


MySQL 分页查询优化指南
本文以MySQL8为例演示一下分页查询技巧和常见优化思路,希望对你有帮助。

一、业务妥协向的非跳页查询
该问题实际上有两种比较常见的方案,一种是search_after上下翻页查询,如方案名所说,当用户进行上下翻页的时候,永远都是基于本次分页的结果的区间定位上一页和上一页,这也就意味着该查询必须要求用户的数据必须具备有序的字段,例如我们当前查询到id为20~30的数据,基于该方案我们获取下一页的数据就是找到大于30的前10条数据:
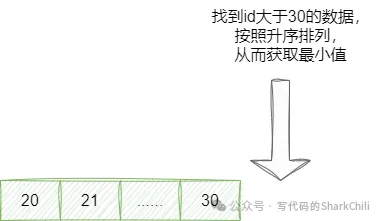
对应的我们也给出这条SQL示例:
-- 下一页(假设id为主键且连续)
SELECT * FROM table
WHERE id > 30
ORDER BY id
LIMIT 10;而查询上一页也是同理,通过当前页码的最小值,定位到上一页的最大值,从而获取上一页的结果区间:
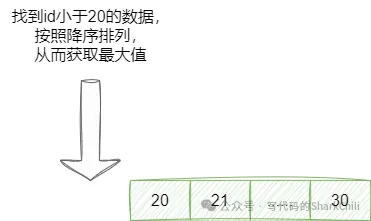 图片
图片
对应的我们也给出这段SQL示例:
-- 上一页(需要前端记录历史游标)
SELECT * FROM table
WHERE id < 20
ORDER BY id DESC
LIMIT 10;二、支持跳页的分页查询SQL
1. 准备测试数据和脚本
为了方便演示笔者,这里拿出一张曾经作为批量插入的数据表,该表差不多有200w左右的数据:
CREATE TABLE`batch_insert_test` (
`id`intNOTNULL AUTO_INCREMENT,
`fileid_1`varchar(100) DEFAULTNULL,
`fileid_2`varchar(100) DEFAULTNULL,
`fileid_3`varchar(100) DEFAULTNULL,
`fileid_4`varchar(100) DEFAULTNULL,
`fileid_5`varchar(100) DEFAULTNULL,
`fileid_6`varchar(100) DEFAULTNULL,
`fileid_7`varchar(100) DEFAULTNULL,
`fileid_8`varchar(100) DEFAULTNULL,
`fileid_9`varchar(100) DEFAULTNULL,
`fileid_10`varchar(100) DEFAULTNULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1DEFAULTCHARSET=utf8mb3 COMMENT='测试批量插入,一行数据1k左右';对应的我们也给出批量插入模拟数据的脚本:
-- 创建临时存储过程执行批量插入
DELIMITER //
CREATEPROCEDURE batch_insert_data()
BEGIN
DECLARE i INTDEFAULT0;
DECLARE batch_count INTDEFAULT1000; -- 每批插入1000条
DECLARE total_rows INTDEFAULT20000000; -- 总插入量200w
-- 显示开始时间
SELECTCONCAT('开始批量插入数据: ', NOW()) AS message;
-- 使用事务提高性能
STARTTRANSACTION;
WHILE i < total_rows DO
-- 构建批量插入语句
SET @insert_sql = 'INSERT INTO batch_insert_test (fileid_1, fileid_2, fileid_3, fileid_4, fileid_5, fileid_6, fileid_7, fileid_8, fileid_9, fileid_10) VALUES ';
-- 生成当前批次的1000条数据
SET @batch_values = '';
SET @j = 0;
WHILE @j < batch_count AND i < total_rows DO
-- 生成随机UUID格式的fileid
SET @uuid = REPLACE(UUID(), '-', '');
-- 添加到批量值
IF @j > 0 THEN
SET @batch_values = CONCAT(@batch_values, ',');
ENDIF;
SET @batch_values = CONCAT(@batch_values,
'("', @uuid, '","', @uuid, '","', @uuid, '","', @uuid, '","', @uuid, '",',
'"', @uuid, '","', @uuid, '","', @uuid, '","', @uuid, '","', @uuid, '")');
SET @j = @j + 1;
SET i = i + 1;
ENDWHILE;
-- 执行批量插入
SET @sql = CONCAT(@insert_sql, @batch_values);
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATEPREPARE stmt;
-- 每插入10万条显示进度
IF i % 100000 = 0 THEN
SELECTCONCAT('已插入: ', i, ' 条记录, 进度: ', ROUND(i/total_rows*100, 2), '%, 时间: ', NOW()) AS progress;
ENDIF;
ENDWHILE;
COMMIT;
-- 显示完成时间
SELECTCONCAT('批量插入完成! 总插入量: ', i, ' 条, 结束时间: ', NOW()) AS message;
END//
DELIMITER ;
-- 执行存储过程
CALL batch_insert_data();
-- 删除临时存储过程
DROPPROCEDUREIFEXISTS batch_insert_data;2. 如何limit检索
按照分页查询公式,查询第N页的sql就是limit (page-1)*size, size,所以笔者对如下几个分页查询进行实验,不难看出,随着分页深度的增加,查询也变得十分耗时:
select * from batch_insert_test bit2 limit 10,10;
select * from batch_insert_test bit2 limit 100,10;
select * from batch_insert_test bit2 limit 1000,10;
select * from batch_insert_test bit2 limit 10000,10;
select * from batch_insert_test bit2 limit 100000,10;
select * from batch_insert_test bit2 limit 1000000,10;
select * from batch_insert_test bit2 limit 5000000,10;查看第500w页的数据10条,花费了将近10s:
select * from batch_insert_test limit 5000000,10;因为查询时没有使用任何索引,所以查询时直接进行完整的table scan即针对整颗聚簇索引树的非空data域进行扫描检索:
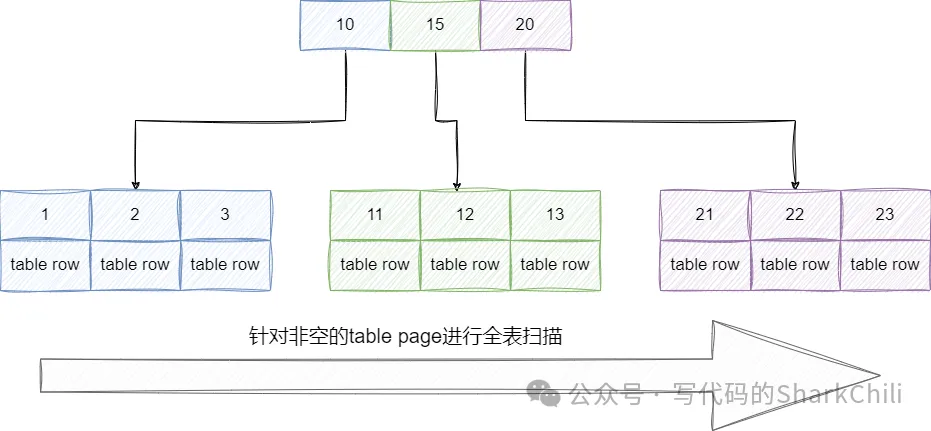
查看其执行计划,可以发现本次查询走了全表扫描,性能表现非常差劲:
id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows |filtered|Extra|
--+-----------+-----+----------+----+-------------+---+-------+---+-------+--------+-----+
1|SIMPLE |batch_insert_test | |ALL | | | | |9004073| 100.0| |所以我们需要对这些SQL进行改造,因为笔者这张表是以有序自增id作为主键的,所以我们可以很好的利用这一点,通过定位当前页的第一个id,然后通过这个id筛选对应页的数据:
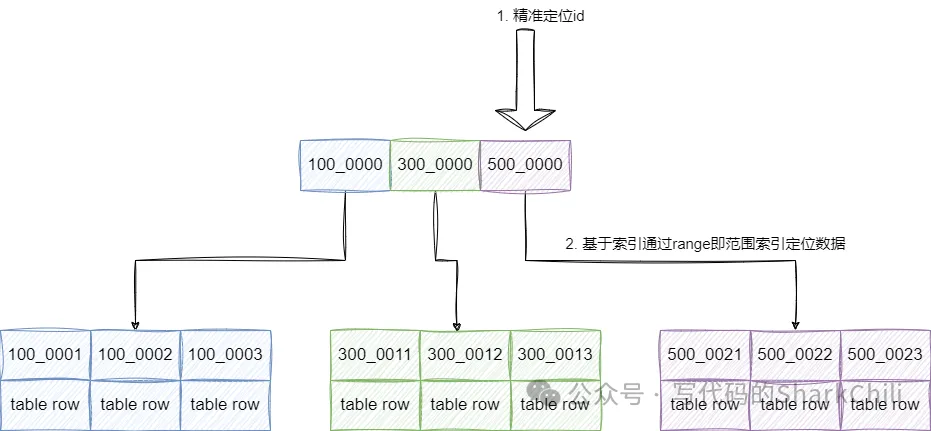
对应SQL如下所示,经过笔者的实验耗时大约在500ms左右:
select
*
from
batch_insert_test
where
id >=(select id from batch_insert_test bit2 limit 5000000,1)
limit 10;查看这条sql的执行计划可以发现,这条sql是直接通过索引直接定位id,避免走向叶子节点直接返回,再通过走索引的方式进行范围查询性能提升了不少。
id|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows |filtered|Extra |
--+-----------+-----+----------+-----+-------------+-------+-------+---+-----+--------+------------------------------+
1|PRIMARY | | | | | | | | | |no matching row in const table|
2|SUBQUERY |bit2 | |index| |PRIMARY|4 | |38677| 100.0|Using index |当然,我们也可以通过子查询的方式先定位到索引区间,然后再和查询的表进行关联完成检索,性能表现也差不多,这里不多做赘述了:
select
b1.*
from
batch_insert_test b1
innerjoin (
select
id
from
batch_insert_test
limit5000000,
10) as b2 on
b1.id = b2.id;3. limit量级多少合适
接下来就是limit数据量的选择了,有些读者可能为了方便直接在业务上进行改造,一次性查询大几十万数据给用户。 可以看到随着数据量的增加,查询耗时主键增大,所以读者在进行这方面考虑的时候务必要结合压测,根据自己业务上所能容忍的延迟涉及最大的pageSize,以笔者为例大约10w条以内的数据查询性能差异是不大的(上下相差200ms左右):
select * from batch_insert_test bit2 limit 1000000,10;
select * from batch_insert_test bit2 limit 1000000,100;
select * from batch_insert_test bit2 limit 1000000,1000;
select * from batch_insert_test bit2 limit 1000000,10000;
select * from batch_insert_test bit2 limit 1000000,100000;
select * from batch_insert_test bit2 limit 1000000,1000000;
select * from batch_insert_test bit2 limit 1000000,10000000;4. 减少查询的字段
还有一点细节上的优化,MySQL的基本单位是页,所以每次查询都是以页为单位进行查询,所以高效的查询也要求我们用尽可能少的块查到存储尽可能多的数据,所以查询时我们建议没有用到的列就不要查询来了。
以笔者为例,只需用到3个字段,则直接将*改为了id,fileid_1 ,fileid_4
select
id,fileid_1 ,fileid_4
from
batch_insert_test bit25. 利用索引覆盖
延迟关联查询法在若带有通过其它字段进行分页查询或者排序时,我们务必针对该字段创建一个索引,假设我们要查询19001页的数据,对应的SQL如下所示:
select
id,fileid_1 ,fileid_4,fileid_8
from
batch_insert_test
order by fileid_8 limit 190000,10;假设分页查询有一个limit_count记录分页偏移量,如果file_8没有创建索引,这条查询的执行过程为:
- 进行全表扫描,并基于filesort完成数据排序
- 基于排序结果扫描到第一条符合要求的数据返回给server层。
- 此时server层发现limit_count为0,即没有完成跳跃筛选的工作,故舍弃这条记录,limit_count++。
- 重复步骤2执行190000次。
- 步骤4完成后,返回10条完整的记录给客户端。
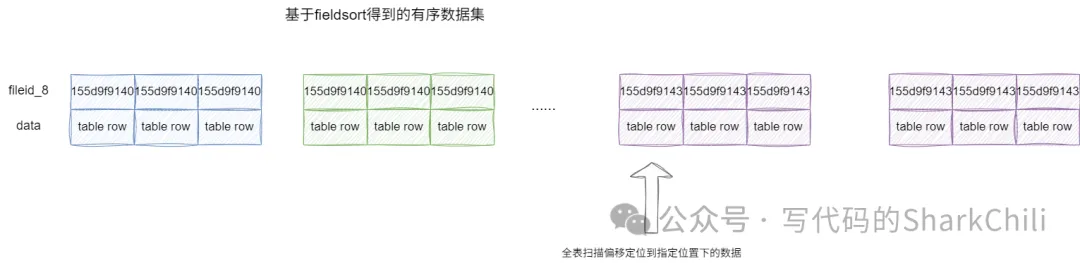
因为涉及文件排序和全表扫描,所以这条SQL的查询表现比较差劲,查询耗时为1m39s ,对应的我们也给出相应的执行计划印证:
id|select_type|table |partitions|type|possible_keys|key|key_len|ref|rows |filtered|Extra |
--+-----------+-----------------+----------+----+-------------+---+-------+---+--------+--------+--------------+
1|SIMPLE |batch_insert_test| |ALL | | | | |19554981| 100.0|Using filesort|所以在此基础上,我们会考虑在fileid_8 上增加一个索引,为后续的优化做铺垫:
CREATE INDEX batch_insert_test_fileid_8_IDX USING BTREE ON db.batch_insert_test (fileid_8);有了索引之后,使用二级索引进行排序,查询耗时变为400ms,但这还不够,原因很简单,通过下述的SQL很好的利用二级索引完成排序,但是检索数据时整体过程还是:
- 基于二级索引完成排序
- 基于排序结果扫描到第一条符合要求,通过回表定位到完整的数据返回给server层
- 此时server层发现limit_count为0,即没有完成跳跃筛选的工作,故舍弃这条记录,limit_count++。
- 重复步骤2和步骤3执行190000次。
- 步骤4完成后,返回10条完整的记录给客户端。
因为二级索引b+树记录的是索引和主键的映射,若需要投影其它字段,还需要经过回表这一步:
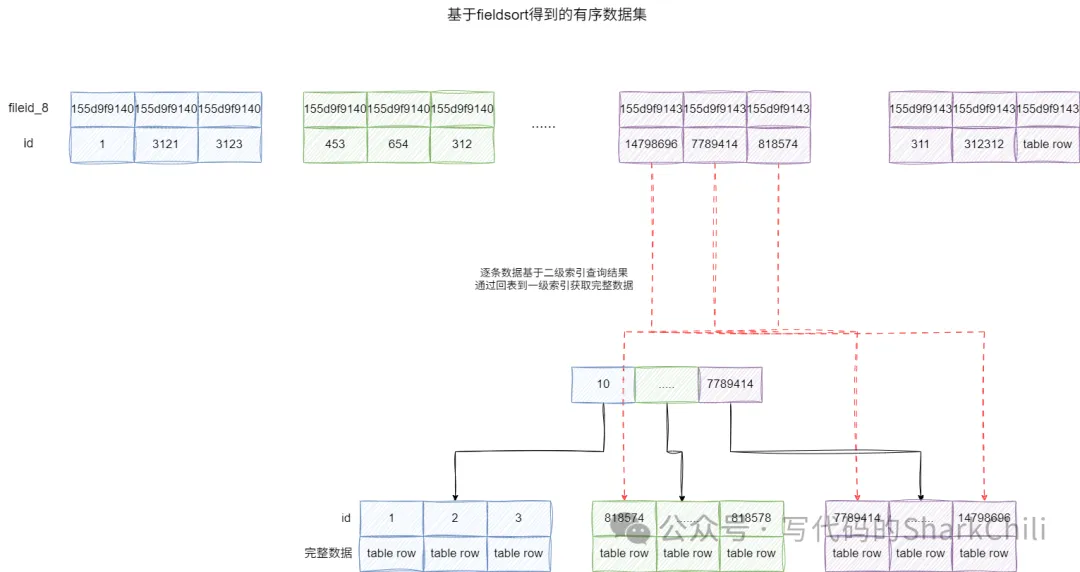
对应的我们也给出执行计划:
id|select_type|table |partitions|type |possible_keys|key |key_len|ref|rows |filtered|Extra|
--+-----------+-----------------+----------+-----+-------------+------------------------------+-------+---+------+--------+-----+
1|SIMPLE |batch_insert_test| |index| |batch_insert_test_fileid_8_IDX|303 | |190010| 100.0| |因为我们基于fileid_8创建了二级索引,所以我们可以借助MySQL中索引覆盖的特性,在排序时通过扫描二级索引定位到主键索引区间,并基于这个主键区间一次性到聚簇索引树上获取所有数据,避免多次回表的开销。
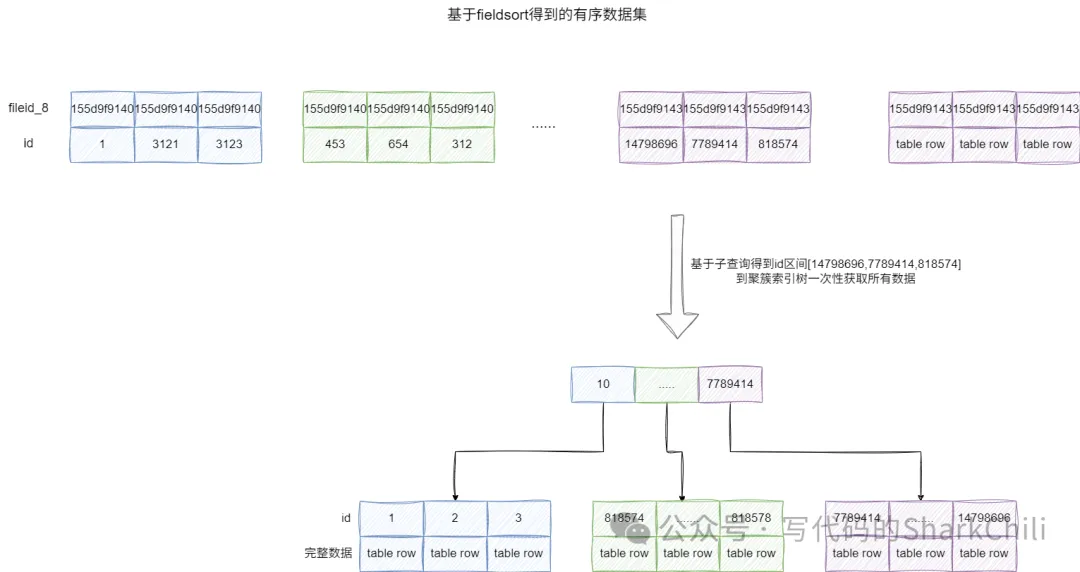
对应的我们给出下面这条SQL,需要注意的是MySQL默认语法不允许in直接和子查询的select id 子句一起使用,若使用该语句则会抛出This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery';异常,所以笔者对应的SQL上增加了将select id这个子查询结果构建成一张只有id的虚表t1和外部关联:
select
id,
fileid_1 ,
fileid_4,
fileid_8
from
batch_insert_test
WHERE
idIN ( SELECT t1.id from ( selectidfrom batch_insert_test sub orderby fileid_8 limit190000,10) as t1);对应查询结果一下子优化至20ms,从执行结果上可以看出:
- 子查询直接Using index直接拿到主键,虽然评估扫描大约是190010,但是避免了回表,性能较为可观。
- 主表batch_insert_test通过聚簇索引id和被驱动表t1直接关联,快速得到数据。

三、小结
来简单小结一下,本文通过一张大表结合一个分页查询的场景为读者演示的大表分页查询的技巧,整体来说,针对大表查询时,我们的SQL优化要遵循以下几点:
- 尽可能利用索引,确保用最小的开销得到索引。
- 结合业务场景和服务器性能压测出最合适的limit数据量。
- 尽量不要查询没必要的列。
- 利用好索引覆盖避免回表的开销。









