


面试官:MySQL表中有2千万条数据,B+树层高是多少?
大家好,我是君哥。
MySQL 默认存储引擎是 InnoDB,跟 MyISAM 相比,InnoDB 支持事务、支持行级锁、支持主键和外键、索引存储上使用 B+ 树。
那如果 MySQL 一张表存储了 2 千万条数据,B+ 树层高是多少呢?今天来聊一聊这个面试题。
InnoDB 存储
在 InnoDB 存储引擎中,是以索引组织表的方式存放数据的,也就是表中数据是根据主键顺序以索引的形式存放的。数据存储在 B+ 树中,每一个索引对应一棵 B+ 树。
我们知道,计算机中,磁盘存储数据的最小单位是扇区,一个扇区大小为 512B。而文件系统的最小单位是块,一个块大小是 4K。
那 InnoDB 具体是以什么单位来存放数据呢?InnoDB 是以页为单位存放数据的,一个页大小是 16K。如下图:
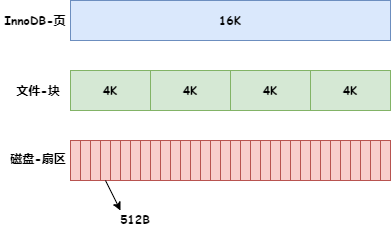
B+ 树索引
跟 MyISAM 不一样的是,InnoDB 使用聚簇索引,叶子节点存储数据,不用独立的行存储。下面是 MyISAM 的存储结构:
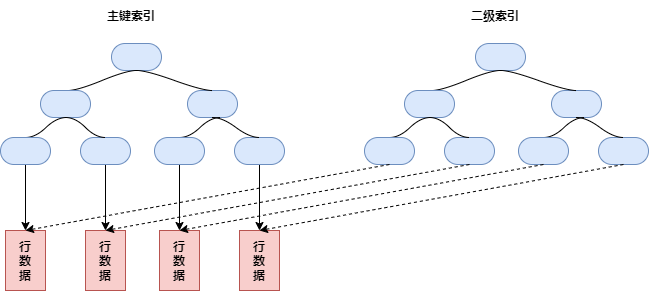
InnoDB 主键索引每个叶节点包含了主键值和所有的剩余字段。二级索引的叶节点中存储是索引键和主键值,以此作为指向行的“指针”。如下图:
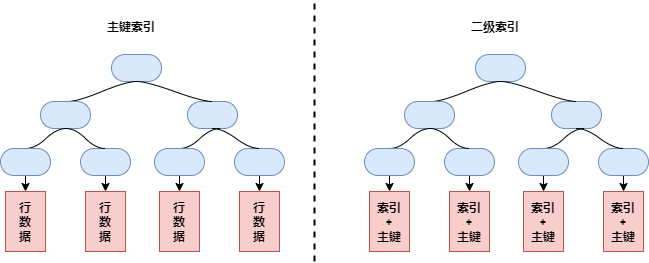
B+ 树叶子节点存储了数据,非叶子节点(索引节点)则存储了 key 和指针。这样存储的优势是可以在索引节点通过二分查找快速找到数据所在页,时间复杂度为 O(log n)。找到数据页后再去数据页中找数据就很容易了。
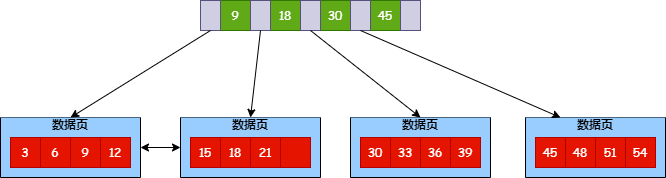
前面讲到,InnoDB 以页为单位来存储数据,每页 16k,那如果一条数据占 1k 的空间,那每页可以存储 16 条数据。
而索引节点保存的是 key 和指针。假如 key 的数据类型是 bigint,占 8B,指针大小在 InnoDB 中固定占 6B,那索引节点占空间大小为 14B,那每页存放的索引节点就是 1170。
16 * 1024B/14B = 1170。
因此假如 B+ 树高度为 2 层,则存放的数据为 1170(页)* 16(每页 16 条数据)= 18720。 同理如果 B+ 树高度为 3 层,则存放的数据为 1170(页)* 1170(每页 1170 索引节点)* 16(每页 16 条数据)= 21902400。
回到问题,一张表中有 2 千万条数据,B+ 树有几层?如果小于等于 21902400 条,则 B+ 树是 3 层,如果大于 21902400,则 B+ 树是 4 层。
注意前提条件,一条数据占用空间大小是 1k,索引节点(索引节点)中 key 占用空间为 8B。
总结
本节以一道经典的面试题,引出了 MySQL 中 InnoDB 的存储结构。理解了这个存储结构,就可以很好的理解索引和数据查找原理了。
本文地址:https://www.yitenyun.com/219.html









