


快速恢复数据的六种方案
前言
最近星球中有位小伙伴说:他不小心把测试环境MySQL表中所有数据都误删了,问我要如何快速恢复?
幸好他误删的是测试环境,非生产环境。
我遇到过,之前有同事把生产环境会员表中的数据误删除的情况。
这篇文章跟大家一起聊聊MySQL如果误删数据了,要如何快速恢复。
一、为什么数据恢复如此重要?
2023年某电商平台误删20万用户数据,导致直接损失800万。
某金融机构DBA误执行DROP TABLE,系统停摆6小时。
这些事故背后,暴露的是误删数据之后恢复方案的缺失。
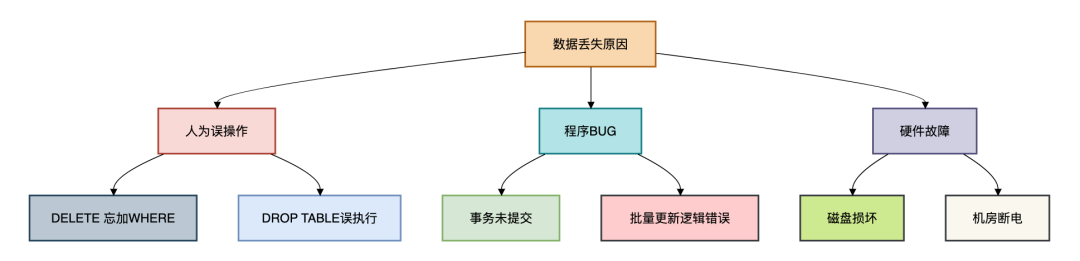
数据丢失的三大元凶
- 人为误操作(占75%):
DELETE忘加WHERE、DROP TABLE手滑 - 程序BUG(占20%):循环逻辑错误、事务未回滚
- 硬件故障(占5%):磁盘损坏、机房断电
下面是数据丢失的主要原因:
 图片
图片
那么,如果MySQL如果误删数据了,快速恢复数据的方案有哪些呢?
二、常见的数据恢复方案
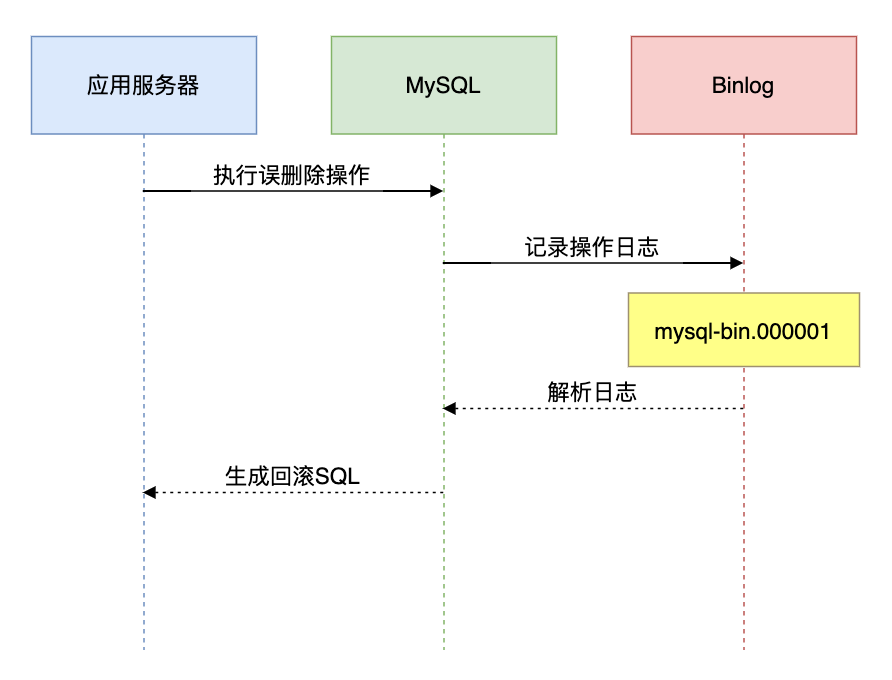
方案1:Binlog日志恢复
该方案最常用。
适用场景:误执行DELETE、UPDATE
恢复流程:
 图片
图片
操作步骤:
- 定位误操作位置
mysqlbinlog --start-datetime="2023-08-01 14:00:00"
--stop-datetime="2023-08-01 14:05:00"
mysql-bin.000001 > /tmp/err.sql- 提取回滚SQL(使用python工具)
# parse_binlog.py
import pymysql
from pymysqlreplication import BinLogStreamReader
stream = BinLogStreamReader(
connection_settings = {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"passwd": "root"},
server_id=100,
blocking=True,
resume_stream=True,
only_events=[DeleteRowsEvent, UpdateRowsEvent])
for binlogevent in stream:
for row in binlogevent.rows:
if isinstance(binlogevent, DeleteRowsEvent):
# 生成INSERT语句
print(f"INSERT INTO {binlogevent.table} VALUES {row['values']}")
elif isinstance(binlogevent, UpdateRowsEvent):
# 生成反向UPDATE
print(f"UPDATE {binlogevent.table} SET {row['before_values']} WHERE {row['after_values']}")- 执行恢复
python parse_binlog.py | mysql -u root -p db_name方案2:延迟复制从库
该方案是金融级的方案。
适用场景:大规模误删数据
架构原理:
 图片
图片
配置步骤:
- 设置延迟复制
STOP SLAVE;
CHANGE MASTER TO MASTER_DELAY = 1800; -- 延迟30分钟(1800秒)
START SLAVE;- 误删后立即停止同步
STOP SLAVE;- 将延迟从库提升为主库
RESET SLAVE ALL;
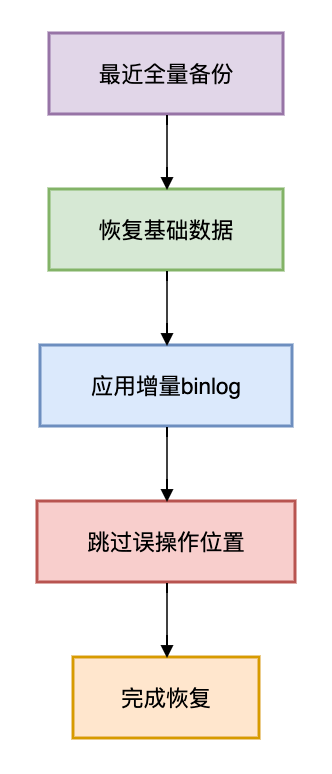
SHOW MASTER STATUS; -- 记录binlog位置方案3:全量备份+增量恢复
适用场景:整表或整库误删
恢复流程:
 图片
图片
操作步骤:
- 恢复全量备份
mysql -u root -p db_name < full_backup_20230801.sql- 应用增量日志(跳过误操作点)
mysqlbinlog --start-positinotallow=100 --stop-positinotallow=500
mysql-bin.000001 | mysql -u root -p方案4:Undo日志恢复
该方案是InnoDB特有的。
适用场景:刚提交的误操作(事务未关闭)
核心原理:
 图片
图片
操作步骤:
- 查询事务信息
SELECT * FROM information_schema.INNODB_TRX;- 定位Undo页
SHOW ENGINE INNODB STATUS;- 使用undrop-for-innodb工具
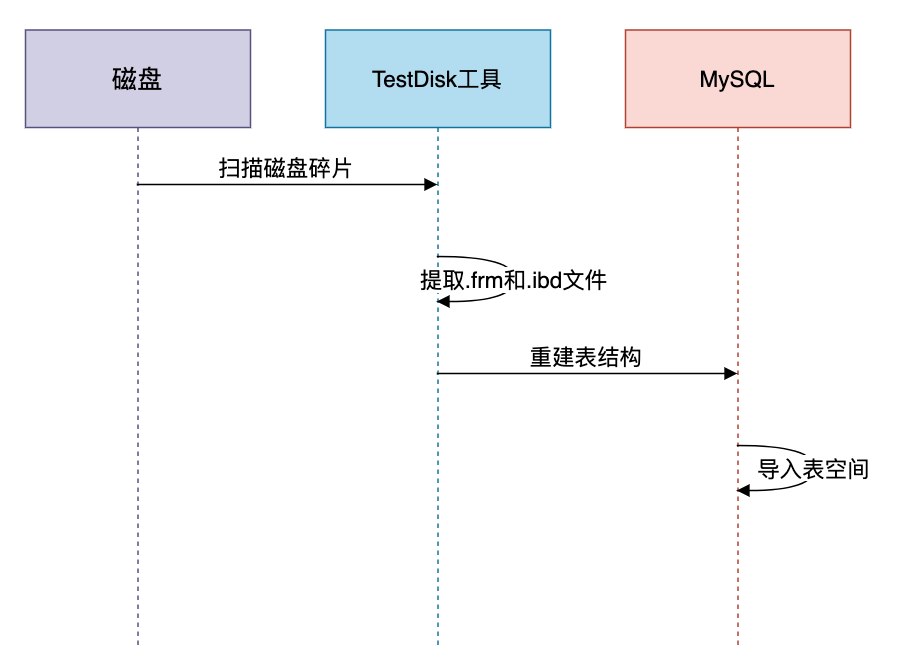
./undrop-for-innodb/system_parser -t user_data /var/lib/mysql/ibdata1方案5:文件恢复
从物理备份中恢复,需要提前做备份。
适用场景:DROP TABLE误操作
恢复流程:
 图片
图片
操作步骤:
- 安装恢复工具
yum install testdisk -y- 扫描磁盘
photorec /dev/sdb1- 重建表结构
CREATE TABLE user_data (...) ENGINE=InnoDB;- 导入表空间
ALTER TABLE user_data DISCARD TABLESPACE;
cp recovered.ibd /var/lib/mysql/db_name/user_data.ibd
ALTER TABLE user_data IMPORT TABLESPACE;方案6:云数据库快照恢复
适用场景:阿里云RDS、AWS RDS等云服务
操作流程(以阿里云为例):
 图片
图片
最佳实践:
- 设置策略:
- 保留7天快照
- 每4小时增量备份
- 误删后操作:
# 通过SDK创建临时实例
aliyun rds CloneInstance --DBInstanceId rm-xxxx
--BackupId 111111111
--PayType Postpaid三、恢复方案对比选型
方案 | 恢复粒度 | 时间窗口 | 复杂度 | 适用场景 |
Binlog日志恢复 | 行级 | 分钟级 | 中 | 小范围误删 |
延迟复制从库 | 库级 | 小时级 | 高 | 核心业务数据 |
全量+增量恢复 | 库级 | 小时级 | 高 | 整库丢失 |
Undo日志恢复 | 行级 | 秒级 | 极高 | 事务未提交 |
文件恢复 | 表级 | 不确定 | 极高 | DROP TABLE操作 |
云数据库快照 | 实例级 | 分钟级 | 低 | 云环境 |
四、如何预防误删数据的情况?
4.1 权限控制(事前预防)
核心原则:最小权限分配
-- 禁止开发直接操作生产库
REVOKEALLPRIVILEGESON *.* FROM'dev_user'@'%';
-- 只读账号配置
GRANTSELECTON app_db.* TO'read_user'@'%';
-- DML权限分离
CREATEROLE dml_role;
GRANTINSERT, UPDATE, DELETEON app_db.* TO dml_role;4.2 操作规范(事中拦截)
- SQL审核:所有DDL必须走工单
- 高危操作确认:执行DROP前二次确认
-- 危险操作示例
DROP TABLE IF EXISTS user_data; -- 必须添加IF EXISTS- WHERE条件检查:DELETE前先SELECT验证
4.3 备份策略(事后保障)
黄金备份法则:321原则
- 3份备份(本地+异地+离线)
- 2种介质(SSD+磁带)
- 1份离线存储
总结
下面给大家总了数据恢复的三要三不要。
三要:
- 要立即冻结现场:发现误删马上锁定数据库。
- 要优先使用Binlog:90%场景可通过日志恢复。
- 要定期演练恢复:每季度做恢复测试。
三不要:
- 不要心存侥幸:认为误删不会发生在自己身上。
- 不要盲目操作:恢复前先备份当前状态。
- 不要忽视监控:设置删除操作实时告警。
设计系统时,永远假设明天就会发生数据误删。
当灾难真正降临时,你会发现所有的预防措施都是值得的。









