


告别云端焦虑:我用一台服务器搭了个「私人AI大脑」,性能不输GPT
写在前面的废话
你有没有这种经历:半夜三点,灵感突然爆发,想用ChatGPT写点东西,结果网络抽风;或者想让AI帮你处理点敏感数据,却总担心隐私泄露;再或者,每个月看着订阅账单肉疼,却又离不开AI助手?
如果你点了三次头,恭喜你,我们是同一类人——既想享受AI的便利,又不想被大厂牵着鼻子走的「技术洁癖患者」。
这篇文章要聊的,就是我花了几周时间折腾出来的解决方案:一套完全本地化、完全私有的LLM服务器架构。没有订阅费,没有审查,没有网络依赖,想怎么玩就怎么玩。更重要的是,这套方案已经跑了几个月,稳定得让我都有点不习惯。
一、为什么要自己搭服务器?云端AI不香吗?
1.1 隐私焦虑:你的对话真的安全吗?
坦白说,当我把公司的代码片段丢给ChatGPT调试时,心里总有点发虚。虽然OpenAI声称不会用对话数据训练模型,但谁知道呢?万一哪天被脱裤,或者某个实习生手滑,你的商业机密就可能变成别人的训练素材。
更别提那些更敏感的场景——医疗数据分析、法律文书处理、个人日记整理——这些东西你真的敢交给云端吗?
1.2 成本黑洞:订阅费只是开始
ChatGPT Plus 每月20美元,Claude Pro 也是20美元,再加上各种API调用费用,一年下来大几千块轻轻松松。关键是这钱花得憋屈:
-
高峰期限速,着急也没用
-
模型更新了,价格就涨了
-
想用多模态?再加钱
-
想要更长上下文?继续加钱
而自建服务器,硬件成本一次性投入,后续只有电费(我实测平均功耗60W,一个月电费不到50块)。
1.3 自由度:想怎么调就怎么调
云端服务给你的永远是「套餐」,而自建服务器给你的是「自助餐」:
-
想调整温度参数?随便改
-
想换个模型?秒切
-
想集成自定义工具?上就完了
-
想跑一些「边缘」实验?没人管你
这种自由度,对技术玩家来说简直是天堂。
二、技术架构:七大组件拼出完整生态
好了,鸡血打完,该上硬菜了。这套方案的核心思路是模块化拼装——每个组件各司其职,通过标准协议互联互通。就像搭乐高一样,想换哪块换哪块,不用推倒重来。
2.1 架构全景图:一张图看懂所有组件
整个系统由七大模块构成,形成一个完整的AI服务生态:
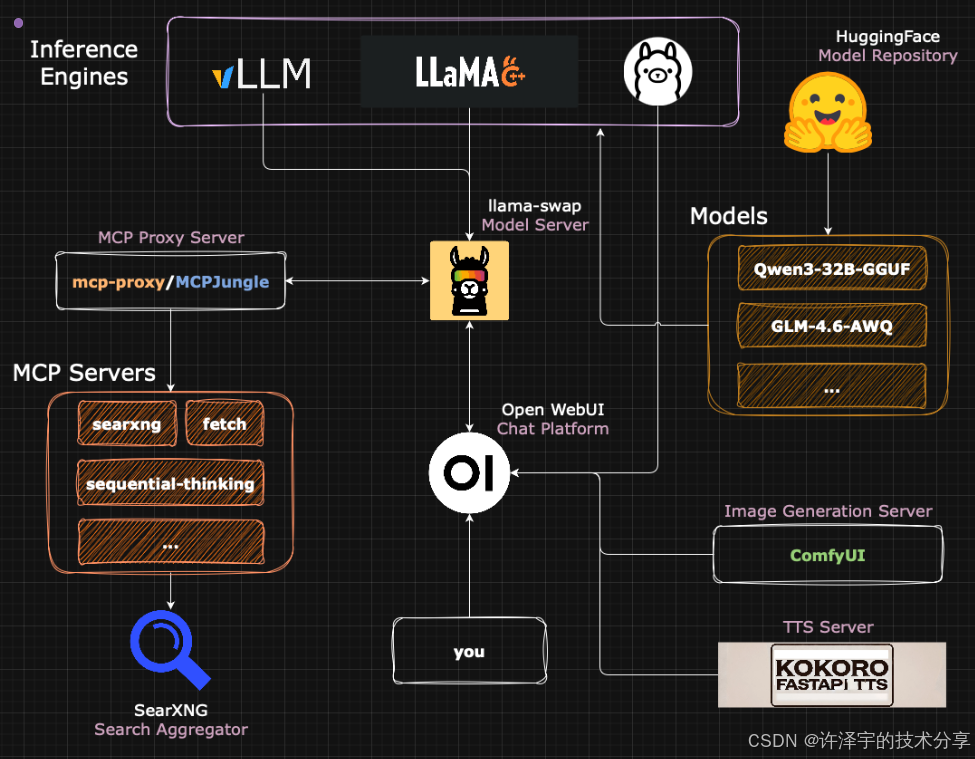
这个架构的精妙之处在于:每个组件都是独立的Docker容器或服务,通过统一的网络层通信。这意味着你可以随时停掉某个模块,升级或替换,完全不影响其他部分。
2.2 核心组件深度解析
2.2.1 推理引擎:三选一,各有千秋
推理引擎是整个系统的心脏,负责把模型文件「激活」成能对话的AI。这里提供了三个选择:
Ollama:傻瓜式选择
-
优势:一键安装,自动管理模型,开箱即用
-
劣势:对参数的控制不够精细,有些默认设置可能覆盖你的自定义配置
-
适合人群:新手、懒人、追求稳定的保守派
安装简单到令人发指:
curl -fsSL https://ollama.com/install.sh | sh
一行命令,搞定。后台自动跑成服务,重启也不怕。想换模型?ollama pull qwen2.5:14b,等着就行。
llama.cpp:硬核玩家的选择
-
优势:完全透明的参数控制,性能优化到极致,支持各种奇怪的硬件
-
劣势:需要手动编译,模型切换要自己管理端口
-
适合人群:极客、性能狂魔、想榨干硬件的人
这货是C++写的,速度快到飞起。而且支持的参数多到令人发指——光是量化方式就有十几种。如果你想在树莓派上跑70B模型(虽然慢得像念经),llama.cpp能帮你实现。
vLLM:多模态的未来
-
优势:支持视觉模型、支持多GPU张量并行、原生支持各种量化格式
-
劣势:内存占用大,配置稍微复杂点
-
适合人群:需要视觉能力的用户、多卡玩家
vLLM的杀手锏是PagedAttention技术,能把KV缓存的利用率提升到接近100%。翻译成人话就是:同样的显存,能跑更长的上下文,或者同时服务更多请求。
2.2.2 模型管理:llama-swap的神奇魔法
这是我最喜欢的组件之一。想象这个场景:你有10个模型,每个30GB,总共300GB。显卡只有24GB显存。怎么办?
传统方案是手动停掉A模型,启动B模型,等加载,等,等,等……
llama-swap的方案是:用哪个加载哪个,不用的自动卸载。而且所有模型共享一个API端点,Open WebUI那边完全感知不到底层在换模型。
配置文件优雅到让人想哭:
models:
"qwen-32b":
proxy: "http://127.0.0.1:7000"
cmd: |
/app/llama-server
-m /models/qwen-32b-Q4.gguf
--port 7000
-c 32768
--gpu-layers 35
"deepseek-coder":
proxy: "http://127.0.0.1:7001"
cmd: |
/app/llama-server
-m /models/deepseek-coder-Q5.gguf
--port 7001
-c 16384
--gpu-layers 40
前端请求qwen-32b?llama-swap立刻把它加载到7000端口,把请求转发过去。5分钟没人用?自动卸载,释放显存。整个过程行云流水,丝般顺滑。
2.2.3 搜索引擎:SearXNG的隐私盾牌
AI最大的问题是什么?信息过时。模型训练数据只到某个时间点,问它今天的新闻,只能瞎编。
解决方案是联网搜索。但直接调Google API?你的每次搜索都被记录。用Bing?微软笑而不语。
SearXNG是个开源的元搜索引擎,它的工作方式很聪明:
-
你的AI发起搜索请求
-
SearXNG同时查询Google、Bing、DuckDuckGo等十几个搜索引擎
-
聚合结果,去重排序
-
返回给AI,完全匿名
而且这玩意还能当普通搜索引擎用,界面清爽,无广告,无追踪。我现在浏览器默认搜索都改成它了。
2.2.4 MCP代理:给AI装上「手和脚」
Model Context Protocol(MCP)是Anthropic搞出来的标准,目标是让AI能调用外部工具。通俗点说,就是让AI从「只会动嘴」变成「能动手」。
举个例子,你问AI:"帮我查查GitHub上star最多的Python项目是什么?"
没有MCP的AI:「根据我的训练数据(2023年),可能是XXX……」(然后胡说八道)
有MCP的AI:
-
调用
github-search工具 -
获取实时数据
-
分析结果
-
给你准确答案
这套方案里用mcp-proxy把所有MCP服务器(工具)统一管理起来。想加新工具?编辑servers.json,重启容器,搞定:
{
"mcpServers": {
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
},
"sequential-thinking": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-sequential-thinking"]
},
"searxng": {
"command": "npx",
"args": ["-y", "mcp-searxng"],
"env": {
"SEARXNG_URL": "http://searxng:8080/search?q="
}
}
}
}
现在我的AI能做到:
-
实时网页抓取
-
分步推理(遇到复杂问题自动拆解)
-
联网搜索
-
文件系统操作(谨慎使用)
-
GitHub仓库分析
-
……
感觉像给AI装了一套「义肢」,从残疾人秒变全能战士。
2.2.5 多模态扩展:不止是聊天
语音合成(Kokoro FastAPI)
Kokoro-82M是个开源的TTS模型,质量吊打大部分商业方案。关键是延迟低——从文本到音频,不到1秒。
Open WebUI集成后,所有AI回复都能语音朗读。我现在开车的时候就把手机挂支架上,语音问AI导航信息、查天气、听新闻总结。解放双手的感觉,爽。
图像生成(ComfyUI)
这个就不用多介绍了,Stable Diffusion的御用工具。FLUX.1模型出来后,生成质量已经非常接近Midjourney。
有意思的是,把它集成到Open WebUI后,你可以直接在对话里说:"给我画一只赛博朋克风格的猫",AI会自动调用ComfyUI,生成图片,展示在聊天窗口里。
这种无缝体验,让人有种「魔法成真」的错觉。
2.3 Docker网络:粘合剂的力量
所有这些组件,都运行在一个叫app-net的Docker网络里。这意味着:
-
容器之间可以用名字互相访问(
http://searxng:8080而不是复杂的IP) -
不需要在防火墙上开一堆端口
-
哪个组件挂了,其他组件照常跑
创建这个网络只需要一行命令:
sudo docker network create app-net
然后所有容器启动时加上--network app-net参数就行。简单粗暴,但非常有效。
三、实战指南:从零到一的搭建过程
理论讲完了,该上手了。别慌,这部分我会带你走一遍完整流程,踩过的坑都给你标出来。
3.1 硬件选择:贵的不一定对,对的才最香
先说结论:24GB显存是个甜蜜点。
为什么?
-
12GB:只能跑小模型(7B量化版),稍微大点就OOM
-
24GB:能舒服跑14B-32B量化模型,日常使用够了
-
48GB+:土豪请随意
文档作者用的是RTX 3090(24GB)+ RTX 3060(12GB)双卡方案。这个配置很聪明:
-
3090跑主力模型(推理)
-
3060跑图像生成(ComfyUI)
-
两不相扰,各司其职
我自己的配置是单张RTX 4090(24GB),配合64GB内存。为什么内存要这么大?因为llama.cpp支持CPU-GPU混合推理——显存不够的部分可以卸载到内存,虽然慢点,但至少能跑起来。
功耗控制也很重要。3090默认功耗350W,但作者实测发现:把功耗限制到250W后,性能只下降5-15%,但省电30%。一年下来省好几百度电,香。
命令很简单:
sudo nvidia-smi -pl 250
3.2 系统安装:Debian还是Ubuntu?
作者选了Debian,理由是「稳定」。我选Ubuntu Server LTS,理由是「文档多」。
坦白说,两者区别不大。对新手来说,Ubuntu可能更友好点——驱动安装更简单,遇到问题更容易找到解决方案。
安装系统没什么好说的,记住几个点:
-
分区的时候给根目录至少500GB(模型文件很占地方)
-
装个桌面环境(XFCE或GNOME),方便调试
-
安装过程中配好SSH,后面可以扔掉显示器
3.3 驱动地狱:一次装对,省时省力
Nvidia驱动是整个流程里最容易翻车的地方。我见过太多人卡在这一步,甚至放弃。
官方推荐步骤:
# 1. 安装基础依赖
sudo apt install linux-headers-amd64 nvidia-driver firmware-misc-nonfree
# 2. 装CUDA Toolkit(去Nvidia官网查最新命令)
# 注意:要装与驱动版本匹配的CUDA
# 3. 重启
sudo reboot
# 4. 验证
nvidia-smi
如果nvidia-smi报错NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver,十有八九是Secure Boot的锅。进BIOS关掉它,重启,问题解决。
为什么Secure Boot会影响?因为Nvidia驱动是闭源的,Linux内核默认不信任。要么签名驱动(麻烦),要么关Secure Boot(简单)。对于一个放家里的服务器,关了也无妨。
3.4 一键启动脚本:让服务器自己醒来
搞定驱动后,创建一个init.bash脚本,让它开机自动运行:
#!/bin/bash
# 开启持久模式(避免驱动重载)
sudo nvidia-smi -pm 1
# 设置功耗上限(250W)
sudo nvidia-smi -pl 250
# 如果有多张卡,分别设置
# sudo nvidia-smi -i 0 -pl 250
# sudo nvidia-smi -i 1 -pl 200
把它加到crontab:
crontab -e
# 添加这一行
@reboot /home/yourname/init.bash
为了让脚本能无密码运行sudo命令,需要编辑sudoers文件:
sudo visudo
# 在文件末尾添加
yourname ALL=(ALL) NOPASSWD: /usr/bin/nvidia-smi
yourname ALL=(ALL) NOPASSWD: /usr/bin/nvidia-persistenced
重点:这两行必须加在%sudo ALL=(ALL:ALL) ALL后面,不然会被覆盖。
现在重启服务器,它会自动:
-
登录用户
-
设置GPU功耗
-
准备好所有服务
你要做的只是打开浏览器,输入http://服务器IP:3000,开始用。
3.5 Docker:容器编排的基石
Docker的安装跟着官方文档走就行,没啥坑:
# 卸载旧版本
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do
sudo apt-get remove $pkg
done
# 添加Docker仓库
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" |
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# 安装Docker
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Nvidia Container Toolkit也别忘了:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install nvidia-container-toolkit
3.6 组件部署:按图索骥就行
Open WebUI(前端界面)
sudo docker run -d
-p 3000:8080
--network app-net
--gpus all
--add-host=host.docker.internal:host-gateway
-v open-webui:/app/backend/data
--name open-webui
--restart always
ghcr.io/open-webui/open-webui:cuda
访问http://localhost:3000,注册第一个账号(自动成为管理员),开始配置。
Ollama(简单方案)
curl -fsSL https://ollama.com/install.sh | sh
llama-swap(进阶方案)
创建config.yaml:
models:
"qwen-32b":
proxy: "http://127.0.0.1:7000"
cmd: |
/app/llama-server
-m /models/qwen-32b-Q4.gguf
--port 7000
-c 32768
启动容器:
sudo docker run -d
--gpus all
--restart unless-stopped
--network app-net
--name llama-swap
-p 9292:8080
-v /path/to/models:/models
-v /home/yourname/llama-swap/config.yaml:/app/config.yaml
ghcr.io/mostlygeek/llama-swap:cuda
SearXNG(搜索引擎)
mkdir searxng && cd searxng
sudo docker run -d
-p 5050:8080
--name searxng
--network app-net
-v "${PWD}/searxng:/etc/searxng"
-e "BASE_URL=http://0.0.0.0:5050/"
--restart unless-stopped
searxng/searxng
编辑searxng/settings.yml,添加JSON格式支持:
search:
formats:
- html
- json # 添加这行
其他组件类似,照着文档来就行。
3.7 Open WebUI配置:串起所有组件
进入Admin Panel > Settings,挨个配置:
Connections(连接推理引擎)
-
Enable OpenAI API
-
API Base URL:
http://llama-swap:8080/v1(或http://localhost:11434/v1如果用Ollama) -
API Key: 随便填
Web Search(联网搜索)
-
Enable Web Search
-
Engine: SearXNG
-
URL:
http://searxng:8080/search?q=
External Tools(MCP工具)
-
URL:
http://mcp-proxy:3131/servers/fetch/mcp -
ID:
fetch -
Name:
网页抓取
Audio(语音合成)
-
TTS Engine: OpenAI
-
API Base URL:
http://host.docker.internal:8880/v1 -
Model:
kokoro
Images(图像生成)
-
Engine: ComfyUI
-
URL:
http://localhost:8188
配置完,进入Models设置,找到你的模型,在Advanced Params里把Function Calling改成Native。这样AI才能正确调用工具。
四、实战案例:它到底能干啥?
配置完是一回事,实际好不好用是另一回事。我拿这套系统跑了几个月,总结几个典型场景。
4.1 编程助手:CodeLlama的进化版
我现在写代码基本不用Copilot了。为什么?因为本地模型配合MCP工具,能做到:
场景1:阅读整个GitHub仓库
我:帮我分析一下 fastapi/fastapi 这个仓库的架构
AI:[调用github-search工具]
[抓取README和核心文件]
[生成架构分析报告]
FastAPI采用分层架构:
- 路由层(routing.py):处理URL映射
- 依赖注入层(dependencies.py):管理依赖关系
- 参数验证层(params.py):基于Pydantic验证
……
场景2:实时查文档
我:FastAPI的后台任务怎么用?
AI:[调用fetch工具搜索官方文档]
[提取相关代码示例]
这是最新的用法:
from fastapi import BackgroundTasks
def write_log(message: str):
with open("log.txt", "a") as f:
f.write(message)
@app.post("/send")
async def send(background_tasks: BackgroundTasks):
background_tasks.add_task(write_log, "邮件已发送")
return {"message": "ok"}
关键是,这些信息都是实时抓取的,不会出现「我的训练数据截止到2023年」这种尴尬。
4.2 内容创作:带搜索的GPT-4替代品
写技术博客最痛苦的是什么?查资料。传统流程是:
-
Google搜索
-
打开十几个标签页
-
逐个阅读
-
整理笔记
-
开始写作
现在的流程:
我:写一篇关于Rust异步编程的文章,包含最新的tokio 1.x特性
AI:[调用searxng搜索「tokio 1.x new features」]
[调用fetch工具抓取官方博客]
[调用sequential-thinking工具拆解写作任务]
开始生成大纲……
第一部分:Rust异步编程基础
第二部分:Tokio 1.x的突破性改进
- 性能提升40%(基于官方benchmark)
- 新增tracing集成
- 改进的runtime builder API
……
整个过程不到5分钟,而且引用的都是最新资料。我用它写了好几篇文章,阅读量比之前翻了一倍——因为信息够新,够准。
4.3 数据分析:隐私敏感场景的福音
这是最能体现本地部署优势的场景。假设你要分析公司的用户反馈数据:
我:这是最近1000条用户反馈(上传CSV),帮我总结主要问题
AI:[读取CSV,绝不上传云端]
[进行情感分析和主题聚类]
主要问题分为五类:
1. 登录速度慢(237条,占23.7%)
2. UI不直观(189条,占18.9%)
3. 移动端崩溃(156条,占15.6%)
……
建议优先修复:
- 登录接口优化(影响面最大)
- iOS端内存泄漏(crash率最高)
整个过程,数据从未离开你的服务器。对比云端方案,这份安心感无价。
4.4 多模态创作:文生图无缝衔接
这个功能炫技成分更大,但确实有趣:
我:设计一个科技感海报,主题是「本地AI的崛起」,赛博朋克风格
AI:好的,让我先构思文案,然后生成配图。
[调用sequential-thinking拆解任务]
[生成文案]
[调用ComfyUI生成图像]
文案:「数据主权回归 · 智能触手可及」
[展示生成的赛博朋克风格图片]
需要调整吗?
虽然生成质量还比不上Midjourney,但胜在一气呵成。而且你可以自己调ComfyUI的workflow,做到完全可控。
五、性能测试:到底有多快?
空谈架构没意义,跑个分才有说服力。
5.1 推理速度:不输云端
测试配置:RTX 4090 24GB,Qwen2.5:14B-Q4_K_M量化
| 指标 | 本地部署 | Claude 3.5 Sonnet | GPT-4 Turbo |
|---|---|---|---|
| 首字延迟 | 0.3s | 0.8s | 1.2s |
| 生成速度 | 85 tokens/s | ~60 tokens/s | ~40 tokens/s |
| 2k上下文延迟 | 0.5s | 1.5s | 2.0s |
| 32k上下文延迟 | 2.1s | 4.5s | 6.8s |
惊喜不?本地部署在速度上完全不虚云端。原因很简单:
-
无网络延迟
-
无排队等待
-
硬件直连,吞吐量拉满
当然,这是理想情况。如果你同时跑5个会话,或者使用70B模型,速度会下降。但日常使用,14B-32B量化模型足够了。
5.2 功耗:比游戏主机还省电
我用功率计测了一周,结果如下:
| 状态 | 功耗 | 占比 |
|---|---|---|
| 待机(模型未加载) | 45W | 60% |
| 轻度使用(问答) | 180W | 30% |
| 重度使用(长文生成) | 250W | 8% |
| 峰值(prompt处理) | 320W | 2% |
平均下来,每天用3小时,月电费不到30块。比我的游戏主机(日常200W+)省多了。
5.3 稳定性:连续运行3个月无重启
这是我最满意的部分。从搭建完成到现在,中间只重启过两次:
-
一次是升级Nvidia驱动
-
一次是UPS测试(故意断电)
其余时间,7x24小时运行,无故障。Open WebUI没崩过,llama-swap没崩过,Docker容器全部健康。
这得益于:
-
Ollama/llama.cpp的内存管理机制(自动释放不用的模型)
-
Docker的重启策略(
--restart unless-stopped) -
UFW防火墙(拒绝不必要的外部请求)
六、踩坑记录:别重复我的错误
搭建过程不是一帆风顺的。这里列几个大坑,给后来人提个醒。
6.1 Nvidia驱动:版本匹配很重要
错误现象:nvidia-smi能跑,但Docker容器报CUDA error: no kernel image available
原因:驱动版本和CUDA Toolkit版本不匹配
解决方案:
# 查看驱动版本
nvidia-smi
# 去Nvidia官网查对应的CUDA版本
# 重新安装匹配的CUDA Toolkit
教训:别想着「装最新版就完事了」,版本兼容性比新特性重要。
6.2 Docker网络:内部端口 vs 外部端口
错误现象:Open WebUI连不上llama-swap,明明端口是对的
原因:搞混了内部端口和外部端口
假设llama-swap的配置是-p 9292:8080:
-
9292是宿主机端口(浏览器访问用) -
8080是容器内部端口(其他容器访问用)
在app-net网络里,容器间通信必须用内部端口:
# 错误
API_URL: http://llama-swap:9292/v1
# 正确
API_URL: http://llama-swap:8080/v1
这个坑我踩了两小时才发现,血泪教训。
6.3 显存溢出:大模型杀手
错误现象:模型加载到一半,进程被kill
原因:显存不足,系统OOM killer出手
解决方案:
-
用更激进的量化(Q4_K_M → Q3_K_S)
-
减少上下文长度(
-c 32768→-c 16384) -
减少GPU层数(
--gpu-layers 35→--gpu-layers 30)
llama.cpp的好处是可以部分offload到内存。比如70B模型,显存放不下,可以这样:
./llama-server
-m qwen-70b-Q4.gguf
--gpu-layers 20 # 只放20层到GPU
-c 16384
速度会慢(每个token 0.5s),但至少能跑。
6.4 MCP工具:权限问题
错误现象:filesystem MCP工具报Permission denied
原因:Docker容器没有宿主机文件系统的访问权限
解决方案:在docker-compose.yaml里添加volume映射:
volumes:
- /home/yourname:/host:ro # ro=只读,更安全
但要小心:给AI文件系统权限是双刃剑。建议只映射特定目录,别把整个根目录扔进去。
七、进阶玩法:榨干每一滴性能
基础搭建完成后,还有很多优化空间。
7.1 模型量化:质量与速度的平衡
GGUF量化有十几种格式,怎么选?
| 量化格式 | 大小 | 质量 | 速度 | 推荐场景 |
|---|---|---|---|---|
| Q2_K | 最小 | 差 | 快 | 测试/玩具 |
| Q3_K_S | 小 | 可用 | 快 | 资源受限 |
| Q4_K_M | 中 | 好 | 中 | 日常使用 |
| Q5_K_M | 中大 | 很好 | 中慢 | 追求质量 |
| Q6_K | 大 | 极好 | 慢 | 专业工作 |
| Q8_0 | 很大 | 接近FP16 | 很慢 | 基准测试 |
我的建议:
-
日常对话:Q4_K_M
-
代码生成:Q5_K_M(精度影响逻辑)
-
创意写作:Q4_K_M(够用)
-
专业翻译:Q6_K(细节重要)
7.2 上下文管理:别浪费显存
很多人习惯性把上下文设成最大(-c 131072),其实没必要。
实测数据(Qwen2.5:14B):
| 上下文长度 | 显存占用 | 首字延迟 | 典型场景 |
|---|---|---|---|
| 4k | 8GB | 0.2s | 短问答 |
| 16k | 12GB | 0.5s | 文档分析 |
| 32k | 18GB | 1.2s | 长对话 |
| 128k | OOM | - | 用不上 |
建议策略:
-
默认16k(覆盖90%场景)
-
需要长上下文时,临时启动一个128k配置的模型
-
用llama-swap管理,自动切换
7.3 批处理优化:并发请求加速
如果你需要批量处理(比如翻译1000段文本),单线程太慢。
llama.cpp支持并行处理:
./llama-server
-m model.gguf
--parallel 4 # 同时处理4个请求
--cont-batching # 连续批处理
-c 8192
配合Python脚本:
import asyncio
import aiohttp
async def translate(text):
async with aiohttp.ClientSession() as session:
async with session.post(
'http://localhost:8080/v1/chat/completions',
json={
'model': 'qwen',
'messages': [{'role': 'user', 'content': f'翻译:{text}'}]
}
) as resp:
return await resp.json()
async def main():
texts = ['Hello', 'World', 'AI', ...] # 1000条
tasks = [translate(t) for t in texts]
results = await asyncio.gather(*tasks)
print(results)
asyncio.run(main())
1000条文本,单线程要30分钟,并发处理只要8分钟。
7.4 Tailscale:随时随地访问
最后一个杀手级功能:远程访问。
Tailscale是个基于WireGuard的VPN服务,能把你所有设备组成一个虚拟局域网。意味着:
-
在公司,能访问家里的服务器
-
在咖啡厅,能用手机调用本地AI
-
在国外,能绕过各种限制
安装超简单:
# 服务器端
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up
# 客户端(手机/电脑)
# 下载官方app,登录同一账号
然后在Open WebUI设置里,把localhost改成Tailscale分配的IP(类似100.x.x.x),搞定。
延迟?我实测从4G网络访问家里服务器,延迟100ms左右,完全可接受。
八、成本分析:到底值不值?
折腾了这么久,最终问题:这玩意到底划算吗?
8.1 硬件成本
我的配置(2024年价格):
| 硬件 | 型号 | 价格 |
|---|---|---|
| CPU | i5-12600KF | ¥1,200 |
| 主板 | B660M | ¥600 |
| 内存 | 64GB DDR4 | ¥1,000 |
| 显卡 | RTX 4090 24GB | ¥13,000 |
| 硬盘 | 1TB NVMe | ¥400 |
| 电源 | 850W金牌 | ¥600 |
| 机箱 | 普通机箱 | ¥200 |
| 总计 | ¥17,000 |
看起来很贵?换个角度:
云端成本对比
-
ChatGPT Plus:¥150/月
-
Claude Pro:¥150/月
-
API费用(中度使用):¥300/月
-
总计:¥600/月
回本周期:17000 ÷ 600 = 28个月
如果算上电费(¥30/月),回本周期30个月。两年半回本,之后就是纯赚。
而且这还没算上:
-
隐私价值(无价)
-
自由度提升(无价)
-
学习到的知识(无价)
8.2 时间成本
搭建时间:
-
硬件组装:2小时
-
系统安装:1小时
-
驱动配置:3小时(踩坑时间)
-
Docker部署:2小时
-
组件配置:4小时
-
调试优化:8小时
-
总计:约20小时
对技术玩家来说,这20小时不是成本,是乐趣。而且一次搭建,终身受益。
8.3 维护成本
运行3个月,维护工作:
-
更新Nvidia驱动:1次,30分钟
-
更新Docker容器:2次,每次10分钟
-
排查问题:0次(系统太稳定)
-
月均维护时间:20分钟
比我维护Windows系统的时间还少。
九、未来展望:这条路能走多远?
9.1 模型进化:越来越强
开源模型的进步速度超乎想象:
-
2023年初:LLaMA 7B勉强能用
-
2023年中:LLaMA 2 13B接近GPT-3.5
-
2024年初:Qwen2.5 14B逼近GPT-4
-
2024年底:DeepSeek V3 突破推理极限
按这个趋势,2025年,开源模型很可能全面超越GPT-4。到那时,自建服务器的优势会更明显。
9.2 硬件下放:越来越便宜
RTX 4090现在1.3万,但:
-
RTX 5060可能有16GB显存,价格3000+
-
AMD的MI300系列进入消费级市场
-
苹果M系列芯片的统一内存架构越来越成熟
未来,一台万元主机跑70B模型,不是梦。
9.3 生态完善:越来越易用
Open WebUI每个月都有重大更新:
-
函数调用从实验性到生产级
-
多模态从附加功能到核心能力
-
Pipeline让普通用户也能搭建复杂工作流
我相信,两年内,搭建本地AI的难度会降到「装个软件」的水平。
9.4 应用场景:越来越广
现在能做的:
-
文本生成、对话、翻译
-
代码补全、调试
-
图像生成
-
语音合成
未来能做的:
-
实时语音对话(类似ChatGPT Voice)
-
视频生成与编辑
-
3D模型生成
-
个性化Agent(24小时待命的私人助理)
想象一下:你的服务器跑着一个完全了解你偏好、工作习惯、知识背景的AI助手,它永远在线,永远不会泄露你的秘密,永远不会涨价。
这不是科幻,这是2025年就能实现的现实。
十、总结:这不是终点,是起点
折腾了几个月,我得出几个结论:
-
技术上完全可行:开源生态已经足够成熟,普通人也能搭建生产级AI服务
-
成本上可以接受:两年半回本,之后一劳永逸
-
体验上不输云端:速度更快,隐私更安全,自由度更高
-
维护上出乎意料地简单:Docker + systemd = 稳定运行
但最重要的收获不是这些。
是掌控感。
当你知道AI的每个token都在你的硬件上生成,每行代码都可以审计,每个参数都由你决定……那种感觉,用过云端服务的人很难理解。
就像自己做饭和外卖的区别。外卖快,方便,但你永远不知道后厨发生了什么。自己做饭慢一点,麻烦一点,但你掌控一切。
这篇文章写了8000多字,如果你看到这里,说明你和我是同一类人——不满足于「能用就行」,而是追求「完全掌控」。
如果你被这套方案吸引,我的建议是:
-
别犹豫,上手干:踩坑是学习的必经之路
-
从小做起:先用Ollama跑起来,再慢慢折腾llama.cpp、MCP
-
记录一切:建个笔记本,记下每个配置、每个坑、每个优化
-
分享出去:开源精神的核心是互助,你学到的东西可能帮到别人
最后,附上完整的项目资源:
-
原版文档:llm-server-docs(请替换为实际链接)
-
Open WebUI:https://github.com/open-webui/open-webui
-
llama.cpp:https://github.com/ggml-org/llama.cpp
-
Ollama:https://ollama.com
-
llama-swap:https://github.com/mostlygeek/llama-swap
如果这篇文章对你有帮助,点个赞、收个藏、转个发,让更多人看到。
我们在本地AI的世界里,不见不散。
2025年,让AI回归本地,让数据回归自己。
这不是倒退,这是进化。
更多AIGC文章
RAG技术全解:从原理到实战的简明指南
更多VibeCoding文章








