,写缓存放入数据,以便后续的读能够cache hit(主从同步没有完成,缓存中放入了旧数据);
- (6)最后,主从同步完成;
导致的结果是:旧数据放入缓存,即使主从同步完成,后续仍然会从缓存一直读取到旧数据。
可以看到,加入缓存后,导致的不一致影响时间会很长,并且最终也不会达到一致。
为什么会出现这类不一致?
如上所述,缓存与数据库数据不一致,根本上是由数据库主从不一致引起的。当主库上发生写操作之后,从库binlog同步的时间间隔内,读请求,可能导致有旧数据入缓存。
假如主从不一致没法彻底解决,引入缓存之后,binlog同步时间间隔内,也无法避免读旧数据。
但是,有没有办法做到,即使引入缓存,不一致不会比“不引入缓存”更糟呢?
这是更为实际的优化目标。
思路转化为:在从库同步完成之后,如果有旧数据入缓存,应该及时把这个旧数据淘汰掉。
缓存与数据库不一致,可以怎么优化?
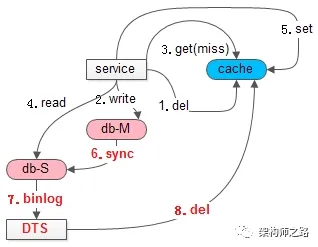
如上图所述,在并发读写导致缓存中读入了脏数据之后:
- (6)主从同步;
- (7)通过工具订阅从库的binlog,这里能够最准确的知道,从库数据同步完成的时间;
- (8)从库执行完写操作,向缓存再次发起删除,淘汰这段时间内可能写入缓存的旧数据;
如此这般,至少能够保证,引入缓存之后,主从不一致,不会比没有引入缓存更坏。
知其然,知其所以然。
思路比结论更重要。









