


最火向量数据库Milvus安装使用一条龙!

向量数据库是大模型应用开发必备组件之一,因为它知识库、语义搜索、检索增强生成(RAG)等人工智能应用中发挥着举足轻重的作用。但向量数据有很多,为什么要使用 Milvus 呢?
常见向量数据
常见的向量数据库有以下这些:
- Chroma
- Elasticsearch
- Milvus
- Neo4j
- OpenSearch
- Redis
- PGVector
然而目前市面上使用最多的向量数据库还是 Milvus,为什么呢?
这点从企业的招聘要求中也能发现:

为什么是 Milvus?
Milvus 设计之初就是为 AI 而生的一个高效的向量数据库系统,在大多数情况下,Milvus 的性能是其他向量数据库的 2-5 倍,它能实现万亿级向量的毫秒级相似性搜索,而且 Milvus 还是开源的向量数据库。
“
PS:也就说 Milvus 既开源(可以免费使用+支持二次开发)又具备高性能,这样的数据库谁不爱呢?
为什么 Milvus 这么快?
Milvus 运行比较快的原因有以下几个:
- 硬件感知优化:为了让 Milvus 适应各种硬件环境,我们专门针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和 NVMe SSD。
- 高级搜索算法:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与 FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。
- C++ 搜索引擎:向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 将 C++ 用于这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。
- 面向列:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。
Milvus 支持的搜索类型
Milvus 支持各种类型的搜索功能,以满足不同用例的需求:
- ANN 搜索:查找最接近查询向量的前 K 个向量。
- 过滤搜索:在指定的过滤条件下执行 ANN 搜索。
- 范围搜索:查找查询向量指定半径范围内的向量。
- 混合搜索:基于多个向量场进行 ANN 搜索。
- 全文搜索:基于 BM25 的全文搜索。
- Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。
- 根据主键检索数据。
- 查询使用特定表达式检索数据。
Milvus 安装
Milvus 有三种部署方式:
- Milvus Lite:Milvus Lite 是一个 Python 库,可导入到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter 笔记本或资源有限的智能设备上运行快速原型。Milvus Lite 支持与 Milvus 其他部署相同的 API。与 Milvus Lite 交互的客户端代码也能与其他部署模式下的 Milvus 实例协同工作。
- Milvus Standalone:Milvus Standalone 是单机服务器部署。Milvus Standalone 的所有组件都打包到一个 Docker 镜像中,部署起来非常方便。
- Milvus Distributed:Milvus Distributed 可部署在 Kubernetes 集群上。这种部署采用云原生架构,摄取负载和搜索查询分别由独立节点处理,允许关键组件冗余。它具有最高的可扩展性和可用性,并能灵活定制每个组件中分配的资源。Milvus Distributed 是在生产中运行大规模向量搜索系统的企业用户的首选。
“
PS:当然中小型公司生产环境也可以直接购买 XXX 云的 Milvus 实例直接使用。
我们这里使用 Milvus Standalone 单机版部署方式。
硬件要求
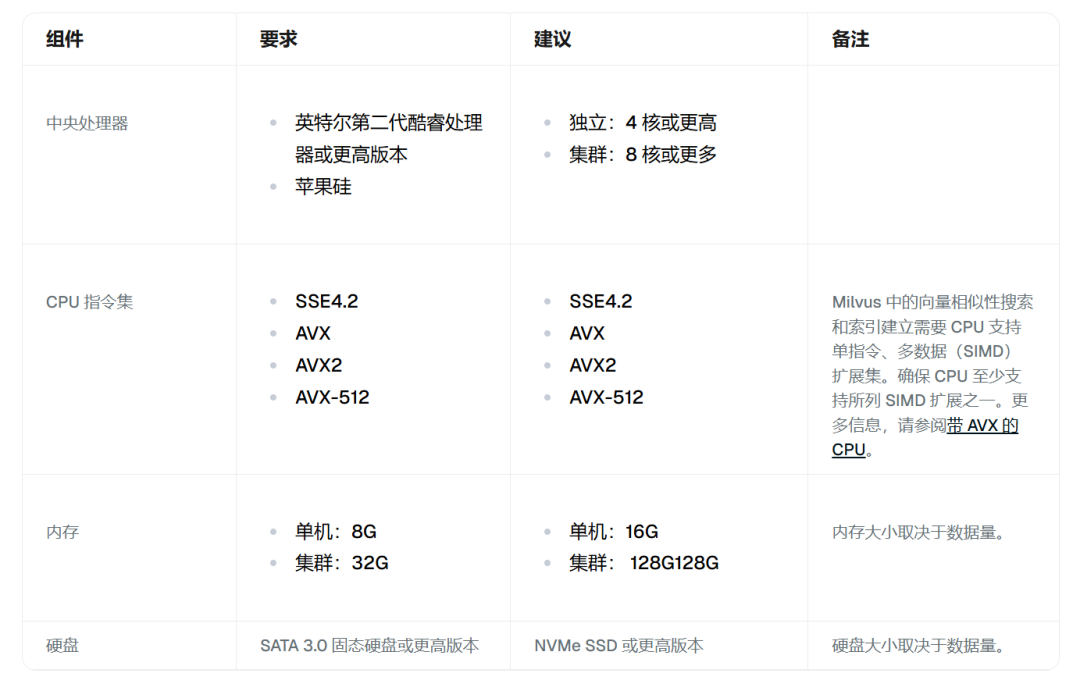
前提条件
- 安装 Docker Desktop:点击下载软件安装 https://www.docker.com/get-started/
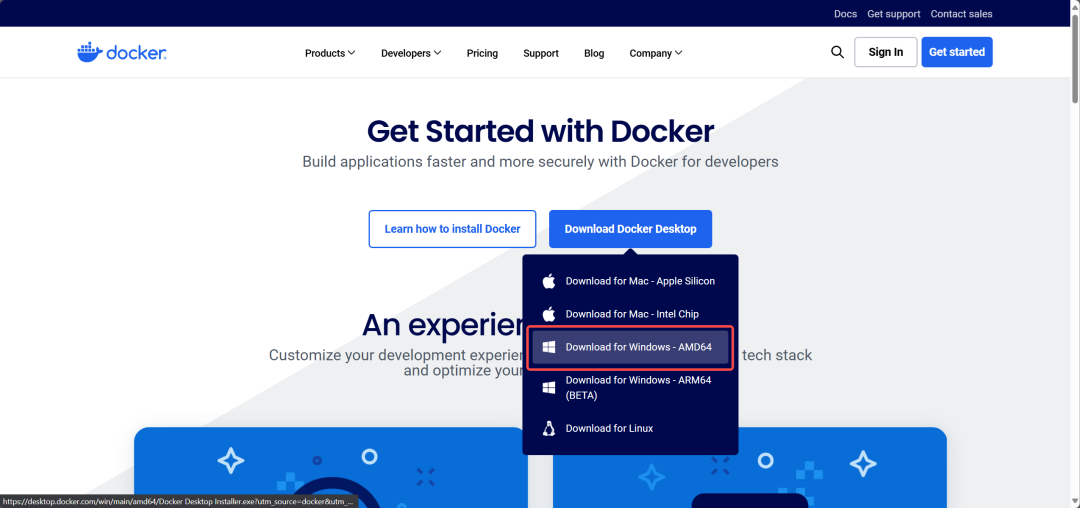
- 安装之后,需要重启电脑,并且电脑会进行 Linux 子系统更新才能正常启动,此过程可能会比较慢。
- 安装 Windows Subsystem for Linux 2 (WSL 2):通常不需要单独安装,安装 Docker Desktop 时会自动安装。
正式安装
1.打开 PowerShell。
2.下载安装脚本,命令如下:
Invoke-WebRequest https://raw.githubusercontent.com/milvus-io/milvus/refs/heads/master/scripts/standalone_embed.bat -OutFile standalone.bat3.运行下载的脚本
standalone.bat start最终执行效果如下:
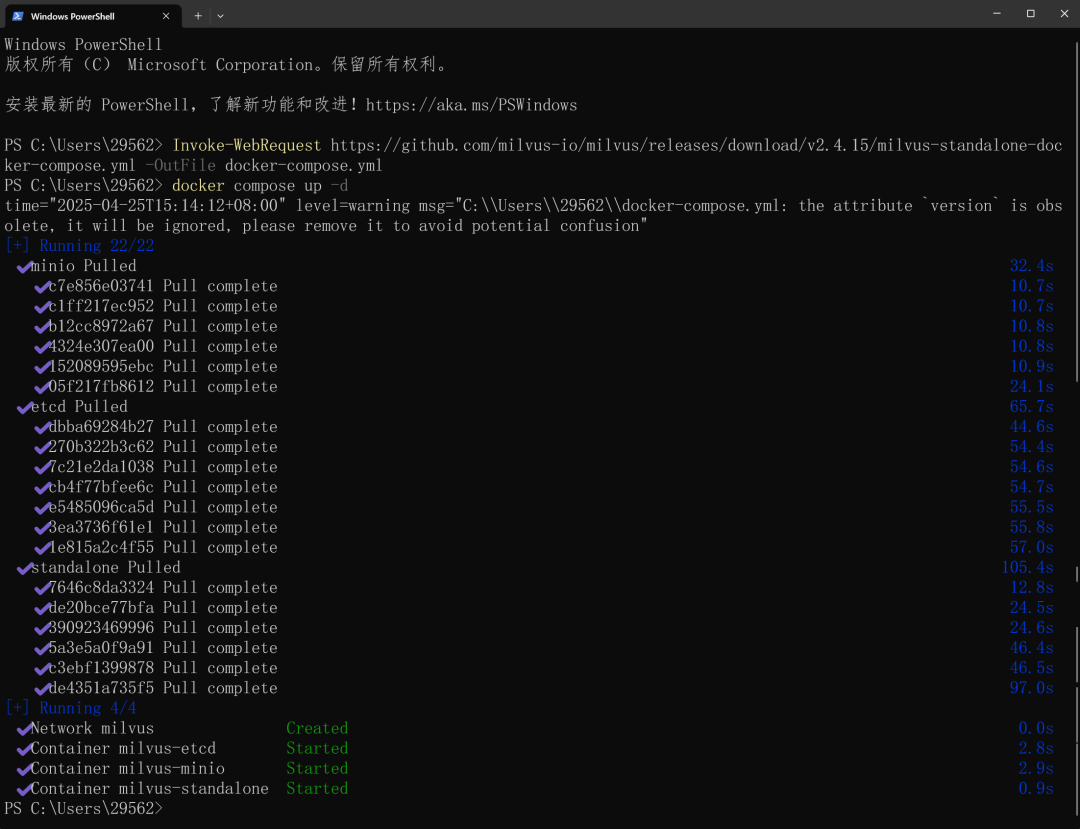
运行安装脚本后,包含以下内容:
- 名为 Milvus-standalone 的 docker 容器已在19530 端口启动。
- 嵌入式 etcd 与 Milvus 安装在同一个容器中,服务端口为 2379。其配置文件被映射到当前文件夹中的 embedEtcd.yaml。
- Milvus 数据卷映射到当前文件夹中的 volumes/milvus。
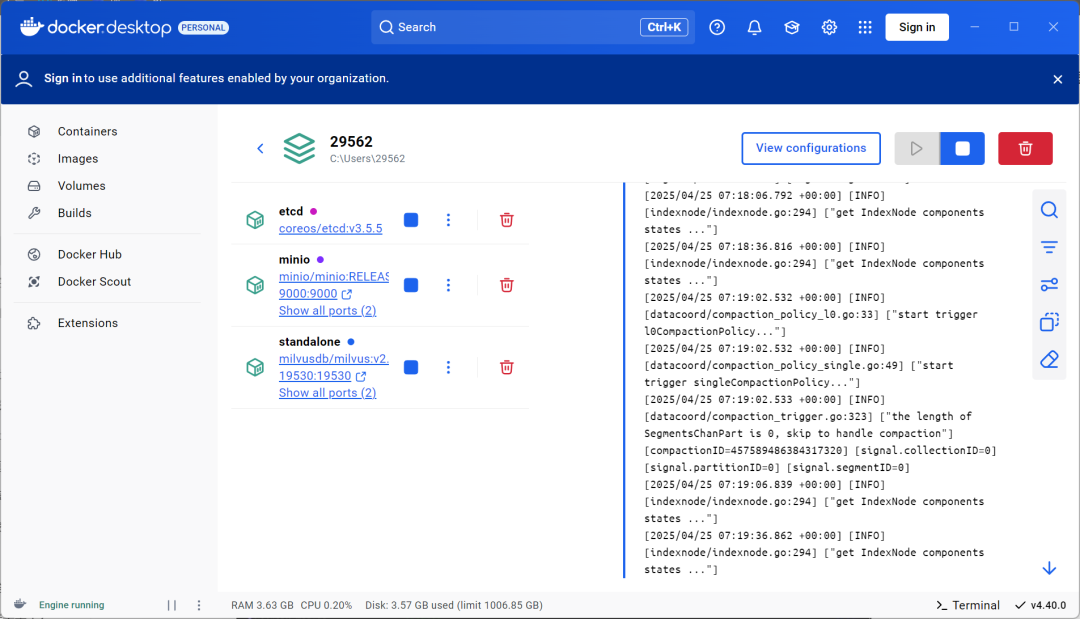
在 Docker Desktop 也可以看到安装的 Milvus 相关组件:
参考官方文档:https://milvus.io/docs/zh/install_standalone-windows.md
安装 UI 客户端
Milvus 服务安装成功之后,可以按照一个 UI 客户端连接 Milvus 服务,使用官方提供的客户端 attu:https://github.com/zilliztech/attu
具体安装步骤如下:
1.访问下载安装包(attu-Setup-2.4.12.exe)地址:https://github.com/zilliztech/attu/releases/tag/v2.4.12
2.解压并安装 attu。
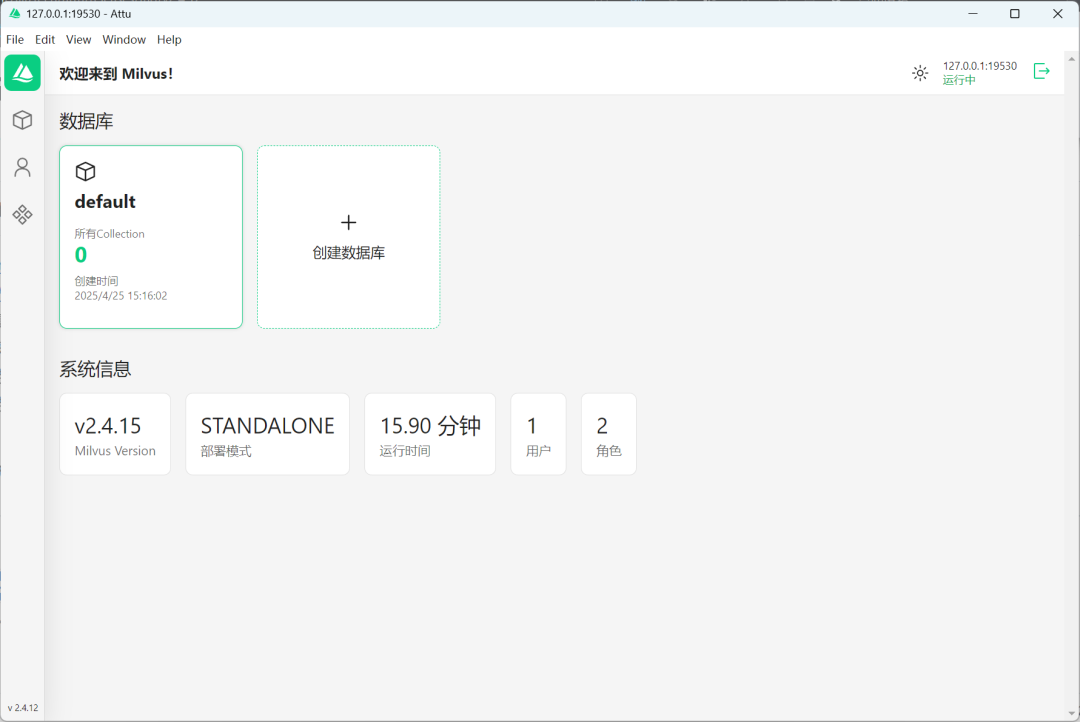
安装成功之后连接本地 Milvus 服务,如下图所示:
小结
Milvus 作为开源高性能向量数据库的代表,它的安装也不难,如果顺利的情况下,可能 5 分钟左右就搞定了。安装完成之后就用它加上 Spring AI 或 LangChain4j 来实现一下 RAG 功能吧。









