


面试官:谈谈你对分库分表的理解?
在 MySQL 集群架构中有两种主流的集群实现,一种是读写分离,而另外一种则是数据分片。所谓的数据分片其实就是今天要聊的分库分表技术。
分库分表技术不但是日常工作中用于解决数据库中的数据量会急剧增长,解决单库单表性能瓶颈的一种方案,更是面试中的高频知识点。
在阿里巴巴的《Java 开发手册》中规定:当单表的数据超过 500 万,或单表的大小超过 2GB 时,就要考虑分库分表了。那么什么是分库分表呢?
1.分库分表
首先来说,“分库分表”不是一个技术,而是两个技术实现,它分为:
- 分库
垂直分库
水平分库
- 分表
垂直分表
水平分表
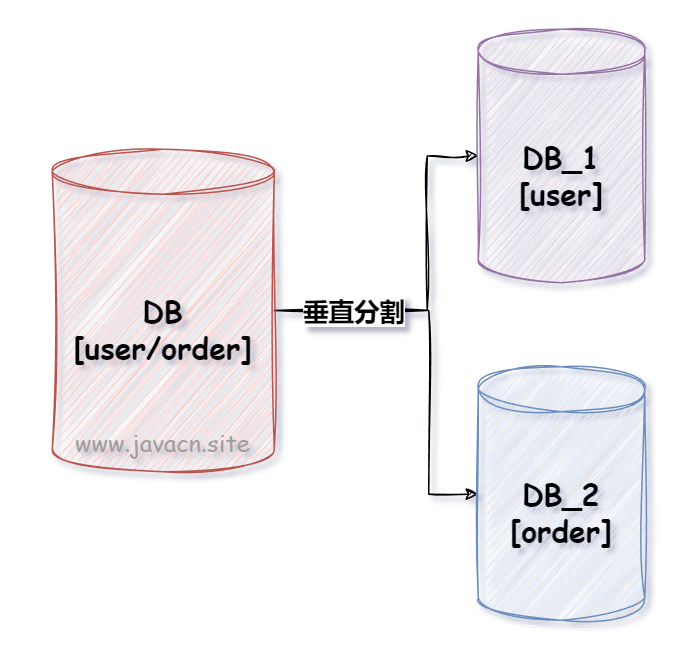
1.1 垂直分库
垂直分库是按照业务将不同的表拆分到不同的数据库中。例如,在一个电商数据库中的用户表和订单表分别存放到不同的数据库中,如下图所示:
 图片
图片
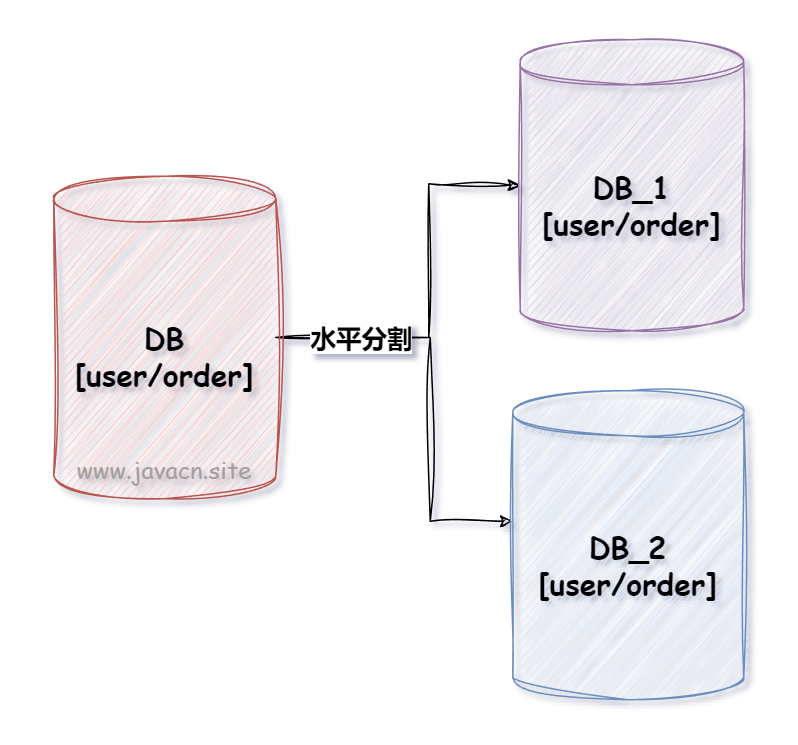
1.2 水平分库
水平分库是将数据按照一定的规则(如用户 ID 取模、哈希等)分布到不同的数据库中。比如,根据用户 ID 对 10 取模,将用户数据分布到 10 个不同的数据库中,每个数据库都保存着完整的数据表结构,如下图所示:
 图片
图片
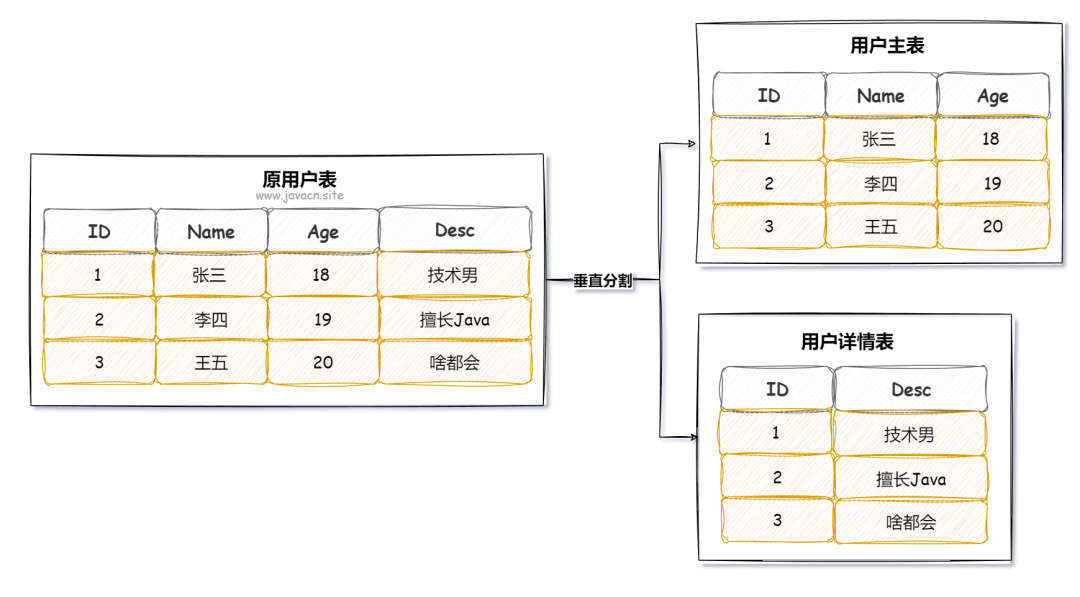
1.3 垂直分表
垂直分表是将一张表按照列的相关性拆分成多张表。例如,将一个包含大量字段的用户表,拆分为用户基本信息表和用户扩展信息表,如下图所示:
 图片
图片
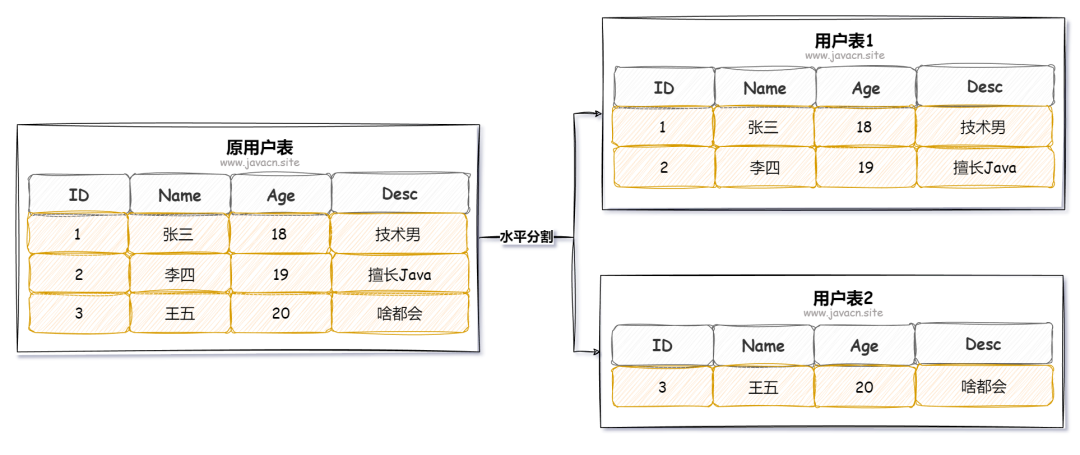
1.4 水平分表
水平分表是将一张表的数据按照行进行拆分。例如按照用户 ID 的范围或者哈希值将数据拆分到不同的表中。
 图片
图片
如果搞不清楚什么是垂直分表和什么是水平分表?可以参考一下这幅图思考一下: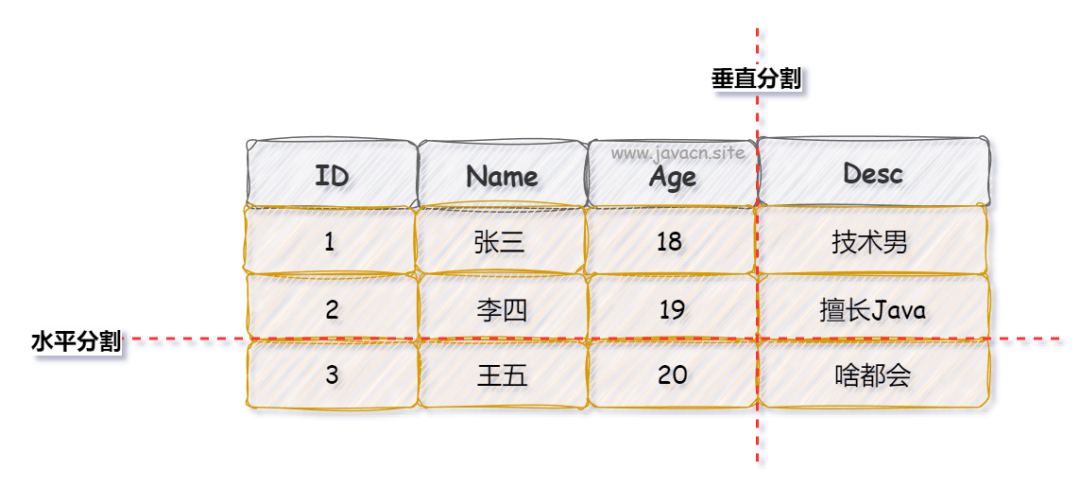
2.技术实现
分库分表的主流实现技术有以下两种:
- MyCat
- Apache Sharding Sphere
Sharding Sphere 相比于 MyCat 来说,它的优势是:
- 功能更多:除了读写分离和分库分表之外,还提供了数据加密、流量质量、数据迁移等功能。
- 社区更活跃度和生态更好:Sharding Sphere 拥有活跃的社区和丰富的文档,生态系统较为完善,有更多的用户和开发者参与。
- 灵活性和扩展性:Sharding Sphere 灵活性更高,扩展性也更好,它可以方便地与其他技术集成,这方便 MyCat 支持的比较有限。
3.Sharding Sphere
Sharding Sphere 最早是当当网的内部框架,后面捐献给了 Apache,目前也是分库分表的主流技术实现方案,在 Sharding Sphere 中有两种分库分表的技术实现:
- Sharding Sphere JDBC:定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
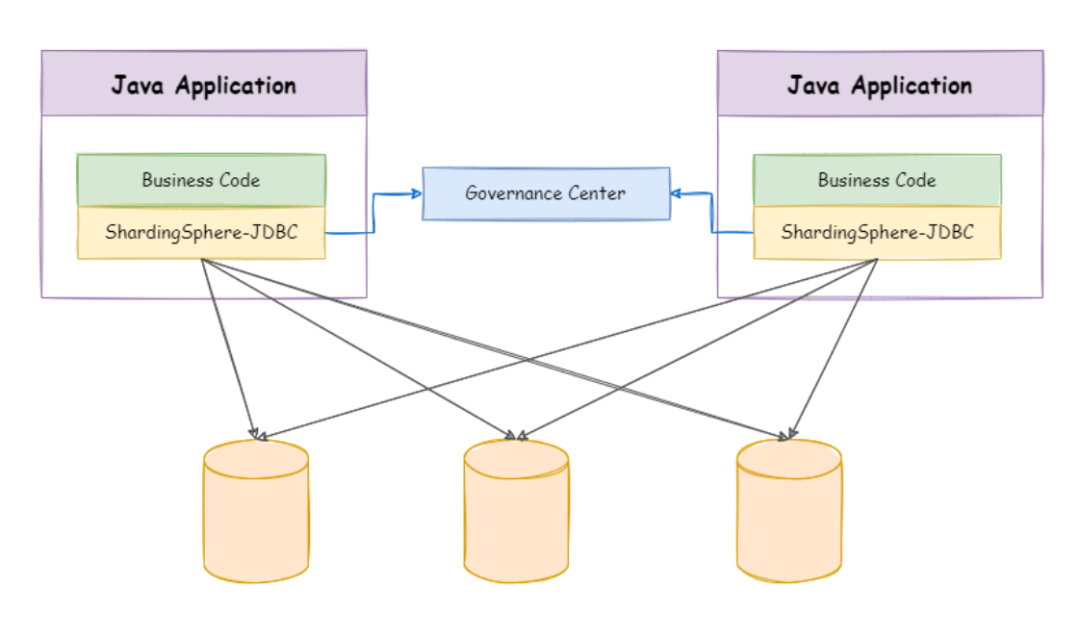 图片
图片
- Sharding Sphere Proxy:定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
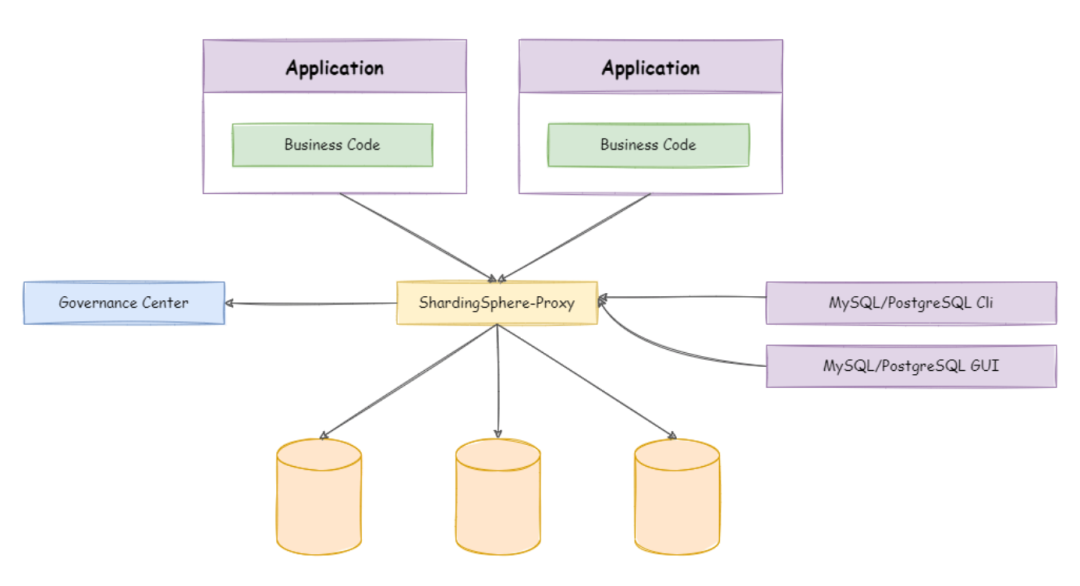 图片
图片
它们的区别如下:
ShardingSphere-JDBC | ShardingSphere-Proxy | |
支持数据库 | 任意 | MySQL/PostgreSQL |
连接消耗数 | 高 | 低 |
支持语言 | 仅 Java | 任意 |
性能 | 损耗低 | 损耗略高 |
无中心化 | 是 | 否 |
课后思考
Sharding Sphere JDBC 和 Sharding Sphere Proxy 使用场景分别是啥?ShardingSphere-JDBC 具体实现步骤有哪些?说说它的实现原理?









