


Redis背后的神奇力量:为何它如此高效?
Redis的速度快主要有以下几个原因:
 图片
图片
1、基于内存操作
Redis的操作都是基于内存的,数据存储在内存中,而内存的读写速度远远快于硬盘,内存的运行速度比硬盘高出几个数量级,就像从翻阅书籍变成即刻在线信息查询,访问时间大幅缩短。
 图片
图片
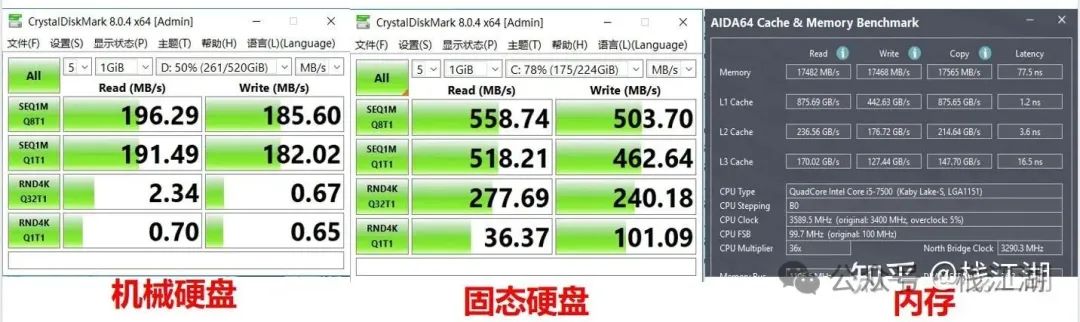
p.s.CrystalDiskMark测试不了内存,所以使用其它工具测试内存,虽然测试方式及纬度不同,但结果还是可以参考看的。
机械硬盘、固态硬盘及内存的读写速度有以下对比:
- 机械硬盘:机械硬盘的读写速度相对较慢,通常在100 MB/s到200 MB/s之间,具体取决于磁盘的转速和技术规格。
- 固态硬盘:固态硬盘的读写速度远远快于机械硬盘。一般而言,SSD的读速度可以达到数百 MB/s至数千 MB/s,而写速度也在同样的范围内。
- 内存: 内存的读写速度远远超过硬盘,通常在GB/s级别。内存读写速度可以达到几千 MB/s,甚至更高。
当然在Redis官网还提到了“Redis on Flash”
官方文档:
 图片
图片
"Redis on Flash" 是指将 Redis 数据存储在闪存(Flash Storage)上,而不是传统的随机访问存储器(RAM)上。这种做法通常被用于处理大规模的数据集,因为闪存的存储容量通常比RAM大得多。
2、单线程模型
官方文档:
 图片
图片
 图片
图片
可以看到官方文档:1、Redis的单线程特性2、Redis 的性能瓶颈通常出现在内存或网络方面,而不是 CPU 方面。
虽然 Redis 官方 FAQ 没有明确解释 Redis 单线程设计的原因,但确实在文档中指出 Redis 的性能瓶颈通常出现在内存或网络方面,而不是 CPU 方面。
Redis的工作负载主要涉及内存操作和网络通信,而不是 CPU 密集型计算,因此 CPU 通常并不是 Redis 性能的瓶颈。在大多数情况下,性能瓶颈可能更多地出现在内存访问速度或网络带宽上,这也是 Redis 在内存和网络方面进行优化的原因。
Redis的主线程是单线程的,所有操作都得按顺序执行,避免了多线程带来的额外开销和复杂性。 这种设计使得 Redis 在处理许多短期和高频的读写操作时非常高效,特别适合缓存和实时数据存储的应用场景。总结以下几点:
- Redis的工作负载主要涉及内存操作和网络通信,而不是 CPU 密集型计算,因此 CPU 通常并不是 Redis 性能的瓶颈。
- Redis 的大部分操作都是对内存的读写操作,这些操作的速度非常快。多线程模型可以提高并发性,但对于内存操作,并发性并不重要。
- 多线程模型会带来额外的开销和复杂性。例如,多线程需要进行线程调度、线程同步等操作,这些操作会占用 CPU 资源,并增加程序的复杂性。
3、I/O多路复用技术
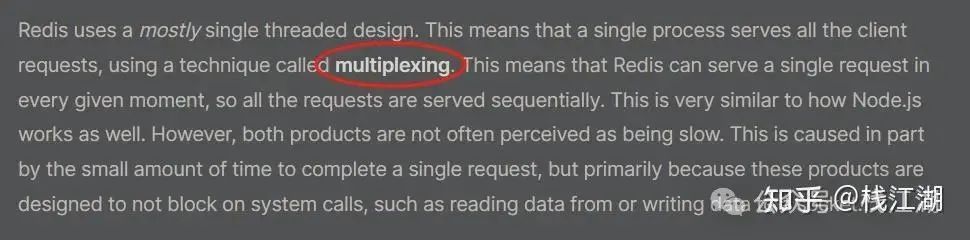
官方文档:
 图片
图片
 图片
图片
可以看到Redis官方文档多处提到的“multiplexing and non-blocking I/O”。那么什么是multiplexing and non-blocking I/O呢?I/O 多路复用技术是指一个线程可以同时监视多个I/O)操作。当某个 I/O 操作就绪时,操作系统会通知该线程。
I/O 多路复用技术可以有效地提高 I/O 效率。传统的 I/O 模型中,一个线程只能执行一个 I/O 操作。当该 I/O 操作阻塞时,该进程或线程将无法执行其他操作,这会导致 CPU 资源的浪费。
Redis采用I/O多路复用技术,并发处理连接,使得整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来。
如果以上说明看着费力可以看看以下内容:
I/O多路复用=餐厅服务员记录订单
假设一家忙碌的餐厅服务员,负责接待顾客点餐和为他们服务。如果每次只能处理一个桌子的订单,那就太浪费时间了?如果同时处理多个桌子的订单,先把每个桌子上的点餐需求一个个记在心里,然后再去后厨逐个去处理。当有一个桌子的顾客在思考菜单时,你可以去另一个桌子送菜,再回来接着处理点餐。这样,你可以在等待一个桌子的订单时,同时为其他桌子服务,提高了效率。
4、高效的数据结构
Redis使用了高效的数据结构,如简单动态字符串、压缩列表、跳跃表等,这些数据结构为了追求更快的速度。
简单动态字符串(SDS):
SDS 是 Redis 中用来表示字符串的数据结构。它是一种动态调整大小的字符串类型,可以高效地进行字符串的追加、删除和修改操作。
SDS 在内部包含字符串长度信息,使得获取字符串长度的操作更为高效。而且,SDS 的空间分配策略和惰性空间释放使得对字符串的修改操作更加迅速。
压缩列表:
压缩列表是一种用于存储列表数据的紧凑数据结构。它可以在节约内存的同时,提供对列表元素的快速访问。压缩列表会根据元素的大小动态地调整内存占用。
压缩列表采用了灵活的内存布局,可以存储不同类型的元素,并在某些情况下采用整数编码,进一步减小存储空间。
跳跃表:
跳跃表是一种有序的数据结构,用于实现有序集合和有序映射。它通过层级的链表结构,实现了快速的元素查找、插入和删除。
跳跃表通过在多个层次上建立索引,可以在O(log N)的时间内完成查找等操作,其中 N 是元素的数量。它是一种高效的有序数据结构,相较于平衡树,跳跃表的实现更加简单。
5、额外优化
Redis 通过数据压缩、惰性加载(仅在需要时加载数据)、内存淘汰(主动清除鲜少使用的数据释放空间)等技术进一步提升速度。这些精细的调优措施促成一个运转顺畅、反应灵敏的系统。









