


【DBMS学习系列】DBMS(数据库管理系统)的存储模型
一、前置知识
1.1 什么是OLAP 和 OLTP?
On-Line Analytical Processing,简称OLAP(联机分析处理),是一种用于处理大规模数据的技术,它提供了一种灵活的分析和查询方式,能够帮助用户从不同维度来分析和理解业务数据。
On-Line Transaction Processing,简称OLTP(联机事务处理),是一种数据处理类型,包括执行多个并发的事务,例如网上银行、购物、订单处理等。
OLAP和OLTP的主要区别:联机分析处理 (OLAP) 系统的主要用途是分析聚合数据,而联机事务处理 (OLTP) 系统的主要用途是处理数据库事务。
- • 使用 OLAP 系统来生成报告、执行复杂的数据分析和确定趋势。
- • 使用 OLTP 系统来处理订单、更新库存和管理用户账户
OLAP和OLTP的相似之处:都是用于存储和处理大量数据的数据库管理系统,都需要高效可靠的 IT 基础设施才能平稳运行。
1.2 OLAP WorkLoad
OLAP经常对大量的Read-Only数据进行顺序扫描。所以底层的OLAP数据库需要把各个数据条目按照条件筛选出来,然后拼接在一起。
OLAP使用索引来查找数据,不需要顺序扫描。
• 基于树的索引(B+树)用于具有低选择性谓词的查询。
• 需要适应增量更新
1.3 顺序扫描的优化点
• 数据编码/压缩
• 指令预取
• 并行化
• 聚类/排序
• 延迟物化
• 物化视图/结果缓存
• 数据跳过
• 数据并行化/向量化
• 代码特化/编译
二、DBMS的存储模型
DBMS,数据库管理系统。 这里指的比较通用,不区分OLAP数据库,OLTP数据库。
DBMS的存储模型决定了它如何把磁盘和内存里的数据在物理上有效地组织起来。
一般有三种模型:N-ary Storage Model (NSM,行存储)、Decomposition Storage Model (DSM,列存储)、Hybrid Storage Model (PAX,混合存储),前两种是两个方向的极端,第三种PAX是前两种的折中。计算机领域很多方案的设计都是这种折中,权衡的思想。
2.1 N-ary Storage Model (NSM,行存储)
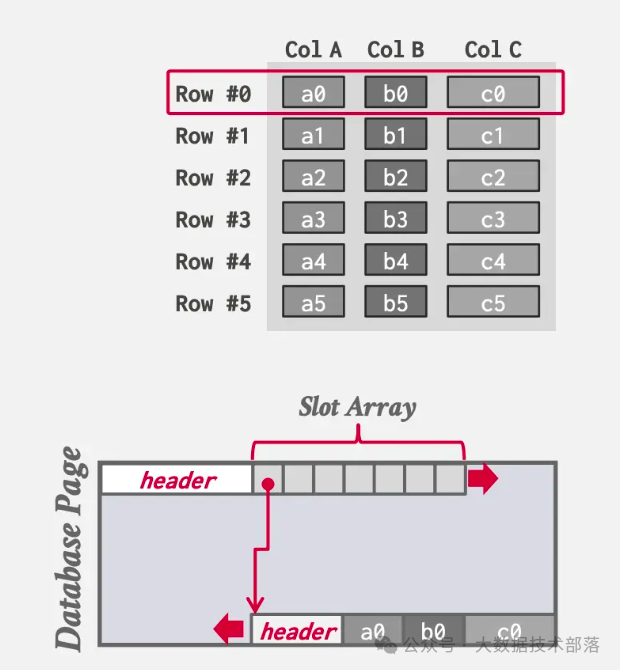
NSM就是我们所说的行存储,DBMS把每个tuple中的所有属性连续的存储在一个Page中。
这样的存储方式对于OLTP这种写操作较多且通常只访问单个的entities来说是非常理想的。
 图片
图片
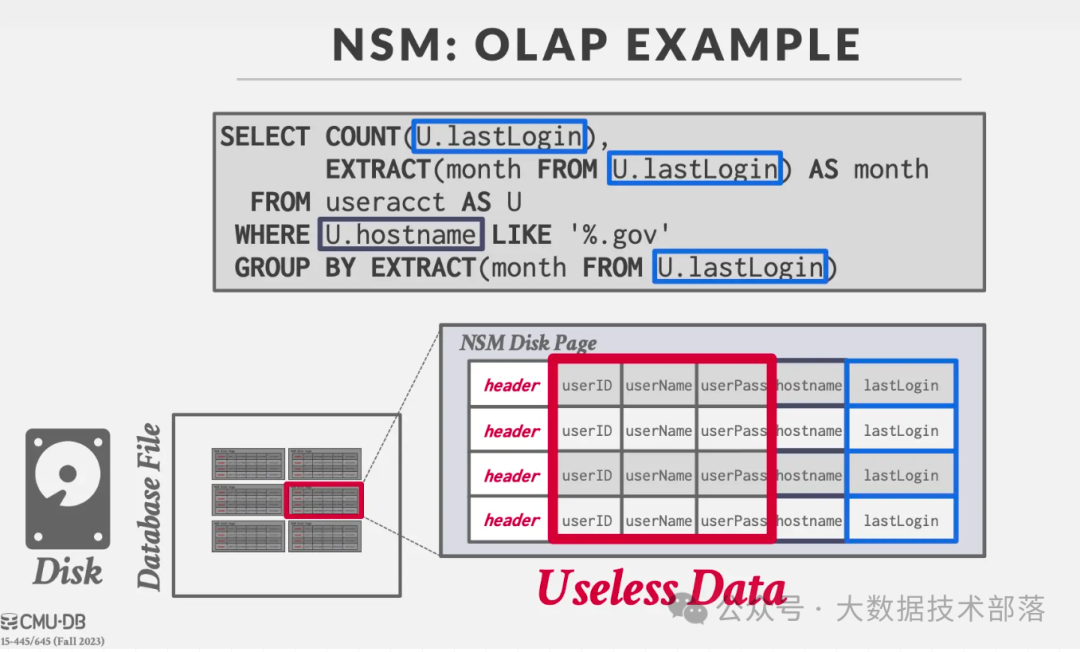
但对于OLAP场景来说,通常只对指定的几个列做分析,这样会导致读取很多无效的数据(不会用到的列的数据也被读出来了),从而影响查询的效率。例如下面的例子:
 图片
图片
因此催生出了列式存储。
2.2 Decomposition Storage Model (DSM,列存储)
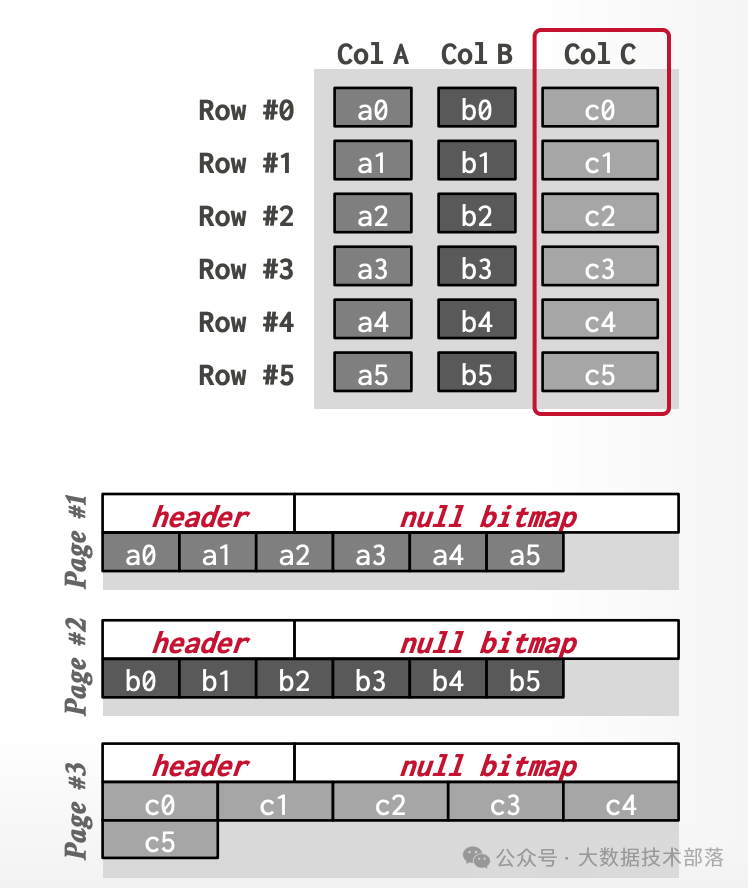
DSM就是我们常说的列存储,在DSM中,DBMS把所有tuples的每个列单独连续的存储在Page中。每个列都维护单独的文件进行存储。
这种存储方式有利于OLAP这种读场景较多且会对某些列进行大量查询的场景。在OLAP场景下,针对某个列进行过滤或聚合时,则只需要读这个列所在的Page就行。
 图片
图片
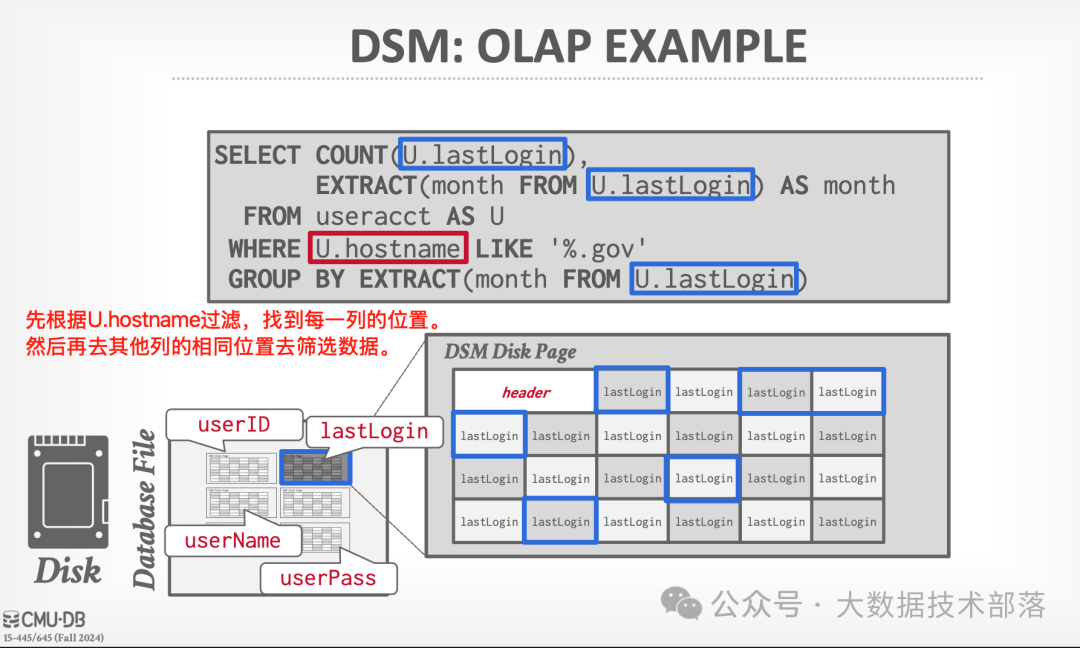
下面是一个DSM在OLAP的例子:关于在不同page里(不同列)属于同一个元组的数据的识别方法有两种,一种是固定长度的偏移(这种可能造成空间浪费,取决于字节数最大的那个值),另一种是变长偏移(借助字典编码方式,工程实现里一般都是采用这种方式)。
 图片
图片
DSM的优缺点如下:
优点:1、减少大量的无效I/O查询。2、查询更快,因为增加了数据本地性和缓存数据复用3、更好的数据压缩(同一列的数据类型一样,一般可以采用某种数据编码方式统一压缩)
缺点:1、点查、插入、更新、删除比较慢,因为有元组的切分、拼接、重组等过程。
2.3 Hybrid Storage Model (PAX,混合存储)
PAX是一种混合存储模型,是行存和列存的一种综合折中存储模型。
它先水平地把元组行切分成多个groups。 然后每个组group内再垂直地把元组的数星切分到列里,它在每个Page中垂直区分保存表的每个属性。 全局元数据目录包含了文件的row group的偏移(例如orc、parquet文件的footer),每一个row group也有自己的元数据header。
采用这种模型的目的是为了既能获得列存的快速处理的高性能又能获得行存的空间本地性优势,Parquet、 ORC、Arrow都是采用的PAX这种存储模式。
示意图如下:
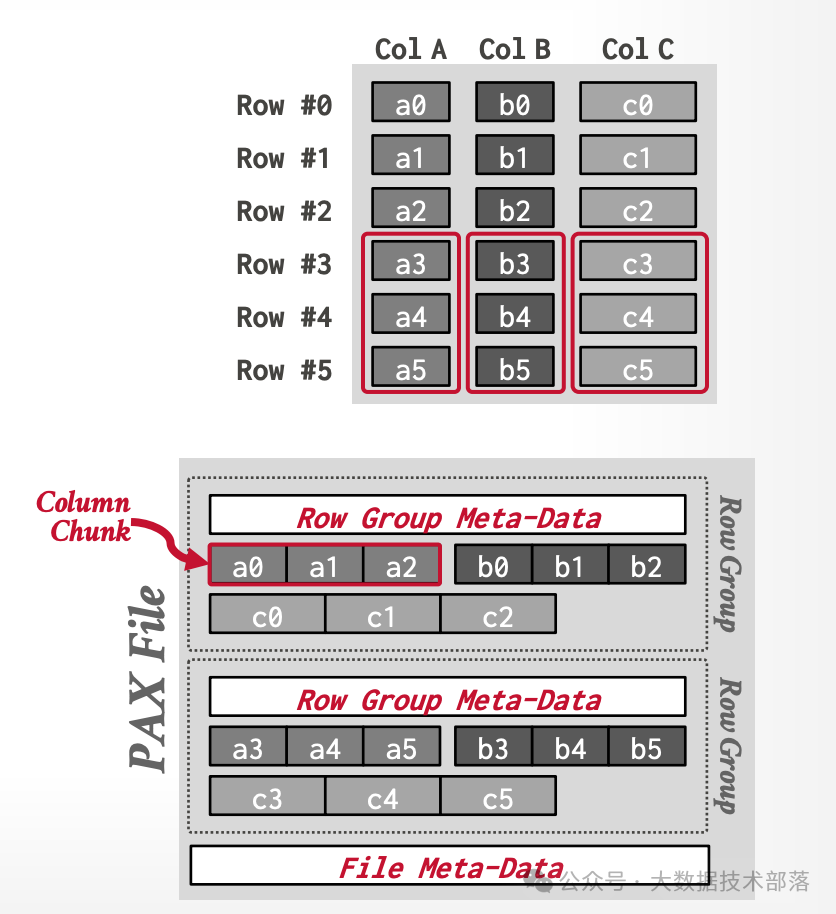 图片
图片
以上就是本文要讲的主要内容。
接下来的1-2个章节会学习关于数据格式(data-format)的设计、 数据压缩等内容。









