


详解 mini-redis 复刻 Redis 的 I NCR 指令
因为近期比较忙碌,所以对于mini-redis的复刻基本处于一些指令向的完善,而本文将针对字符串操作中介绍笔者近期所复刻的键值自增指令的落地思路,以帮助读者更好的理解和学习mini-redis。

对象类型前置校验
因为指令是基于字符串操作的,所以在执行INCR或者DECR之前我们都必须针对入参的键值对进行校验,所以对于以下情况,我们都必须采用fail-fast的方式提前将失败暴露,将键值对已存在,对应的值非字符串类型(例如:字典类型),直接响应错误:
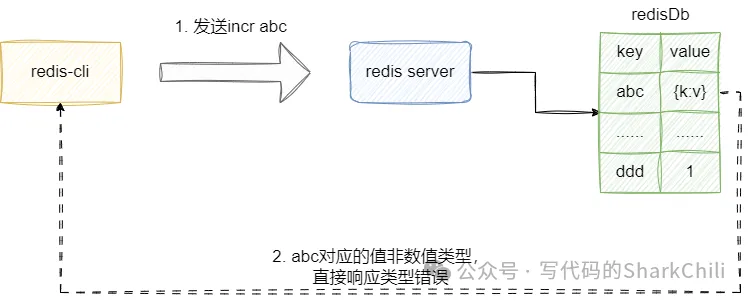
基于上述的基本概念,我们给出落地的代码,即位于command.go的incrDecrCommand方法,可以看到我们会优先到redis内存中查看是否存在对应的key,如果存在则进行必要的类型判断,如果非字符串类型即REDIS_STRING则直接响应错误出去,并直接返回:
func incrDecrCommand(c *redisClient, incr int64) {
var value int64
var oldValue int64
var newObj *robj
//查看键值对是否存在
o := lookupKeyWrite(c.db, c.argv[1])
//如果键值对存在且类型非字符串类型,直接响应错误并返回
if o != nil && checkType(c, o, REDIS_STRING) {
return
}
//......
}对此我们也给出checkType的内部逻辑,可以看到当比对类型不一致时会直接输出错误并返回true,读者可以参考注释了解:
func checkType(c *redisClient, o *robj, rType int) bool {
//如果类型不一致,则输出-WRONGTYPE Operation against a key holding the wrong kind of value
if o.robjType != rType {
addReply(c, shared.wrongtypeerr)
return true
}
return false
}其实笔者这里也想吐槽一句redis对于函数设计的语义的不恰当性,理论性合理的函数进行校验时正确的做法应该是:
- 逻辑校验失败,输出错误返回false。
- 逻辑校验正确,返回true。
也只能说因为某些历史原因,或者设计者有着自己的主观编码习惯吧,本着一比一的复刻理念,笔者也沿袭了这样的编码思路。
基于数值池高效完成字符串转换
针对字符串类型(可以转数值的情况下,它也会转数值类型),我们都是通过robj类型创建和维护,因为我们本次所复刻的incr和decr所操作的类型是字符串中可转为数值的对象,所以本着数值类型有迹可循的规律以及空间换时间的思想,我们提出池化思想,即将0-9999数值缓存一份数值池,后续的增减操作后处于该范围的数值都可以直接使用数值池里对应的robj对象,以节约robj对象创建的开销和非必要的内存资源占用:
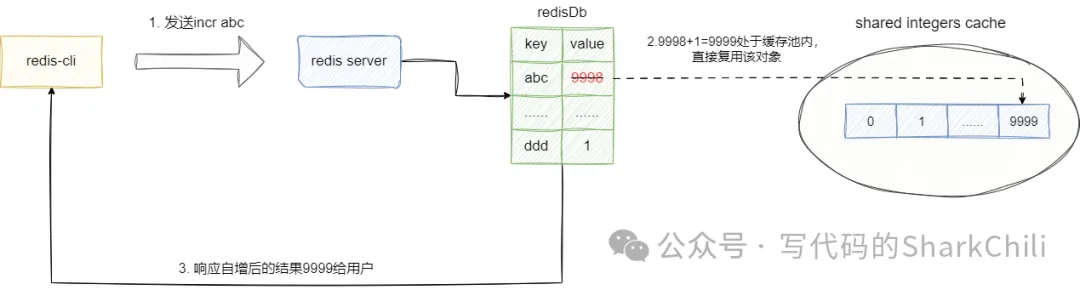
所以笔者在main.go中声明sharedObjectsStruct 这个结构体中声明了一个integers维护常量池的robj对象:
type sharedObjectsStruct struct {
//......
integers [REDIS_SHARED_INTEGERS]*robj //通用0~9999常量数值池
//......
}然后在createSharedObjects方法中完成初始化,后续就可以直接使用了:
func createSharedObjects() {
//......
var i int64
//初始化常量池对象
for i = 0; i < REDIS_SHARED_INTEGERS; i++ {
//基于接口封装数值
num := interface{}(i)
//生成string对象
shared.integers[i] = createObject(REDIS_STRING, &num)
//声明编码类型为int
shared.integers[i].encoding = REDIS_ENCODING_INT
}
//......
}于是我们就得出了后续的编码逻辑:
- 将value强转为数值判断是否超出范围,如果超了则抛出异常。反之进入步骤2。
- 查看取值范围是否大于10000,如果是则自己生成robj对象,反之采用池化数值池的robj。
- 基于1、2生成的数值对象将键值对更新或者覆盖到内存数据库中。
/**
针对字符串类型的值进行如下判断的和转换:
1. 如果为空,说明本次的key不存在,直接初始化一个空字符串,后续会直接初始化一个0值使用
2. 如果是字符串类型,则转为字符串类型
3. 如果是数值类型,则先转为字符串类型进行后续的通用数值转换操作保证一致性
*/
var s string
if o == nil {
s = ""
} else if isString(*o.ptr) {
s = (*o.ptr).(string)
} else {
s = strconv.FormatInt((*o.ptr).(int64), 10)
}
//进行类型强转为数值,如果失败,直接输出错误并返回
if getLongLongFromObjectOrReply(c, s, &value, nil) != REDIS_OK {
return
}
oldValue = value
//如果累加超范围则报错
if (incr < 0 && oldValue < 0 && incr < (math.MinInt64-oldValue)) ||
(incr > 0 && oldValue > 0 && incr > (math.MaxInt64-oldValue)) {
errReply := "increment or decrement would overflow"
addReplyError(c, &errReply)
return
}
//基于incr累加的值生成value
value += incr
//如果超常量池范围则封装一个对象使用
if o != nil &&
(value < 0 || value >= REDIS_SHARED_INTEGERS) &&
(value > math.MinInt64 || value < math.MaxInt64) {
newObj = o
i := interface{}(value)
o.ptr = &i
} else if o != nil {//如果对象存在,且累加结果没超范围则调用createStringObjectFromLongLong获取常量对象
newObj = createStringObjectFromLongLong(value)
//将写入结果覆盖
dbOverwrite(c.db, c.argv[1], newObj)
} else {//从常量池获取数值,然后添加键值对到数据库中
newObj = createStringObjectFromLongLong(value)
dbAdd(c.db, c.argv[1], newObj)
}通用结果响应
完成上述操作后就是将结果按照RESP协议规范将结果响应给客户端,按照协议要求数值类型必须用:号开头,所以假设我们累加结果为10,那么响应给客户端的结果就是10 。
对应我们的给出最后的代码段:
//将累加后的结果返回给客户端,按照RESP格式即 :数值
,例如返回10 那么格式就是:10
reply := *shared.colon + strconv.FormatInt(value, 10) + *shared.crlf
addReply(c, &reply)完整的代码实现
我们来小结一下上述的实现思路:
- 键值对查询与校验。
- 数值类型转换与越界判断。
- 字符串类型强转并基于取值范围查看是否通过数值池获取。
- 更新或覆盖键值对。
- 将操作结果返回客户端。
完整代码如下:
func incrDecrCommand(c *redisClient, incr int64) {
var value int64
var oldValue int64
var newObj *robj
//查看键值对是否存在
o := lookupKeyWrite(c.db, c.argv[1])
//如果键值对存在且类型非字符串类型,直接响应错误并返回
if o != nil && checkType(c, o, REDIS_STRING) {
return
}
/**
针对字符串类型的值进行如下判断的和转换:
1. 如果为空,说明本次的key不存在,直接初始化一个空字符串,后续会直接初始化一个0值使用
2. 如果是字符串类型,则转为字符串类型
3. 如果是数值类型,则先转为字符串类型进行后续的通用数值转换操作保证一致性
*/
var s string
if o == nil {
s = ""
} else if isString(*o.ptr) {
s = (*o.ptr).(string)
} else {
s = strconv.FormatInt((*o.ptr).(int64), 10)
}
//进行类型强转为数值,如果失败,直接输出错误并返回
if getLongLongFromObjectOrReply(c, s, &value, nil) != REDIS_OK {
return
}
oldValue = value
if (incr < 0 && oldValue < 0 && incr < (math.MinInt64-oldValue)) ||
(incr > 0 && oldValue > 0 && incr > (math.MaxInt64-oldValue)) {
errReply := "increment or decrement would overflow"
addReplyError(c, &errReply)
return
}
//基于incr累加的值生成value
value += incr
//如果超常量池范围则封装一个对象使用
if o != nil &&
(value < 0 || value >= REDIS_SHARED_INTEGERS) &&
(value > math.MinInt64 || value < math.MaxInt64) {
newObj = o
i := interface{}(value)
o.ptr = &i
} else if o != nil { //如果对象存在,且累加结果没超范围则调用createStringObjectFromLongLong获取常量对象
newObj = createStringObjectFromLongLong(value)
//将写入结果覆盖
dbOverwrite(c.db, c.argv[1], newObj)
} else { //从常量池获取数值,然后添加键值对到数据库中
newObj = createStringObjectFromLongLong(value)
dbAdd(c.db, c.argv[1], newObj)
}
//将累加后的结果返回给客户端,按照RESP格式即 :数值
,例如返回10 那么格式就是:10
reply := *shared.colon + strconv.FormatInt(value, 10) + *shared.crlf
addReply(c, &reply)
}递增递减的复用
基于上述函数对应的递增指令INCR就使用incrCommand,入参传1代表加1,而decrCommand则传-1扣减即可:
func incrCommand(c *redisClient) {
//累加1
incrDecrCommand(c, 1)
}
func decrCommand(c *redisClient) {
//递减1
incrDecrCommand(c, -1)
}最终效果演示
最后,我们将服务启动进行测试,可以看到指令正常执行:
127.0.0.1:6379> incr k1
(integer) 1
(4.50s)
127.0.0.1:6379> incr k1
(integer) 2
127.0.0.1:6379> incr k1
(integer) 3
127.0.0.1:6379> incr k1
(integer) 4
127.0.0.1:6379> incr k1
(integer) 5
127.0.0.1:6379> incr k1
(integer) 6
127.0.0.1:6379> decr k1
(integer) 5
127.0.0.1:6379> decr k1
(integer) 4
127.0.0.1:6379> decr k1
(integer) 3
127.0.0.1:6379> decr k1
(integer) 2
127.0.0.1:6379> decr k1
(integer) 1
127.0.0.1:6379> decr k1
(integer) 0
127.0.0.1:6379> decr k1
(integer) -1
127.0.0.1:6379>








